
Первая половина компьютера
Давайте построим что-нибудь из деталей, которые у нас уже есть. Фактически, мы уже можем построить половину компьютера.
Для начала, представьте себе библиотеку, в который расположен один огромный стеллаж с ячейками, и размер стеллажа 16х16 ячеек. В каждой ячейке одна книга. Когда библиотекарю нужно достать определённую книгу, он должен точно знать, где она находится, поэтому на столе у него есть список, где напротив названия каждой книги указан ряд и столбец стеллажа. Так же организована память в компьютере. У каждого регистра есть свой уникальный адрес.
Теперь давайте построим нечто подобное из уже знакомых нам устройств.
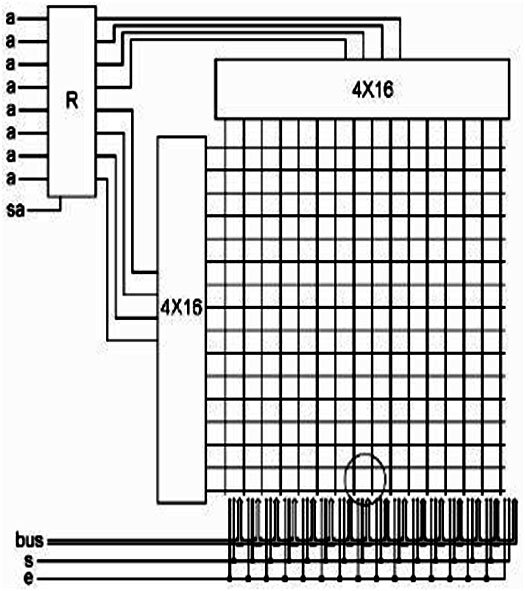
В нижней части схемы мы можем видеть шину данных и контакты ‘s’ и ’e’, которые подключены к каждому регистру. При таком масштабе не видно, как именно устроена коммутация регистров с шиной и дешифраторами. Поэтому, обратите внимание на кружок в нижней части сетки адресов, прямо на пересечении линий адресации. На самом деле в каждом из 256 пересечений есть три логических элемента ИС и один регистр.
В каждом пересечении один элемент И «x» подключен одним входом к вертикальной линии, а вторым к горизонтальной. Именно этот элемент и отвечает за то, чтобы память «понимала» к какому именно байту будет обращение. Ещё два элемента И подключены одним входом к выходу И «x», а вторым входом к ‘s’ и ‘e’ («установить» и «разрешить») проводам соответственно. При поступлении адреса на дешифраторы, 1 появляется только на одной вертикальной и одной горизонтальной линии адреса. Поэтому только один из 256 элементов И «x» сработает и выдаст на выходе 1. И поэтому сигналы «установить» и «разрешить» смогут дойти только до одного конкретного регистра.
А что происходит на остальных 255 регистрах? А ничего. Так как на входы остальных элементов И «x» приходит либо 0/0 либо 0/1 либо 1/0, а согласно таблицы истинности для И, на выходе во всех этих случаях будет 0. Поэтому на один из входов оставшихся двух элементов И приходит 0, а это так же означает, что вне зависимости от состояния ‘s’ и ‘e’, на выходе этих элементов будет 0 и регистр ничего не выдаст на шину и ничего не примет с неё.
Это и есть основной вид памяти компьютера. И это, в самом деле, половина компьютера. В таком виде памяти можно мгновенно получить доступ к любому регистру, вне зависимости от адреса предыдущего и последующего запроса. Любой регистр в любой момент времени мы можем прочесть или записать, затратив на это одинаковое количество времени. Отсюда и название «RAM» (англ. Random Access Memory – память с произвольным доступом). Это оперативная память. Она использует 257 регистров. 256 ячеек памяти и ещё один регистр используется для выбора адреса хранения байта, и называется этот 257-й регистр – «Memory Access Register» или «MAR» (англ. Регистр доступа к памяти). Теперь, по традиции, мы можем упростить схему RAM памяти:
На самом деле 256 байт – это очень мало. Для настоящего компьютера вам понадобилось бы куда больше. Например, если добавить ещё один регистр адреса, т.е. декодеры внутри будут 8х256, это даст нам сетку с 65 536 байт или 64кБ. Только посмотрите на эту сетку!
Так как шина передаёт по одному байту за раз, то здесь нам придётся выставить на шине сначала вертикальный адрес, кратковременно включить ‘s0’, затем выставить на шине горизонтальный адрес, кратковременно включить ‘s1’, и только потом читать или записывать байт. Конечно же, можно рисовать такую память в упрощённом виде:
Далее мы будем использовать память на 256 байт. Если вам понадобится компьютер с большим объёмом памяти, помните, что для этого нужно просто добавить ещё один адресный байт со всеми вытекающими.
Числа
Вернёмся ненадолго к кодам. Ранее мы уже познакомились с системой ASCII и кодировкой некоторых букв. Теперь взгляните на кодировку десяти цифр:
Это очень полезный код, так как не все компьютеры работают с текстами. Для других задач существуют свои специальные коды. Когда вы имеете дело с ASCII, любой байт может содержать код одной из 10 цифр от 0 до 9. Соответственно, чтобы написать число, состоящее из нескольких цифр, нам понадобится несколько байт. Но есть и более «экономный» код, в котором каждому состоянию байта соответствует одно число от 0 до 255. Это, можно сказать, более естественный код для компьютера, который и используется для счёта. Далее мы часто будем пользоваться именно этим кодом.
Этот код легко понять, ведь каждому биту в этом коде присвоено своё значение и чтобы написать определённое число, просто включите биты, сумма которых даёт это число.
В любой системе исчисления есть две основные вещи: список символов и способ использования этих символов. Вероятно, самая простая система
Tally Marks. Она состоит всего из двух символов «|» и «/». Первые четыре раза вы пишете «|», а в пятый раз «/». Далее всё повторяется заново.
Далее мы будем делать с числами нечто, что может сбить вас с толку. Поэтому для простоты понимания мы рассмотрим старую систему.
Все ведь знают римскую систему исчисления? Цифры в ней обозначаются буквами I - 1, V - 5, X - 10, C - 100, M - 1000. С одной стороны, она не такая уж сложная: если меньшая цифра справа от большей, то прибавляй, а если слева – отнимай. С другой же стороны числа в данной системе не так очевидны на первый взгляд. Например, перед вами два числа MCMXCIX и MM. При первом взгляде и не сразу скажешь, какое из них больше, не правда ли? Это 1999 и 2000. В привычной нам десятичной системе исчисления сравнивать числа куда проще, мы понимаем это даже на интуитивном уровне.
Например, что означает число 256? Это два раза по 100, пять раз по 10 и ещё 6. В школе нам говорят, что в нашей системе десять цифр потому, что у нас десять пальцев. А что, если бы систему исчисления придумали ленивцы, у которых на руках всего по три пальца? Такая система была бы шестиричной, а счёт выглядел бы так: 0, 1, 2, 3, 4, 5, 10. Если бы у нас было восемь яблок, то как бы их посчитали ленивцы? Сначала они досчитали бы до пяти, а что дальше? Дальше была бы полная «шесть» и справа от неё счёт бы начался сначала. Наши восемь яблок на «ленивецком» выглядели бы как 12, Ведь 8 это один раз по 6 и ещё 2. Соответственно, если у нас будет 15 яблок, то в «шестиричной» системе это будет 2 раза по шесть и ещё 3, т.е. 23. А как насчёт 35 яблок? Это 5 раз по шесть и ещё 5. А вот 36 – это уже шесть раз по шесть и это так же как и десять по десять означает, что пора явиться следующему разряду. То есть 36 яблок в системе ленивцев мы запишем как 100.
На первый взгляд, это какая-то странная система. Но на самом деле, в повседневной жизни, мы уже пользуемся ещё более странной системой. Как насчёт исчисления времени?
Здесь вообще одновременно несколько систем исчисления. Так что помимо десятичной системы, вам всегда были известны и другие, просто вы об этом не задумывались.
Теперь давайте поговорим ещё об одной системе исчисления. Байт состоит из восьми бит, а адрес байта из 16 бит. Писать адрес из шестнадцати нулей и единиц довольно утомительно каждый раз, да и ошибиться легко. Но что если мы опять всё упростим? Давайте рассмотрим шестнадцатиричную систему исчисления. В ней всё довольно просто. Начинается всё, так же как и в десятичной системе, с нуля «0». Далее идут цифры 1, 2, 3 и т.д. до 9. Но что делать дальше, символов то должно быть 16? И тут первооткрыватели не стали придумывать ничего нового: они просто обозначили оставшиеся цифры буквами. Ниже наглядно представлены от одного до двадцати в десятичной (Dec), шестнадцатиричной (Hex) и бинарной (Bin) системах:
Вы заметили, как удобно для нас совпадают значения в Hex и Binсистемах? F - это ведь как раз полубайт! Соответственно 255 (Dec) = FF (Hex) = 1111 1111 (Bin).
Адреса
Теперь у нас есть бинарный код, который мы можем использовать для различных целей в своём компьютере. Одно из мест, где этот код используется – это регистр адреса памяти (MAR). Код из битов в этом регистре соответствует адресу одной из 256 ячеек RAM. Адрес в памяти компьютера – это просто номер одной из ячеек памяти.
Часть 3 - Назад Далее - Часть 5
#компьютеры #наука и техника #образование #Электроника #радиолюбитель #процессор