За пределами Физической Памяти: Политики
В менеджере виртуальной памяти жизнь легка, когда у вас много свободной памяти. Происходит page fault, вы находите свободную страницу в списке свободных страниц, и назначаете её в ответ на ошибку. Хей, Операционная Система! Поздравляю, ты сделала это снова.
К сожалению всё становится сложнее когда в вашем распоряжении небольшое количество свободной памяти. В таком случае, эти силы давления памяти (this memory pressure forces) заставляют ОС выгружать страницы (paging out), освобождая место для чаще используемых страниц. Принятие решения о том, какую страницу выселять (evict) основывается на политике замены (replacement policy) хранящейся в ОС; исторически сложилось так, что это было одно из самых важных решений, принятых при проектировании систем виртуальной памяти, поскольку в старых системах было мало физической памяти. Как минимум, это интересный набор политик, о которых стоит узнать немного больше. И, следовательно, наша проблема:
ПРОБЛЕМА: КАК РЕШИТЬ, КАКУЮ СТРАНИЦУ ВЫГРУЖАТЬ
Как ОС может решить, какую страницу (или страницы) удалить из памяти? Это решение принимается в соответствии с политикой замены настроенной в системе, которая обычно следует некоторым общим принципам (обсуждаемым ниже), но также включает определенные настройки, позволяющие обрабатывать крайние случаи.
Cache Management
До погружения в политики, мы для начала детально опишем проблему которую пытаемся решить. Учитывая, что основная память содержит некоторое подмножество всех страниц в системе, ее по праву можно рассматривать как кэш для страниц виртуальной памяти в системе. В работе с ним наша цель заключается в выборе такой политики замены, которая позволит минимизировать кол-во срабатываний cache misses, другими словами минимизировать кол-во обращений к диску в попытке прочитать с него страницу памяти. Иначе можно сказать, что мы пытаемся максимизировать обращения к кешу, т.е. увеличить кол-во раз когда страница находится в памяти.
Зная количество cache hits и cache misses, можно рассчитать среднее время доступа к памяти (AMAT) для программы (показатель, вычисляемый компьютерными архитекторами для аппаратных кэшей [HP06]). Зная эти данные мы можем вычислить AMAT по следующей формуле:
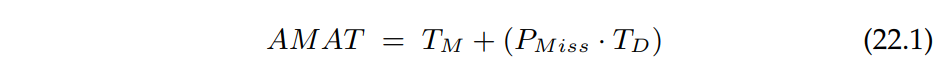
где Тм - цена доступа к памяти, Тd - цена доступа к диску и Pmiss - вероятность не найти страницу в кеше (cache miss); Pmiss варьируется от 0.0 до 1.0 и иногда мы ссылаемся на процент промахов вместо вероятности (т.е. 10% miss rate - это Pmiss = 0.1). Всегда есть цена за доступ к памяти но при срабатывании cache miss, вы дополнительно платите за доступ к диску.
Например, представим машину с маленьким адресным пространством: 4КВ, с 256-ьайтными страницами. Виртуальный адрес содержит два компонента: 4-битный VPN (наиболее значимые биты) и 8-битное смещение (наименее значимые биты). Таким образом, процесс из примера может получить доступ всего к 16 (2 в 4 степени) виртуальным страницам. В данном примере процесс генерирует следующие ссылки в памяти (виртуальные адреса): 0x000, 0x100, 0x200, 0x300, 0x400, 0x500, 0x600, 0x700, 0x800, 0x900. Эти виртуальные адреса ссылаются на первый байт каждой из первых десяти страниц адресного пространства (номер страницы это первое шестнадцатеричное число каждого виртуального адреса).
Предположим что каждая страница, кроме виртуальной страницы 3, уже в памяти. Последовательный доступ к памяти в таком случае приведёт к следующим событиям: hit, hit, hit, miss, hit, hit, hit, hit, hit, hit. Мы можем вычислить hit rate (процент от запросов которые нашли запрашиваемую страницу в кеше): 90%, как 9 из 10 страниц оказались в памяти. Miss rate равен 10% (Pmiss = 0.1). В общем случае Phit + Pmiss = 1.0; hit rate + miss rate = 100%.
Чтобы вычислить AMAT, нужно знать цену доступа к памяти и цену доступа к диску. Предполагая, что цена доступа к памяти (Tm) равна 100 наносекунд а цена доступа к диску (Td) около 10 миллисекунд получим AMAT: 100ns + 0.1 * 10ms = 100ns + 1ms или 1.0001 ms или около 1 миллисекунды. Если hit rate будет равен 99.9% (Pmiss = 0.001), результат немного отличается: AMAT = 10.1 микросекунд, что грубо в 100 раз быстрее. Если hit rate достигнет 100%, AMAT достигнет 100 наносекунд.
К сожалению, как можно видеть в примере, цена доступа к диску настолько велика, в современных системах, что даже маленьких miss rate будет оказывать большое влияние на AMAT запущенных программ. Очевидно, что нам нужно избегать как можно большего количества промахов или работать медленно, со скоростью диска. Единственный путь достичь этого - это разработать умную политику, чем и займёмся.
Оптимальная политика замены
Чтобы лучше понять, как работает конкретная политика замены, было бы неплохо сравнить ее с наилучшей возможной политикой замены. Как оказалось, такая оптимальная политика была разработана Belady много лет назад [B66] (первоначально он называл ее MIN). Оптимальная политика замены приводит к наименьшему количеству промахов в целом. Belady показал, что простой (но, к сожалению, сложный в реализации!) подход, который заменяет страницу, доступ к которой будет в будущем позднее всего (furthest in the future), является оптимальной политикой, приводящей к наименьшему количеству возможных пропусков кэша.
СРАВНЕНИЕ С ОПТИМАЛЬНЫМ ПОЛЕЗНО
Хотя оптимальность не очень практична в качестве реальной политики, она невероятно полезна в качестве точки сравнения при моделировании или других исследованиях. Утверждение о том, что ваш модный новый алгоритм имеет 80% - ную скорость попадания, не имеет смысла изолированно; утверждение, что оптимальный достигает 82% - ной скорости попадания (и, следовательно, ваш новый подход довольно близок к оптимальному), делает результат более значимым и придает ему контекст. Таким образом, в любом исследовании, которое вы проводите, знание того, что является оптимальным, позволяет вам провести лучшее сравнение, показывая, насколько еще возможно улучшение, а также когда вы можете перестать улучшать свою политику, потому что она достаточно близка к идеалу [AD03].
Надеюсь, интуиция, лежащая в основе оптимальной политики, имеет смысл. Подумайте об этом так: если вам нужно выбросить какую-то страницу, почему бы не выбросить ту, которая нужна дальше всего от этого момента? Поступая таким образом, вы, по сути, говорите, что все остальные страницы в кэше важнее, чем самая удаленная. Причина, по которой это так, проста: вы будете ссылаться на другие страницы, прежде чем перейдете к самой дальней.
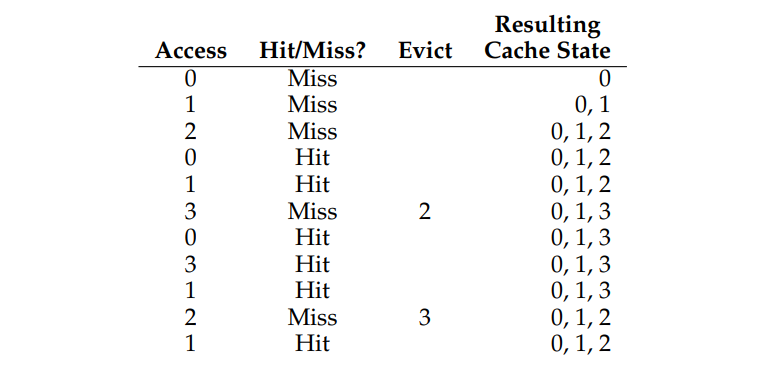
Давайте проследим на простом примере, чтобы понять, какие решения принимает оптимальная политика. Предположим, что программа обращается к следующему потоку виртуальных страниц: 0, 1, 2, 0, 1, 3, 0, 3, 1, 2, 1. На рисунке 22.1 показано поведение optimal, если предположить, что кэш вмещает три страницы.
На рисунке вы можете увидеть следующие действия. Неудивительно, что первые три доступа являются пропусками, так как кэш начинается в пустом состоянии; такой промах иногда называют пропуском холодного запуска (cold-start miss) (или принудительным пропуском - compulsory miss). Затем мы снова обратимся к страницам 0 и 1 и сработает cache hit. Наконец, мы достигаем еще cache miss (на странице 3), но на этот раз кэш заполнен; должна произойти замена! В связи с этим возникает вопрос: какую страницу мы должны заменить? С помощью оптимальной политики мы изучаем будущее для каждой страницы, находящейся в данный момент в кэше (0, 1 и 2), и видим, что доступ к 0 осуществляется почти сразу, к 1 - чуть позже, а к 2 - дальше всего в будущем. Таким образом, оптимальная политика имеет простой выбор: удалить страницу 2, в результате чего страницы 0, 1 и 3 окажутся в кэше.
ТИПЫ ПРОПУСКОВ КЭША
В мире компьютерной архитектуры архитекторы иногда считают полезным классифицировать пропуски по типу в одну из трех категорий: обязательные (compulsory), пропуски по мощности (capacity) и конфликтные пропуски (conflict), иногда называемые Тремя C (Three C’s) [H87]. Обязательный промах (compulsory miss или промах при холодном запуске (cold-start miss) [EF78]) возникает из-за того, что кэш изначально пуст, и это первая ссылка на элемент; напротив, capacity miss возникает из-за того, что в кэше не хватило места и пришлось удалить элемент, чтобы внести новый элемент в кэш. Третий тип промаха (конфликтный промах - conflict miss) возникает в аппаратном обеспечении из-за ограничений на то, где элемент может быть помещен в аппаратный кэш, из-за чего-то, известного как setassociativity; он не возникает в кэше страниц ОС, потому что такие кэши всегда полностью ассоциативны (fully-associative), т. е. нет ограничений на то, где в памяти может быть размещена страница. Подробности см. в разделе H&P [HP06].
Следующие три обращения к памяти вызывают cache hit, но затем мы переходим на страницу 2, которую мы давно удалили, и терпим еще один промах. Здесь оптимальная политика снова исследует будущее для каждой страницы в кэше (0, 1 и 3) и видит, что до тех пор, пока она не удалит страницу 1 (к которой скоро будет доступ), все будет в порядке. В примере показано, как страница 3 выгружается, хотя 0 тоже был бы хорошим выбором. Наконец, мы ловим cache hit для страницы 1, и трассировка завершается.
Мы также можем рассчитать частоту попаданий в кэш: при 6 попаданиях и 5 промахах частота попаданий равна Hits / (Hits + Misses) или 6 / (6 + 5) или 54,5% Вы также можете вычислить hit rate по модулю обязательных пропусков (т. е. игнорируя первый промах на данной странице), и получить 85,7% hit rate.
К сожалению, как мы видели ранее при разработке политик планирования, будущее в целом неизвестно; вы не можете построить оптимальную политику для операционной системы общего назначения*. Таким образом, при разработке реальной, развертываемой политики мы сосредоточимся на подходах, которые найдут какой-то другой способ решить, какую страницу удалить. Таким образом, оптимальная политика будет служить лишь точкой сравнения, чтобы знать, насколько мы близки к “совершенству”.
*Если вы можете, дайте нам знать! Мы можем разбогатеть вместе. Или, стать как ученые, которые “открыли” холодный термоядерный синтез, и широко презирались и высмеивались [FP89].
Простая политика: FIFO
Многие ранние системы избегали сложных попыток приблизиться к оптимальной и использовали очень простые стратегии замены. Например, некоторые системы использовали замену FIFO (first in, first out), когда страницы просто помещались в очередь при входе в систему; когда происходит замена, страница в конце очереди (страница “first in") удаляется. У FIFO есть одно большое преимущество: он довольно прост в реализации.
Давайте рассмотрим, как работает FIFO в нашем примере потока ссылок на память (рис. 22.2). Мы снова начинаем наш обход с трех обязательных промахов на страницах 0, 1 и 2, а затем срабатывает cache hit как на 0, так и на 1. Далее доступ к странице 3 вызывает cache miss; решение о замене страницы при использовании FIFO простое: выбрать страницу которая пришла в очередь первой (состояние кеша на рисунке отображено в порядке FIFO, с первой страницей вверху списка access), в нашем случае это страница 0. К сожалению, наш следующий доступ к странице 0, вызывает cache miss и замену (страницы 1). Затем hit на странице 3, но miss на 1 и 2 и наконец hit на 3.
Сравнивая FIFO с оптимальной политикой, FIFO заметно хуже: hit rate 36.4% (или 57.1% исключая compulsory misses). FIFO просто не может определить важность блоков: даже если страница 0 будет запрашиваться несколько раз, FIFO просто заменяет её, просто потому что она первой попала в память.
Аномалия Белади
Belady (автор оптимальной политики) и коллеги обнаружили интересный ссылочный поток, который вел себя немного неожиданно [BNS69]. Поток ссылок на память: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5. Политика замены, которую они изучали, была FIFO. Интересная часть: как изменилась частота попадания в кэш при переходе с размера кэша от 3 до 4 страниц.
В общем, вы ожидаете, что частота попадания в кэш увеличится (улучшится), когда кэш станет больше. Но в данном случае, с FIFO, все становится еще хуже! Подсчитайте попадания и промахи сами и посмотрите. Это странное поведение обычно называют аномалией Белади (к огорчению его соавторов).
Некоторые другие политики, такие как LRU, не страдают от такой проблемы. Можете предположить почему? Как оказалось, LRU обладает так называемым свойством стека [M+70]. Для алгоритмов с этим свойством кэш размером N + 1 естественным образом включает содержимое кэша размером N. Таким образом, при увеличении размера кэша частота попаданий либо останется прежней, либо улучшится. FIFO и Random (среди прочих) явно не подчиняются свойству стека и, следовательно, подвержены аномальному поведению.
Другая простая политика: Random
Другая похожая политика - Random, которая просто выбирает случайную страницу для замены под давлением памяти. Random имеет свойства схожие с FIFO; её просто реализовать, но она не пытается быть интеллектуальной в выборе блоков для выселения. Давайте взглянем на то как Random работает на нашем знаменитом примере ссылочного потока (Рисунок 22.3).
Конечно, то как работает Random зависит от того насколько везучей (или невезучей) Random окажется при выборе. В примере выше, Random работает немного лучше FIFO, и немного хуже оптимальной политики. Фактически мы можем запустить эксперимент с Random тысячи раз и определить как она работает в общем случае. Рисунок 22.4 изображает то как много cache hits можно достичь применяя Random после 10 000 попыток, каждая с разным случайным выбором. Как вы можете, иногда (около 40% времени), Random хорош также как оптимальная политика, достигая 6 hits в тестах; иногда он работает намного хуже, достигая 2 попаданий или меньше. Результат политики зависит от удачи.
Используя Историю: LRU
К сожалению, любая политика, такая простая как FIFO или Random имеет общую проблему: она может выгрузить важную страницу, ту на которую могут ссылаться в следующий момент. FIFO выгружает страницу которая поступила первой; если это страница с важным кодом или структурами данных её всё равно выгружают даже если будут скоро загружать. Таким образом простые политики FIFO, Random и похожие не достигают оптимального поведения; нужно что-то более интеллектуальное.
Так же как с политикой планирования (scheduling policy), для улучшения ситуации в будущем, мы снова обращаемся в прошлое и используем историю в качестве проводника. Например, если программа обращалась к странице в ближайшем прошлом, скорее всего к ней нужен будет доступ в ближайшем будущем.
Одним из видов исторической информации, которую может использовать политика замены страниц, является частота; если к странице обращались много раз, возможно, ее не следует заменять, поскольку она явно имеет некоторую ценность. Более часто используемым свойством страницы является ее недавнее время доступа; чем позже был получен доступ к странице, тем, возможно, более вероятно, что к ней снова будут обращаться. Это семейство политик основано на том, что люди называют принципом локальности [D70], который в основном представляет собой просто наблюдение за программами и их поведением. Этот принцип довольно просто гласит, что программы, как правило, довольно часто обращаются к определенным кодовым последовательностям (например, в цикле) и структурам данных (например, массиву, к которому обращается цикл); поэтому мы должны попытаться использовать историю, чтобы выяснить, какие страницы важны, и сохранить эти страницы в памяти, когда дело доходит до времени удаления.
И таким образом, рождается семейство простых исторически обоснованных алгоритмов. Least-Frequently-Used политика (LFU) заменяет наименее часто используемую страницу, когда должна произойти замена. Аналогично, политика Least-Recently-Used (LRU) заменяет наиболее долго неиспользованную страницу. Эти алгоритмы легко запомнить: как только вы знаете имя, вы точно знаете, что оно делает, что является отличным свойством для имени.
Чтобы лучше понять LRU, давайте рассмотрим, как LRU работает на нашем примере ссылочного потока.
Типы локальности
Есть два типа локальности, которые, как правило, демонстрируют программы. Первый известен как пространственная локальность, которая гласит, что при доступе к странице P, скорее всего, также будут доступны страницы вокруг нее (напр. P − 1 или P + 1). Второй-это временная локальность, которая гласит, что страницы, к которым обращались в ближайшем прошлом, скорее всего, будут доступны снова в ближайшем будущем. Предположение о наличии этих типов локальности играет большую роль в иерархиях кэширования аппаратных систем, которые развертывают многоуровневое кэширование команд, данных и преобразования адресов, чтобы помочь программам работать быстро, когда такая локальность существует. Конечно, принцип локальности, как его часто называют, не является жестким и быстрым правилом, которому должны подчиняться все программы. Действительно, некоторые программы обращаются к памяти (или диску) довольно случайным образом и не проявляют какой-либо локальности в своих потоках доступа. Таким образом, хотя локальность-это хорошая вещь, которую следует иметь в виду при разработке кэшей любого рода (аппаратных или программных), это не гарантирует успеха. Скорее, это эвристика, которая часто оказывается полезной при проектировании компьютерных систем.
Рисунок 22.5 показывает результат. Из рисунка, вы можете увидеть как LRU может использовать историю чтобы работать лучше чем политики без хранения состояния, такие как Random или FIFO. В примере, LRU выгружает страницу 2 когда нужно заменить страницу в первый раз, потому что 0 и 1 опрашиваются чаще. Затем политика заменит страницу 0 т.к. 1 и 3 опрашиваются чаще. В обоих случаях, решение LRU, основанное на истории, оказывается корректным, и при доступе к следующим ссылкам срабатывает hit. Таким образом, в нашем примере, LRU работает так хорошо как это возможно, давая оптимальные доступы к памяти при своей производительности*.
*ОК, мы подогнали результат. Но иногда подгонка нужна для того чтобы доказать что-то
Мы также должны отметить, что существуют противоположности этих алгоритмов: Most-Frequently-Used (MFU) и Most-Recently-Used (MRU). В большинстве случаев (не во всех!!!), эти политики не работают хорошо, поскольку они игнорируют локальность, которую демонстрирует большинство программ, вместо того, чтобы обработать ее.
Примеры рабочей нагрузки
Давайте рассмотрим еще несколько примеров, чтобы лучше понять, как ведут себя некоторые из этих политик. Здесь мы рассмотрим более сложные рабочие нагрузки вместо небольших трассировок. Однако даже эти рабочие нагрузки значительно упрощены; лучшее исследование включало бы трассировку приложений.
Наша первая рабочая нагрузка не имеет локальности, что означает, что каждая ссылка относится к случайной странице в наборе доступных страниц. В этом простом примере рабочая нагрузка получает доступ к 100 уникальным страницам с течением времени, выбирая следующую страницу для ссылки случайным образом; в целом доступно 10 000 страниц. В эксперименте мы варьируем размер кэша от очень маленького (1 страница) до достаточного для хранения всех уникальных страниц (100 страниц), чтобы увидеть, как каждая политика ведет себя в диапазоне размеров кэша.
На рисунке 22.6 показаны результаты эксперимента для optimal, LRU, Random и FIFO. Ось y на рисунке показывает частоту обращений, которую достигает каждая политика; ось x изменяет размер кэша, как описано выше. Из графика мы можем сделать ряд выводов. Во-первых, когда в рабочей нагрузке отсутствует локальность, не имеет большого значения, какую реалистичную политику вы используете; LRU, FIFO и Random выполняют одно и то же, при этом частота попаданий точно определяется размером кэша. Во-вторых, когда кэш достаточно велик, чтобы вместить всю рабочую нагрузку, также не имеет значения, какую политику вы используете; все политики (даже случайные) сходятся к 100% - ной частоте попадания, когда все указанные блоки помещаются в кэш. Наконец, вы можете видеть, что optimal работает заметно лучше, чем реалистичные политики; предсказание будущего, если бы это было возможно, намного лучше справляется с заменой.
Следующая рабочая нагрузка, которую мы исследуем, называется рабочей нагрузкой “80-20”, которая отражает локальность: 80% ссылок сделаны на 20% страниц (“горячие” страницы); остальные 20% ссылок сделаны на оставшиеся 80% страниц (“холодные” страницы). В нашей рабочей нагрузке снова насчитывается в общей сложности 100 уникальных страниц; таким образом, “горячие” страницы упоминаются большую часть времени, а “холодные” страницы-в остальное время. На рисунке 22.7 показано, как политики работают с этой рабочей нагрузкой. Как вы можете видеть из рисунка, в то время как и random, и FIFO работают достаточно хорошо, LRU работает лучше, так как у него больше шансов удержаться на горячих страницах; поскольку на эти страницы часто ссылались в прошлом, они, вероятно, будут ссылаться снова в ближайшем будущем. Оптимальная политика снова лучше, показывая, что историческая информация LRU не идеальна.
Теперь вы можете задаться вопросом: действительно ли улучшение LRU по сравнению с Random и FIFO настолько важно? Ответ, как обычно, таков: “Это зависит от обстоятельств”. Если каждый промах обходится очень дорого (не редкость), то даже небольшое увеличение частоты попаданий (снижение частоты промахов) может оказать огромное влияние на производительность. Если промахи не так дороги, то, конечно, преимущества, возможные с помощью LRU, не так важны.
Давайте рассмотрим одну заключительную рабочую нагрузку. Мы называем это “циклической последовательной” рабочей нагрузкой, так как в ней мы последовательно обращаемся к 50 страницам, начиная с 0, затем 1,..., до страницы 49, а затем повторяем цикл, повторяя эти обращения, в общей сложности 10 000 обращений к 50 уникальным страницам. Последний график на рис. 22.8 показывает поведение политик при данной рабочей нагрузке.
Эта рабочая нагрузка, распространенная во многих приложениях (включая важные коммерческие приложения, такие как базы данных [CD 85]), представляет собой худший случай как для LRU, так и для FIFO. Эти алгоритмы при циклической рабочей нагрузке выгружают старые страницы; к сожалению, из-за циклического характера рабочей нагрузки эти старые страницы будут доступны раньше, чем страницы, которые политики предпочитают хранить в кэше. Действительно, даже с кэшем размером 49, циклически последовательная рабочая нагрузка в 50 страниц приводит к 0%-ному попаданию. Интересно, что случайные тарифы заметно лучше, не совсем приближаясь к оптимальным, но, по крайней мере, достигая ненулевой скорости попадания. Оказывается, у random есть некоторые приятные свойства; одним из таких свойств является отсутствие странного поведения в угловых случаях.
Реализация исторических алгоритмов
Как вы можете видеть, такой алгоритм, как LRU, обычно может выполнять лучшую работу, чем более простые политики, такие как FIFO или Random, которые могут выбрасывать важные страницы. К сожалению, историческая политика ставит перед нами новую задачу: как мы ее реализуем?
Давайте возьмем, к примеру, LRU. Чтобы реализовать его идеально, нам нужно проделать большую работу. В частности, при каждом доступе к странице (т. е. При каждом доступе к памяти, будь то извлечение инструкций, загрузка или хранение) мы должны обновлять некоторую структуру данных, чтобы переместить эту страницу в начало списка (т. е. на сторону MRU). Сравните это с FIFO, где список страниц FIFO доступен только при удалении страницы (путем удаления первой страницы) или при добавлении новой страницы в список (на стороне последнего входа). Чтобы отслеживать, какие страницы использовались меньше всего - и чаще всего-в последнее время, система должна выполнять некоторую работу по учету каждой ссылки на память. Очевидно, что без особой тщательности такой учет может значительно снизить производительность.
Один из способов, который может помочь ускорить это, - добавить немного аппаратной поддержки. Например, машина может обновлять при каждом доступе к странице поле времени в памяти (например, это может быть в таблице страниц для каждого процесса или просто в каком-то отдельном массиве в памяти, с одной записью на физическую страницу системы). Таким образом, при доступе к странице поле времени будет установлено аппаратно на текущее время. Затем, при замене страницы, ОС может просто сканировать все поля времени в системе, чтобы найти наименее недавно использованную страницу.
К сожалению, по мере роста количества страниц в системе сканирование огромного количества раз только для того, чтобы найти абсолютно наименее недавно использованную страницу, обходится непомерно дорого. Представьте себе современную машину с 4 ГБ памяти, разделенную на 4 КБ страниц. На этой машине 1 миллион страниц, и поэтому поиск страницы LRU займет много времени, даже при современных скоростях процессора. Возникает вопрос: действительно ли нам нужно найти самую старую страницу для замены? Можем ли мы вместо этого выжить используя приближение?
КАК РЕАЛИЗОВАТЬ ПОЛИТИКУ ЗАМЕНЫ LRU
Учитывая, что реализовать идеальный LRU будет дорого, можем ли мы каким-то образом приблизить его и все же получить желаемое поведение?
Аппроксимация LRU
Как оказалось, ответ "да": аппроксимация LRU более осуществима с точки зрения вычислительных затрат, и действительно, это то, что делают многие современные системы. Идея требует некоторой аппаратной поддержки в виде use bit (иногда называемого эталонным битом), первый из которых был реализован в первой системе с подкачкой, одноуровневом хранилище Atlas [KE+62]. Существует один use bit на страницу системы, и use bits которые находятся где-то в памяти (они могут быть, например, в таблицах страниц для каждого процесса или просто где-то в массиве). Всякий раз, когда на страницу ссылаются (т. е. читают или записывают), бит использования аппаратно устанавливается равным 1. Аппаратное обеспечение никогда не очищает бит ( хоть и устанавливает его в 0); это ответственность операционной системы.
Как ОС использует use bit для аппроксимации LRU? Ну, может быть много способов, но с алгоритмом синхронизации [C69] был предложен один простой подход. Представьте, что все страницы системы расположены в виде на циферблате часов. Стрелка часов указывает на какую-то конкретную страницу для начала (на самом деле не имеет значения, на какую). Когда должна произойти замена, ОС проверяет, имеет ли бит использования, на который в данный момент указывает страница P, значение 1 или 0. Если 1, это означает, что страница P использовалась недавно и, следовательно, не является подходящим кандидатом на замену. Таким образом, бит использования для P устанавливается равным 0 (очищается), а стрелка часов увеличивается до следующей страницы (P + 1). Алгоритм продолжается до тех пор, пока не найдет бит использования, равный 0, что означает, что эта страница не использовалась в последнее время (или, в худшем случае, что все страницы были использованы и что мы провели поиск по всему набору страниц, очистив все биты).
Обратите внимание, что этот подход-не единственный способ использовать use bit для аппроксимации LRU. Действительно, любой подход, который периодически очищает use bit, а затем различает, какие страницы имеют use bit в значении 1 или 0, чтобы решить, что заменить, был бы хорош. Тактовый алгоритм Корбато был всего лишь одним из ранних подходов, который увенчался некоторым успехом, и обладал приятным свойством не сканировать повторно всю память в поисках неиспользуемой страницы.
Поведение варианта тактового алгоритма показано на рисунке 22.9. Этот вариант случайным образом сканирует страницы при замене; когда он встречает страницу с эталонным битом, равным 1, он очищает бит (т. е. Устанавливает его в 0); когда он находит страницу с эталонным битом, равным 0, он выбирает ее в качестве своей жертвы. Как вы можете видеть, хотя он работает не так хорошо, как идеальный LRU, он работает лучше, чем подходы, которые вообще не учитывают историю.
Considering Dirty Pages
Одна небольшая модификация алгоритма синхронизации (также первоначально предложенная Корбато [C69]), заключается в дополнительном уточнении того, была ли страница изменена или нет, находясь в памяти. Если это так то её необходимо записать обратно на диск, чтобы удалить, а это дорого. Если она не была изменена (и, следовательно, она clean), выгрузка является бесплатной; физический фрейм можно просто повторно использовать для других целей без дополнительного ввода-вывода. Таким образом, некоторые виртуальные машины предпочитают удалять чистые страницы вместо грязных страниц.
Для поддержки такого поведения аппаратное обеспечение должно включать модифицированный бит (он же грязный бит). Этот бит устанавливается каждый раз при написании страницы и, таким образом, может быть включен в алгоритм замены страницы. Алгоритм синхронизации, например, можно изменить, чтобы сначала сканировать неиспользуемые и чистые страницы для удаления; если их не удается найти, затем для неиспользуемых страниц, которые являются грязными, и так далее. Алгоритм синхронизации, например, можно изменить, чтобы сначала сканировать неиспользуемые и чистые страницы для удаления; если их не удается найти, затем для неиспользуемых страниц, которые являются грязными, и так далее.
Другие политики VM
Замена страниц-не единственная политика, используемая подсистемой виртуальной машины (хотя она может быть самой важной). Например, операционная система также должна решить, когда переносить страницу в память. Эта политика, иногда называемая политикой выбора страницы (как ее назвал Деннинг [D70]), предоставляет ОС несколько различных опций.
Для большинства страниц ОС просто использует подкачку по запросу, что означает, что ОС переносит страницу в память при обращении к ней, так сказать, “по требованию". Конечно, ОС может догадаться, что страница будет использована, и, таким образом, выгрузить её заранее; такое поведение известно как предварительная выборка и должно выполняться только при наличии разумных шансов на успех. Другая политика определяет, как ОС записывает страницы на диск. Конечно, их можно было бы просто записывать по одному за раз; однако многие системы вместо этого собирают несколько ожидающих операций записи вместе в памяти и записывают их на диск за одну (более эффективную) запись. Такое поведение обычно называют кластеризацией или просто группировкой операций записи, и оно эффективно из-за природы дисководов, которые выполняют одну большую запись более эффективно, чем множество мелких.
Другая политика определяет, как ОС записывает страницы на диск. Конечно, их можно было бы просто записывать по одному за раз; однако многие системы вместо этого собирают несколько ожидающих операций записи вместе в памяти и записывают их на диск за одну (более эффективную) запись. Такое поведение обычно называют кластеризацией или просто группировкой операций записи, и оно эффективно из-за природы дисководов, которые выполняют одну большую запись более эффективно, чем множество мелких.
Thrashing
Прежде чем завершить, мы рассмотрим последний вопрос: что должна делать ОС, когда объем памяти просто превышен, а требования к памяти для набора запущенных процессов просто превышают доступную физическую память? В этом случае система будет постоянно выполнять подкачку, состояние, которое иногда называют trashing [D70].
Некоторые более ранние операционные системы имели довольно сложный набор механизмов как для обнаружения trashing'a, так и для борьбы с ним, когда он происходил. Например, имея множество процессов, система может принять решение не запускать подмножество процессов в надежде, что сокращенный набор рабочих процессов (страницы, которые они активно используют) поместится в памяти и, таким образом, сможет добиться прогресса. Этот подход, широко известный как контроль допуска (admission control), гласит, что иногда лучше делать меньше работы хорошо, чем пытаться делать все сразу плохо, с чем мы часто сталкиваемся в реальной жизни, а также в современных компьютерных системах (к сожалению).
Некоторые современные системы используют более драконовский подход к перегрузке памяти. Например, некоторые версии Linux запускают убийцу нехватки памяти (out-of-memory killer), когда объем памяти превышен; этот демон выбирает процесс, требующий большого объема памяти, и убивает его, тем самым сокращая объем памяти не слишком тонким способом. Несмотря на успех в снижении нагрузки на память, этот подход может привести к проблемам, если, например, он уничтожит X-сервер и, таким образом, сделает любые приложения, требующие дисплей, непригодными для использования.
Выводы
Мы видели внедрение ряда политик замены, которые являются частью подсистемы виртуальных машин всех современных операционных систем. Современные системы добавляют некоторые настройки к простым аппроксимациям LRU, такие как clock алгоритм; например, сопротивление сканированию (scan resistance) является важной частью многих современных алгоритмов, таких как ARC [MM03]. Алгоритмы, устойчивые к сканированию, обычно похожи на LRU, но также стараются избегать наихудшего поведения LRU, которое мы видели при циклически-последовательной рабочей нагрузке. Таким образом, эволюция алгоритмов замены страниц продолжается.
Однако во многих случаях важность указанных алгоритмов снизилась, поскольку увеличилось расхождение между временем доступа к памяти и временем доступа к диску. Поскольку подкачка на диск обходится очень дорого, стоимость частой подкачки непомерно высока. Таким образом, лучшим решением проблемы чрезмерной подкачки часто является простое (хотя и интеллектуально неудовлетворительное) решение: купить больше памяти.
Ссылки
[AD03] “Run-Time Adaptation in River” by Remzi H. Arpaci-Dusseau. ACM TOCS, 21:1, February 2003. A summary of one of the authors’ dissertation work on a system named River, where he learned that comparison against the ideal is an important technique for system designers
[B66] “A Study of Replacement Algorithms for Virtual-Storage Computer” by Laszlo A. Belady. IBM Systems Journal 5(2): 78-101, 1966. The paper that introduces the simple way to compute the optimal behavior of a policy (the MIN algorithm).
[BNS69] “An Anomaly in Space-time Characteristics of Certain Programs Running in a Paging Machine” by L. A. Belady, R. A. Nelson, G. S. Shedler. Communications of the ACM, 12:6, June 1969. Introduction of the little sequence of memory references known as Belady’s Anomaly. How do Nelson and Shedler feel about this name, we wonder?
[CD85] “An Evaluation of Buffer Management Strategies for Relational Database Systems” by Hong-Tai Chou, David J. DeWitt. VLDB ’85, Stockholm, Sweden, August 1985. A famous database paper on the different buffering strategies you should use under a number of common database access patterns. The more general lesson: if you know something about a workload, you can tailor policies to do better than the general-purpose ones usually found in the OS.
[C69] “A Paging Experiment with the Multics System” by F.J. Corbato. Included in a Festschrift published in honor of Prof. P.M. Morse. MIT Press, Cambridge, MA, 1969. The original (and hard to find!) reference to the clock algorithm, though not the first usage of a use bit. Thanks to H. Balakrishnan of MIT for digging up this paper for us.
[D70] “Virtual Memory” by Peter J. Denning. Computing Surveys, Vol. 2, No. 3, September 1970. Denning’s early and famous survey on virtual memory systems.
[EF78] “Cold-start vs. Warm-start Miss Ratios” by Malcolm C. Easton, Ronald Fagin. Communications of the ACM, 21:10, October 1978. A good discussion of cold- vs. warm-start misses.
[FP89] “Electrochemically Induced Nuclear Fusion of Deuterium” by Martin Fleischmann, Stanley Pons. Journal of Electroanalytical Chemistry, Volume 26, Number 2, Part 1, April, 1989. The famous paper that would have revolutionized the world in providing an easy way to generate nearly-infinite power from jars of water with a little metal in them. Unfortunately, the results published (and widely publicized) by Pons and Fleischmann were impossible to reproduce, and thus these two well-meaning scientists were discredited (and certainly, mocked). The only guy really happy about this result was Marvin Hawkins, whose name was left off this paper even though he participated in the work, thus avoiding association with one of the biggest scientific goofs of the 20th century.
[HP06] “Computer Architecture: A Quantitative Approach” by John Hennessy and David Patterson. Morgan-Kaufmann, 2006. A marvelous book about computer architecture. Read it!
[H87] “Aspects of Cache Memory and Instruction Buffer Performance” by Mark D. Hill. Ph.D. Dissertation, U.C. Berkeley, 1987. Mark Hill, in his dissertation work, introduced the Three C’s, which later gained wide popularity with its inclusion in H&P [HP06]. The quote from therein: “I have found it useful to partition misses ... into three components intuitively based on the cause of the misses (page 49).”
[KE+62] “One-level Storage System” by T. Kilburn, D.B.G. Edwards, M.J. Lanigan, F.H. Sumner. IRE Trans. EC-11:2, 1962. Although Atlas had a use bit, it only had a very small number of pages, and thus the scanning of the use bits in large memories was not a problem the authors solved
[M+70] “Evaluation Techniques for Storage Hierarchies” by R. L. Mattson, J. Gecsei, D. R. Slutz, I. L. Traiger. IBM Systems Journal, Volume 9:2, 1970. A paper that is mostly about how to simulate cache hierarchies efficiently; certainly a classic in that regard, as well for its excellent discussion of some of the properties of various replacement algorithms. Can you figure out why the stack property might be useful for simulating a lot of different-sized caches at once?
[MM03] “ARC: A Self-Tuning, Low Overhead Replacement Cache” by Nimrod Megiddo and Dharmendra S. Modha. FAST 2003, February 2003, San Jose, California. An excellent modern paper about replacement algorithms, which includes a new policy, ARC, that is now used in some systems. Recognized in 2014 as a “Test of Time” award winner by the storage systems community at the FAST ’14 conference.