Это вторая статья цикла анализ данных в python, первая статья была введением и ответами на общие вопросы, в том числе о необходимых приготовлениях.
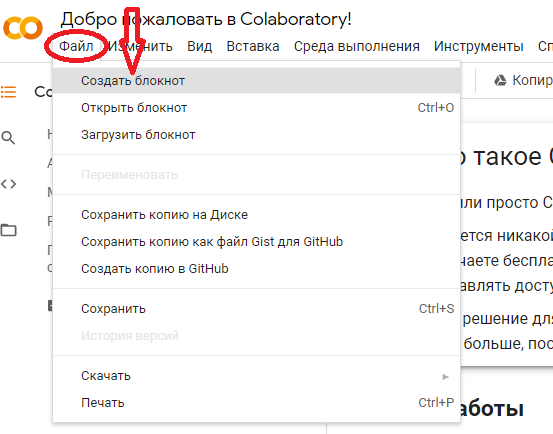
Запускаем браузер, заходим на colab, создаем новый блокнот. Можем сразу же переименовать, например, в FirstNote: Файл -> Переименовать. Сделаем еще одно действие в colab, а именно подключим Google-диск.
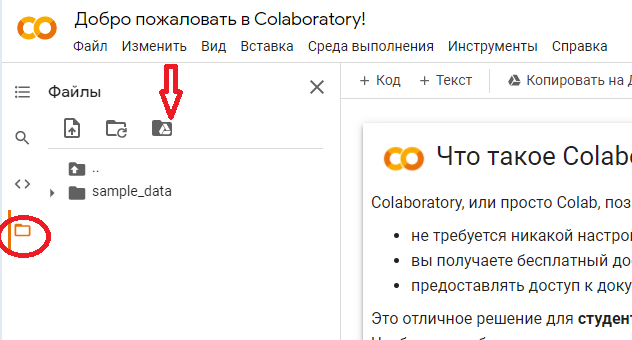
Это можно было бы сделать и позже, а можно вообще обойтись без этого, но мы предполагаем, что мы будем работать в colab дольше одной сессии, поэтому чтобы нужно где-то сохранить файл csv, который мы сформируем, а потом будем использовать уже в другом блокноте.
Для вашего удобства можно посмотреть исходный блокнот здесь. Но я вам рекомендую писать код самостоятельно, потому что так лучше запоминается и понимается. Когда копируешь чужой код, то мозг старается не вникать в то, что там написано.
Получение данных
Самое время написать первую строчку кода, а точнее комментарий, который поможет нам разобраться, что здесь написано. Комментарий можно сделать, добавив в начале строки символ решетки (Shift + F3).
# Объявление модулей
import pandas as pd
import numpy as np
import pandas_datareader as pdr
Вторая строчка импортирует модуль pandas, позволяя обращаться к нему с помощью ссылки pd. Пока просто запомните это как заклинание. Как вы уже догадались, третья строка импортирует библиотеку numpy, к которой мы будем обращаться с помощью алиаса np. С помощью четвертой строчки мы импортируем библиотеку, которая будет "читать" биржевые данные из различных источников, в том числе с Московской биржи. На Московской бирже есть интерфейс доступа к биржевым данным, который называется ISS. Вы можете скачать руководство разработчика, где детально описываются возможности этого интерфейса. Честно сказать, когда я первый раз прочитал этот документ, то я ничего не понял, пришлось разбираться с примерами, но сейчас мы эти неприятности обойдем используя библиотеку pandas_datareader.
Теперь научимся выполнять код, для этого достаточно нажать Ctrl+Enter или значок с треугольником слева. Если код выполнился без ошибок, то вы увидите зеленую галочку левее значка выполнения. Некоторые модули требуют установки в систему, например, для установки pandas и зависимых библиотек (numpy, pytz, python-dateutil, six) необходимо выполнить команду:
%pip install pandas
Если же у вас уже все было установлено, то ничего плохого не произойдет, но необходимости в последней команде не было. Colab позволяет разбивать код на отдельные участки, что позволяет вам независимо от других ячеек изменять и исполнять код. Мы так и поступим, для добавления новой кодовой ячейки ниже Меню Файл есть кнопка "+Код". В этой ячейке мы будем использовать строковые переменные, поэтому сделаем соответствующий комментарий, а потом присвоим переменной с именем beginDate значение '1999-06-29'.
# Объявление переменных
beginDate = '1999-06-29'
В этой переменной мы будем хранить строковое значение даты, начиная с которой нам нужно получить данные с биржи. Как определить эту дату, мы сейчас описывать не будем, чтобы не усложнять понимание реально важных вещей. Вот теперь мы напишем строчку, в которой будет использоваться псевдоним pdr, под которым скрывается библиотека pandas_datareader.
df = pdr.get_data_moex('USD000000TOD', start=beginDate)
Разберем эту строчку детально: df - переменная в которой будет храниться результат выполнения функции get_data_moex, которая имеется в библиотеке pandas_datareader, которая скрывается под псевдонимом pdr. В эту функцию мы должны передать код инструмента и еще ряд необязательных параметров, в нашем случае передается параметр start, которым задается начальная дата, с которой нужно получить данные. В качестве идентификатора мы передали странную строку: USD000000TOD. Так на Московской бирже закодирован инструмент USDRUB_TOD - USD/РУБ, информацию по которому вы можете получить здесь.
Мы только начали учиться, многое нам еще не понятно, поэтому некоторые вещи пока придется принимать на веру. Потом, наработав определенный опыт, придет и понимание того, что вы делаете. Пока же запоминайте как заклинание. Я уже знаю, что результатом выполнения функции будет датафрейм (поэтому и переменная названа df), чтобы посмотреть первые пять строк датафрейма необходимо ввести следующее заклинание:
df.head()
Вот теперь мы можем выполнить этот участок кода (Ctrl+Enter или значок с треугольником слева). Имейте в виду, что всех дольше будет выполняться функция get_data_moex - это нормально. Ниже кода появится результат, то есть первые пять записей датафрейма:
Для опытного исследователя тут уже есть определенная информация, но мы с вами должны обратить свое внимание на следующее: код выполнился без ошибок (следовательно вы все правильно написали), датафрейм содержит данные, причем с 29 июня 1999 года, у датафрейма есть 9 колонок (пока мы не знаем, что они обозначают).
Обработка данных
Нам будут интересны только 4 колонки: OPEN, LOW, HIGH, CLOSE. В некоторых случаях можно использовать еще и пятую - VOLRUR, но сейчас она нам не нужна. Эти 4 колонки содержат цены: открытия, минимум периода, максимум периода и закрытия. Опытные трейдеры тут же скажут, что наиболее значимая будет цена закрытия. Допустим, что мы этого не знаем. С чего мы должны начать анализ? С отбора значимых данных. Если нам нужны только 4 колонки, то их мы и должны оставить. Существует несколько вариантов как это сделать. Добавим новую ячейку с кодом (см. выше как это делать). Мы сейчас сделаем самым непонятным способом, его надо запомнить, потом мы поймем, что это означает:
df = df[['OPEN', 'HIGH', 'LOW', 'CLOSE']]
Тут мы присваиваем той же переменной новое значение в виде датафрейма, в котором используются только 4 колонки и, в добавок, они расположены в другом порядке (LOW и HIGH поменяли местами). Обратите также внимание на две открывающиеся квадратные скобки и на две закрывающиеся квадратные скобки. Результат вы можете увидеть уже известным вам способом, но мы с вами воспользуемся еще одной важной функцией датафрейма:
df.info()
Выполните код текущей ячейки, результатом выполнения будет следующий вывод:
Обратите внимание на различие количества элементов индекса и колонок: для индекса, максимума и минимума - 8902, а открытие и закрытие - 8891. Такие вещи должны вызывать у вас желание проверить все ли нормально в ваших данных. Даже подсчет в уме показывает, что строчек значительно больше: 20 с небольшим лет, в каждом годе приблизительно 250 торговых дней, итого должно быть в районе 5000 - 6000 записей, а их в 1,5 больше. К счастью, у нас есть мощные инструменты, чтобы не считать это в голове. Мы посчитаем количество уникальных индексов:
df.index.nunique()
Вывод показывает - 5607, что значительно меньше значения предыдущей функции. Это означает, что в один и тот же день у нас могут быть две и более записи. Это на самом деле так. Если вернуться к первоначальному виду датафрейма, то первой колонкой идет BOARDID, что содержит идентификатор режима торгов, а таких режимов может быть несколько за один день. Это очень интересная задача, но не для нашего уровня, в дальнейшем я рекомендую вернуться к ней, а пока нам нужно удалить лишние записи.
Но прежде вернитесь к пятой записи, выведенной функцией head, видите нулевые значения. Это неправильно, в предыдущих торгах значения были ненулевые, а в этот день стали нулевые. Нам надо все нулевые значения заменить на значение специального типа:
df.replace(0.0, np.nan, inplace=True)
У датафрейма есть функция replace, первым параметром которой надо указать искомое значение, а вторым - подставляемое. В качестве второго значения мы используем специальный тип, который определен в библиотеке numpy, которая имеет псевдоним np. На третий параметр стоит обратить особое внимание новичкам, потому что он встречается в целом ряде функций. Смысл его становится понятным, когда знаешь двойственную природу этих функций. Такие функции могут возвращать измененный датафрейм, тогда этот параметр принимает значение False, но мы не подставили в левой части переменную, которая будет ссылаться на измененный датафрейм, поэтому нам надо сделать изменения "на месте". По этой причине мы задаем значение True. Запомните, что если вы делаете какие-то изменения, а результат остается таким же, то возможно вы забыли указать параметр inplace=True.
Почему нам понадобился специальный тип вместо нулевых значений? Потому что в следующей команде мы будем удалять строчки, содержащие этот специальный тип:
df = df.dropna()
В этот раз мы используем первый вариант функций изменения данных, то есть переменной присваиваем ссылку на датафрейм с измененными данными, следовательно inplace=False. Но у нас этот параметр вообще не указан, это все потому, что это функция (как и многие другие) по умолчанию подставляет его как False, то есть его можно не указывать, когда нужен именно такой режим работы функции.
Давайте посмотрим на результат, для этого воспользуемся известной нам функцией info (если забыли смотрите выше) и выполним всю эту ячейку. Теперь количество индексов и ненулевых значений в колонках совпадает, но количество записей все равно превышает количество торговых дней. Следовательно нам нужно сбросить индекс:
df.reset_index(inplace=True)
Параметр inplace здесь должен быть вам понятен. Давайте посмотрим на результат, с помощью функции head (если забыли посмотрите выше). Теперь пятой строчкой идут значения за 6 июля. Также добавился вперед столбец TRADEDATE, который раньше был индексом.
Давайте заменим "кричащие" заглавные буквы "спокойными" прописными, да и первый столбец можно назвать просто date:
newCols = {'TRADEDATE': 'date',
'OPEN': 'open',
'HIGH': 'high',
'LOW': 'low',
'CLOSE': 'close'}
df.rename(columns=newCols, inplace=True)
Круглые скобки, квадратные скобки, а теперь еще и фигурные скобки. Как тут не запутаться? Либо вы запоминаете, где какие скобки используются, либо начинаете изучать массивы и словари в python. Нам же сейчас надо знать только то фигурными скобками отмечаются словари, а квадратными - массивы. Чем отличаются одни от других мы сейчас разбирать не будем. Кстати, функция rename имеет еще один вариант сделать тоже самое, но это мы тоже опустим.
Самое время сохранить изменения, сделанные в этом занятии, чтобы в следующем занятии не повторять все те же действия. Помните, я предлагал вам подключить гугл-диск. Вот сейчас он нам понадобится:
df.to_csv('/content/drive/MyDrive/usdrub.csv', index=False)
Прежде чем выполнять этот код, обратите внимание на следующую деталь: я назвал свой гугл-диск MyDrive. Вы могли его назвать по-другому. Чтобы не гадать, разверните в левой части каталог drive (если не видите, то вернитесь к началу статьи, где показано на картинке как подключить ваш гугл-диск), выделите каталог в который будете сохранять свои csv-файлы, щелкните по нему правой кнопкой мыши, а в контекстном меню выберите пункт "Скопировать путь". Название файла usdrub.csv можете оставить, а можете использовать свое. В следующем занятии вы будете загружать этот файл.