
Сервис Yandex Wordstat, как мы знаем, выдаёт статистику поисковых запросов, но многие не пользуются его возможностями в полном объёме или вовсе интерпретируют данные неверно. Как работают операторы статистики запросов вордстат, что из себя представляет удобный метод перемножения и для чего нужен анализ региональной популярности поисковых тем? Давайте разбираться.
Когда пользователь вбивает какое-то словосочетание в поиск вордстата и видит итоговое число запросов, то полагает, что это число — показатель того, сколько раз искали именно это сочетание слов. Однако на самом деле в эти данные входят ВСЕ пользовательские запросы, содержащие ваши слова.
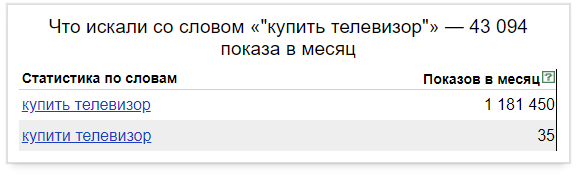
Предположим, вас интересует, продажа телевизоров. Запрашивая в поиске «купить телевизор», вы обнаружите результат в 977 891 показов в месяц и решите, что 977 891 раз люди интересовались исключительно покупкой телевизора. Но в это количество также могут (и более того — обязательно будут) входить другие запросы, которые никакого отношения к вам, как продавцу телевизоров, не имеют. Например, «купить антенну+для телевизора» искали 16 027 раз, а «купить пульт+для телевизора» - 43 358 и т.д.
Как получить чистую информацию по конкретному запросу?
Для этого используется такой оператор, как кавычки: ставим их в начале и в конце словосочетания и получаем реальный спрос.
Сравните:
А что делать, если вас интересует определённая форма слова?
Например, вы продаёте товар оптом, и нужно оценить результаты именно по множественному числу. Для вордстата и «телевизор» и «телевизоры» звучат одинаково. Но если поставить перед запросом восклицательный знак, то статистика будет уже по той форме слова, которую вы выбрали.
Следующий оператор оптимизирует анализ поиска по вопросительным информационным запросам, содержащим предлоги, союзы и другие служебные части речи.
Если нужна информация о частоте поиска по запросу «как снимать видео на телефон», то используются следующие операторы.
«+» для фиксации служебных частей речи, «!» для каждой словоформы и кавычки для связи всех слов.
Готовый запрос будет выглядеть так:
Таким образом, можно проследить реальный спрос на какую-либо услугу в любой нише и определить потенциал её рентабельности.
Помимо форм слов, зачастую важную роль играет ещё и их порядок. Например, при поиске авиабилетов. Согласитесь, рейсы «Москва–Ростов» и «Ростов–Москва» — буквально противоположные события, хотя для вордстата не имеют никакой разницы.
Как указать конкретный порядок слов в Yandex Wordstat?
Используем оператор квадратных скобок
Следующий оператор используется для перемножения и составления семантического ядра. Для чего это может быть полезно? Когда есть несколько групп слов, каждая из которых синонимична внутри себя.
Например, нас интересует отдых на Черноморском побережье. К нему относятся санатории, профилактории, отдых по путёвкам в таких городах, как, например, Сочи, Анапа, Геленджик. Очевидно, что города относятся к одной семантической группе, а места и формы отдыха — к другой. Поэтому мы каждую берём в круглые скобки, а между самими словами ставим вертикальный слэш. Получаем:
Таким образом, система перемножает каждое слово из первой группы с каждым из второй, и мы получаем готовые подборки разных запросов по степени популярности. Без использования подобного способа мы бы потратили гораздо больше времени на сбор тех же данных, но вручную и по каждому запросу отдельно.
Для ещё большей автоматизации перемножения специалисты используют парсинговые программы, но для быстроты и простоты первичного анализа хватит и подобного метода.
Выводы
Итак, для работы с вордстатом используются специальные операторы:
Для уточнения конкретного запроса — кавычки <">
Для уточнения формы слова — восклицательный знак <!>
Для предложений, содержащих служебные части речи — плюс <+>
Для указания порядка слов — квадратные скобки <[ ]>
Для перемножения и составления семантического ядра — круглые скобки и вертикальный слэш <( )> <|>