В реальности возникают ситуации, когда необходимо адаптировать прогнозы моделей машинного обучения для новых условий, например, для работы на подгруппах из первоначальных объектов. В этой статье я расскажу, как сделать это без переобучения модели.
Будем считать, что мы можем найти некий признак, характеризующий пропорциональную связь между подгруппами одного объекта. Это, например, может быть прогноз другой модели, адаптированной в отличие от заданной для предсказания на более мелких единицах, или некая другая мера (например, численность сотрудников организации и ее филиалов в случае предсказания потребления товаров). Тогда можно распределить прогноз заданной модели равномерно на подобъекты в соответствии с их соотношением.
Рассмотрим пример. Пусть имеется матрица из идентификаторов объектов, их групп и прогнозов альтернативной модели:
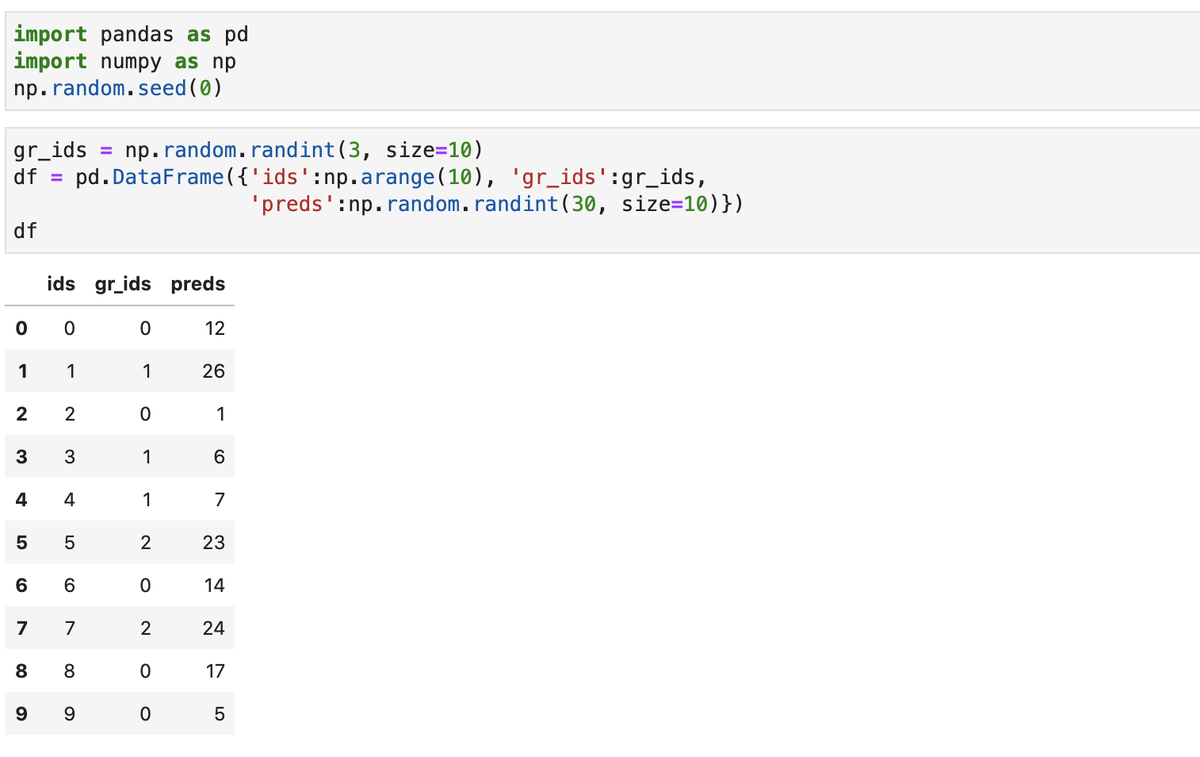
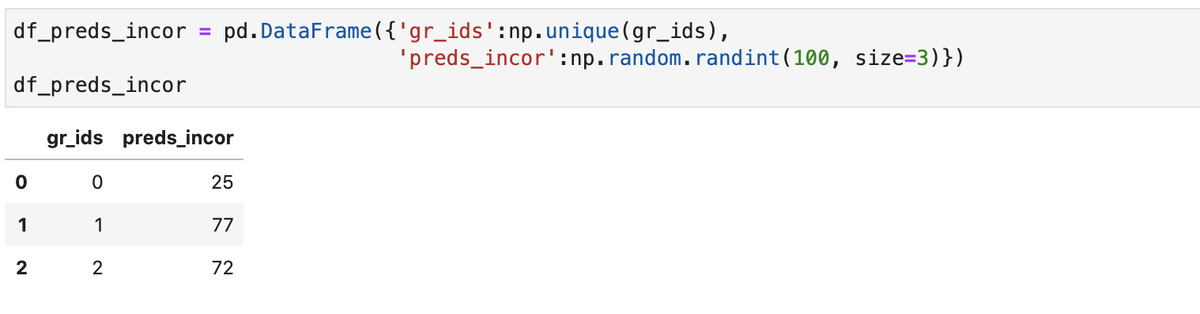
Также мы располагаем датафреймом с прогнозами заданной модели, рассчитанной для работы только на больших группах объектов:
Объединим датафреймы:
Далее пишем функцию для пропорционального распределения прогнозов и применяем ее к нашему столбцу preds_incor:
В результате получаем столбец со скорректированными прогнозами. Для сверки можно сджойнить его с исходной матрицей: