Рассмотрим неприятную задачу подмены значений в прогнозах, вызванную изменениями в первоначальных условиях использования модели машинного обучения. В реальной жизни время от времени такое происходит и надо быть к этому готовым.
Рассмотрим вопрос на примере системы предсказаний потребления объектами товаров. Сгенерируем синтетические данные (использованные приемы описаны ранее):
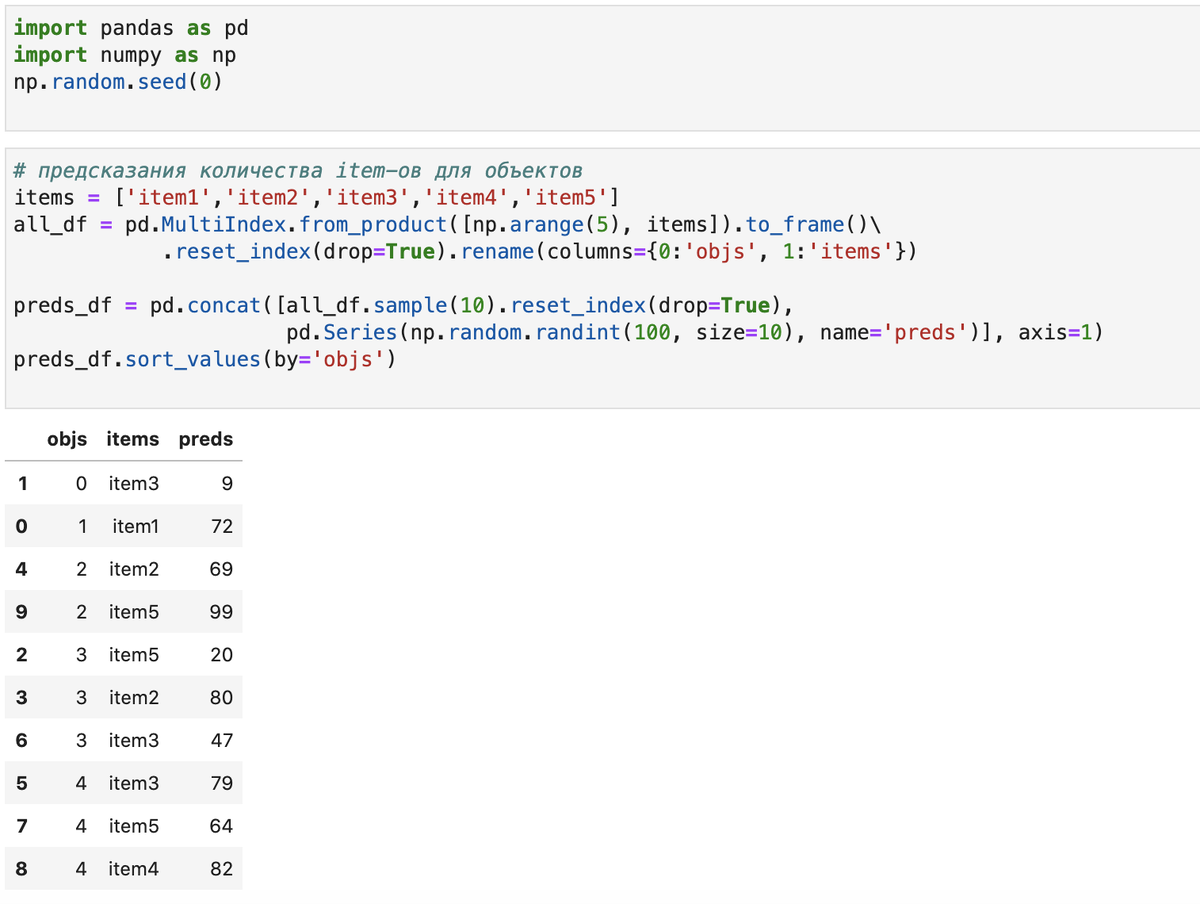
objs, items задают пары объектов и товаров, для которых мы делаем предсказания. Подмена так же осуществляется для пары, например, филиал организации использовал картриджи двух типов, а теперь только одного.
Правила замены определяются исходя из перечня имеющихся на obj item-ов (например, всех используемых в филиале товаров, зададим в obj_items_df) и словаря замены (например, вместо item1 - item2 /шариковые -> гелевые ручки, зададим в maps_d):
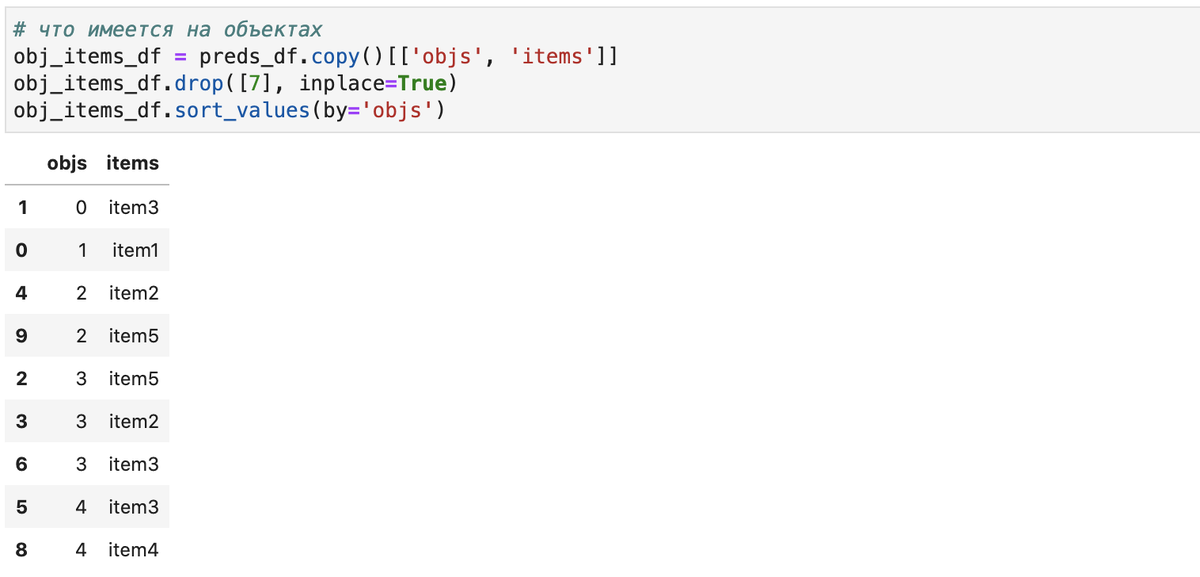
Отмечу, что к описанной логике замены, базирующейся на перечне всех имеющихся на объектах товаров, можно перейти, имея список отсутствующих номенклатур, следующим образом:
Теперь перейдем к функции подмены - change_items. Ее логика предполагает фильтрацию и замену значений на уровне индексов Pandas, так как этот способ работает быстрее других (детальнее рассказывал ранее). Код функции описан ниже:
Ниже представлены результаты ее работы:
Теперь может понадобиться агрегировать прогнозы с повторяющимися item-ми (например, прогнозировали картриджи двух типов, а теперь используется только один, соответственно, и количество потребуется просуммировать):