Apache Kafka - это система обмена сообщениями с открытым исходным кодом, которая была создана в LinkedIn примерно в 2011 году. Она обеспечивает быстрый, хорошо масштабируемый и надежный обмен сообщениями по модели pub-sub. Kafka допускает большое количество клиентов, отличается высокой доступностью, устойчивостью к сбоям узлов и поддерживает автоматическое восстановление.
Почему Apache Kafka так популярна?
- Масштабируемость. Apache Kafka имеет распределенную архитектуру, обрабатывающую входящие сообщения с большим объемом и скоростью. Как результат - Kafka обладает высокой масштабируемостью без каких-либо простоев.
- Высокая пропускная способность. Apache Kafka может обрабатывать миллионы сообщений в секунду. Сообщения, поступающие в большом объеме или с высокой скоростью не влияют на производительность.
- Низкая задержка. Kafka обеспечивает очень низкую задержку передачи, которая составляет около десяти миллисекунд.
- Отказоустойчивость. Используя механизм репликации, Kafka обрабатывает сбои на узлах кластера без потери данных.
- Надежность. Apache Kafka - это распределенная платформа с очень высокой отказоустойчивостью, что делает ее очень надежной в использовании системой.
- Сохранность данных. Реплики данных, хранящихся в кластере Kafka, распределены по разным серверам, при падении или сбое одного сервера копии остаются на других..
- Обработка данных в реальном времени.
Архитектура Apache Kafka
Рассмотрим архитектуру Apache Kafka и взаимосвязь между различными архитектурными компонентами, чтобы точнее понять Kafka для распределенной потоковой передачи.
Компоненты Apache Kafka и ее архитектурные концепции:
Topic
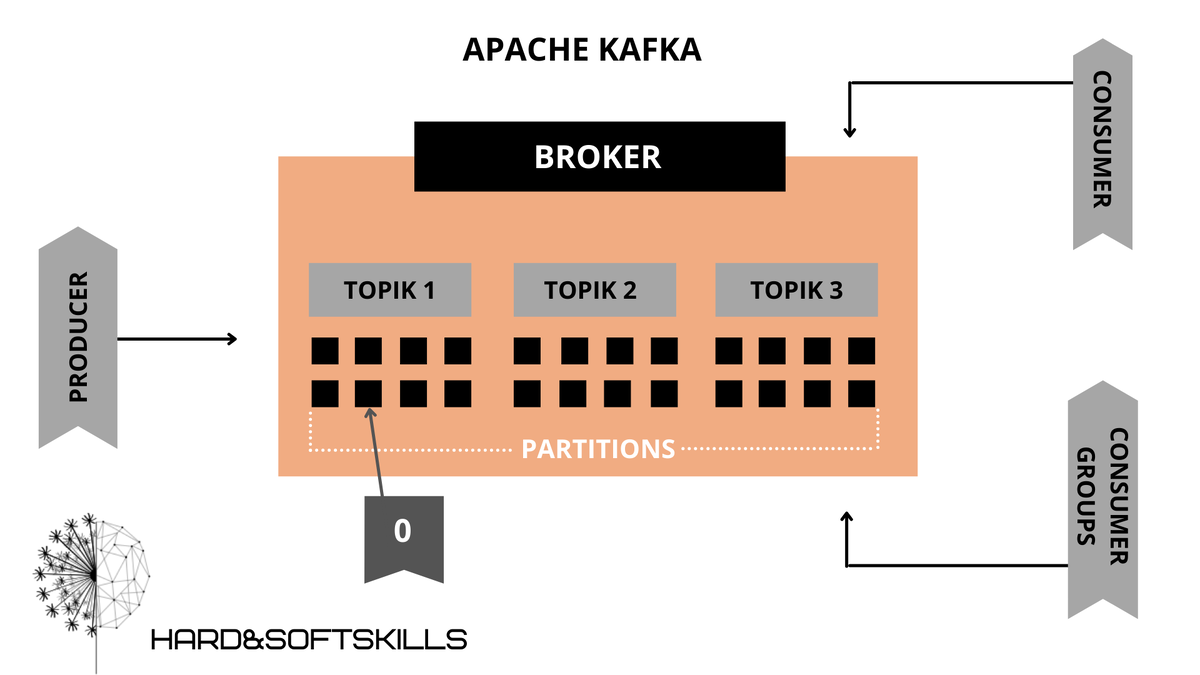
Поток сообщений, который является частью определенной категории или названия канала, называется топиком Kafka. В Kafka данные хранятся в виде топиков. Producer записывают свои данные в топик, а consumer читает данные из этого топика.
Broker
Кластер Kafka состоит из одного или нескольких серверов, известных как брокеры. В Kafka брокер работает как контейнер, который может содержать несколько топиков с разными partitions. Уникальный ID используется для идентификации брокера в кластере Kafka. Подключение к любому из брокеров Kafka в кластере подразумевает подключение ко всему кластеру.
Producer
Producers в Kafka публикует сообщения в одном или нескольких топиков. Они отправляют данные в кластер Kafka.
Consumer and Consumer Group
Consumers читает данные из кластера Kafka. Данные, которые должны быть прочитаны Consumers, получаются от брокера. Consumer group в Kafka объединяет несколько consumers, таким образом, что каждый consumer читает часть сообщений определенного топика.
Partition
Топик в Kafka разделен на настраиваемое количество частей, которые называются partitions. Partition разделяет топик по нескольким брокерам, таким образом снижая нагрузку на каждый отдельный сервер. Consumers могут быть объединены в consumer group, и тогда один сonsumer может получать сообщения не из всего топика, а только из некоторых его partitions, что обеспечивает распределение нагрузки на обработку сообщений.
Partition Offset
Сообщения или записи в Kafka относятся к partition, каждой записи присваивается число - offset, чтобы определить положение в partition. Запись идентифицируется в своем partition с помощью значения offset. Offset partition имеет значение только для этого конкретного partition. Для старых записей будут меньшие значения offset, поскольку записи добавляются в конец partition.
Replicas
Реплики похожи на резервную копию partition в Kafka. Используется для предотвращения потери данных в случае сбоя или планового отключения и размещаются на нескольких серверах в кластере Kafka.
Недостатки Apache Kafka
Хотя Kafka и является очень популярной системой обмена сообщениями, у нее есть и свои недостатки:
- Изменение сообщений внутри Kafka не предусмотрено и приводит к проблемам с производительностью. Kafka хорошо подходит только для случаев, когда сообщение не нужно менять.
- В Kafka нет поддержки выбора топика по регулярным выражениям. Название топика должно быть точным (в отличие от RabbitMQ, например).
- Некоторые парадигмы передачи сообщений, такие как p2p очереди и request/response сообщения не поддерживаются Kafka.
- Для больших сообщений требуется сжатие и распаковка сообщений. Это влияет на пропускную способность и производительность Kafka.
Сравнение различных брокеров сообщений (сравнения Redis, Kafka, RabbitMQ)
Какой брокер когда лучше использовать?
Мы рассмотрели некоторые характеристики RabbitMQ, Kafka и Redis. Все трое устроены и работают совершенно по-разному. Вот наша рекомендация по выбору правильного брокера сообщений в зависимости от различных сценариев использования.
Сообщения с коротким временем жизни: Redis
In-memory база данных Redis почти идеально подходит для передачи сообщений, которые не требуется сохранять на диск. Redis чрезвычайно быстро обрабатывает сообщения в памяти и поэтому является идеальным кандидатом для сообщений с маленьким временем жизни, когда можно позволить себе потерять некоторое количество данных.
Большие объемы данных: Kafka
Kafka - это распределенная очередь с высокой пропускной способностью, созданная для хранения и передачи большого количества данных в течение длительных периодов времени.
Сложная маршрутизация: RabbitMQ
RabbitMQ - более старый и зрелый брокер с множеством функций и возможностей, поддерживающий сложную маршрутизацию. Он способен поддерживать сложную маршрутизацию, даже при высокой скорости передачи сообщений (больше нескольких десятков тысяч сообщений в секунду).
Технологический стек проекта
Также нужно учитывать ваш текущий стек проекта. Если вы ищете относительно простой процесс интеграции, то не стоит добавлять еще одну очередь сообщений в проект, лучше использовать ту что уже есть.
Например, если вы используете Celery для очереди задач в своей системе поверх RabbitMQ, у вам будет проще работать с RabbitMQ, а не с Kafka, которую еще придется ставить и настраивать.