За пределами Физической памяти: Механизмы
До сих пор мы предполагали, что адресное пространство нереально мало и помещается в физическую память. Фактически, мы предполагали, что каждое адресное пространство каждого запущенного процесса помещается в память. Теперь мы ослабим эти большие предположения и предположим, что мы хотим поддерживать множество одновременно работающих больших адресных пространств.
Для этого нам требуется дополнительный уровень в иерархии памяти. До сих пор мы предполагали, что все страницы находятся в физической памяти. Однако для поддержки больших адресных пространств операционной системе потребуется место для хранения частей адресных пространств, которые в настоящее время не пользуются большим спросом. В общем, характеристики такого местоположения заключаются в том, что оно должно обладать большей емкостью, чем память; в результате оно обычно работает медленнее (если бы оно было быстрее, мы бы просто использовали его в качестве памяти, верно?). В современных системах эту роль обычно выполняет жесткий диск. Таким образом, в нашей иерархии памяти большие и медленные жесткие диски находятся внизу, а память-чуть выше. И таким образом мы подходим к сути проблемы:
СУТЬ: КАК ВЫЙТИ ЗА РАМКИ ФИЗИЧЕСКОЙ ПАМЯТИ
Как ОС может использовать более крупное и медленное устройство, чтобы прозрачно создать иллюзию большого виртуального адресного пространства?
У вас может возникнуть один вопрос: почему мы хотим поддерживать одно большое адресное пространство для процесса? Еще раз, ответ - удобство и простота использования. При большом адресном пространстве вам не нужно беспокоиться о том, достаточно ли места в памяти для структур данных вашей программы; вы просто пишете программу естественным образом, выделяя память по мере необходимости. Это мощная иллюзия, которую обеспечивает операционная система, и она значительно упрощает вашу жизнь. Не за что! Контраст обнаруживается в старых системах, в которых использовались наложения памяти, что требовало от программистов вручную перемещать фрагменты кода или данных в память и из нее по мере необходимости [D97]. Попробуйте представить, как это было бы: перед вызовом функции или доступом к некоторым данным вам нужно сначала сделать так, чтобы код или данные находились в памяти; фу!
ТЕХНОЛОГИИ ХРАНЕНИЯ
Позже мы гораздо глубже рассмотрим, как на самом деле работают устройства ввода-вывода (см. главу об устройствах ввода-вывода). Так что наберитесь терпения! И, конечно, более медленное устройство не обязательно должно быть жестким диском, но может быть чем-то более современным, например твердотельным накопителем на основе флэш-памяти. Об этом мы тоже поговорим. А пока просто предположим, что у нас есть большое и относительно медленное устройство, которое мы можем использовать, чтобы создать иллюзию очень большой виртуальной памяти, даже больше, чем сама физическая память.
Помимо одного процесса, добавление пространства подкачки позволяет операционной системе поддерживать иллюзию большой виртуальной памяти для нескольких одновременно выполняемых процессов. Изобретение мультипрограммирования (запуск нескольких программ “одновременно”, чтобы лучше использовать машину) почти что продиктовало необходимость подкачки некоторых страниц, так как ранние машины явно не могли вместить все страницы, необходимые для всех процессов одновременно. Таким образом, сочетание многопрограммности и простоты использования приводит к тому, что мы хотим поддерживать использование большего объема памяти, чем физически доступно. Это то, что делают все современные виртуальные машины; теперь мы узнаем об этом больше.
Пространство подкачки
Первое, что нам нужно будет сделать, это зарезервировать немного места на диске для перемещения страниц туда и обратно. В операционных системах мы обычно называем такое пространство пространством подкачки (swap space), потому что мы перемещаем (swap) в него страницы из памяти и перемещаем (swap) страницы в память из него. Таким образом, мы просто предположим, что ОС может считывать и записывать данные в пространство подкачки равными порциями каждая из которых равна размеру страницы. Для этого операционной системе необходимо будет запомнить адрес записи на диске для данной страницы.
Размер пространства подкачки важен, так как в конечном счете он определяет максимальное количество страниц памяти, которые могут использоваться системой в данный момент времени. Давайте для простоты предположим, что на данный момент он очень велик.
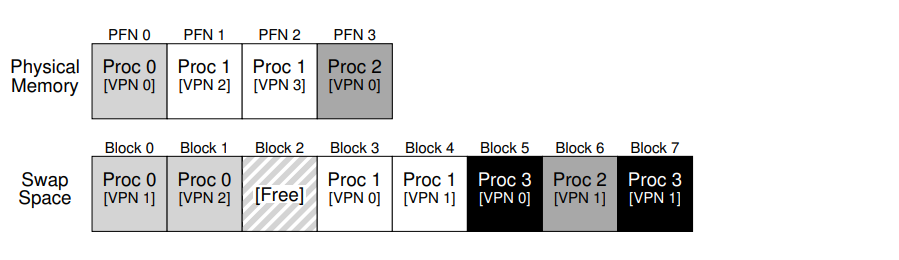
В крошечном примере (рис. 21.1) вы можете увидеть небольшой пример 4-страничной физической памяти и 8-страничного пространства подкачки. В примере три процесса (Proc 0, Proc 1 и Proc 2) активно используют общую физическую память; однако у каждого из трех в памяти есть только некоторые из их допустимых страниц, а остальные находятся в пространстве подкачки на диске. Четвертый процесс (Proc 3) имеет все свои страницы, перенесенные на диск, и, следовательно, явно не выполняется в данный момент. Один блок обмена остается свободным. Даже из этого крошечного примера, надеюсь, вы сможете увидеть, как использование пространства подкачки позволяет системе притворяться, что память больше, чем она есть на самом деле.
Следует отметить, что пространство подкачки - не единственное место на диске для обмена трафиком. Например, предположим, что вы запускаете двоичный файл программы (например, ls или вашу собственную скомпилированную основную программу). Кодовые страницы из этого двоичного файла изначально находятся на диске, и при запуске программы они загружаются в память (либо все сразу, когда программа начинает выполнение, либо, как в современных системах, по одной странице за раз, когда это необходимо). Однако, если системе необходимо освободить место в физической памяти для других нужд, она может безопасно повторно использовать пространство памяти для этих кодовых страниц, зная, что позже она может снова поменять их местами из двоичного файла на диске в файловой системе.
Present Bit
Теперь, когда у нас есть немного места на диске, нам нужно добавить некоторые механизмы выше в системе, чтобы поддерживать обмен страницами на диск и с диска. Давайте для простоты предположим, что у нас есть система с аппаратно-управляемым TLB.
Сначала вспомните, что происходит при обращении к памяти. Запущенный процесс генерирует ссылки на виртуальную память (для выборки команд или доступа к данным), и в этом случае аппаратное обеспечение преобразует их в физические адреса перед извлечением требуемых данных из памяти.
Помните, что аппаратное обеспечение сначала извлекает VPN из виртуального адреса, проверяет TLB на соответствие (TLB hit) и, если сопоставление найдено (TLB hit), создает результирующий физический адрес и извлекает его из памяти. Надеюсь, это распространенный случай, так как он быстрый (не требует дополнительного доступа к памяти).
Если VPN не найден в TLB (TLB miss), оборудование находит таблицу страниц в памяти (используя базовый регистр таблицы страниц) и ищет запись таблицы страниц (PTE) для этой страницы, используя VPN в качестве индекса. Если страница валидна и присутствует в физической памяти, аппаратное обеспечение извлекает PFN из PTE, устанавливает его в TLB и повторяет инструкцию, на этот раз генерируя TLB hit; пока все хорошо.
Однако, если мы хотим разрешить swap страниц на диск, мы должны добавить еще больше оборудования. В частности, когда аппаратное обеспечение просматривает PTE, оно может обнаружить, что страница отсутствует в физической памяти. То, как аппаратное обеспечение (или ОС, в программно-управляемом подходе TLB) определяет это, определяется с помощью новой части информации в каждой записи таблицы страниц, известной как present bit. Если текущий бит равен единице, это означает, что страница присутствует в физической памяти, и все происходит так, как описано выше; если он равен нулю, страница находится не в памяти, а где-то на диске. Акт доступа к странице, которой нет в физической памяти, обычно называют page fault.
ТЕРМИНОЛОГИЯ ПРОЦЕССА ПОДКАЧКИ И ДРУГИЕ ШТУКИ
Терминология в системах виртуальной памяти может быть немного запутанной и изменчивой для разных машин и операционных систем. Например, page fault в более общем плане может относиться к любой ссылке на таблицу страниц, которая генерирует какую-либо ошибку: это может включать тип ошибки, которую мы здесь обсуждаем, т. е. ошибка отсутствия страницы, но иногда может относиться к нелегальному доступу к памяти. Действительно, странно, что мы называем то, что определенно является законным доступом (к странице, отображенной в виртуальное адресное пространство процесса, но просто не в физической памяти в это время), вообще “ошибкой”; на самом деле, это следует называть page miss. Но часто, когда люди говорят, что произошёл page fault, они имеют в виду, что она обращается к частям своего виртуального адресного пространства, которые ОС перенесла на диск.
Мы подозреваем, что причина, по которой такое поведение стало известно как “ошибка” (fault), связана с оборудованием в операционной системе, которое его обрабатывает. Когда происходит что-то необычное, то есть когда происходит что-то, с чем аппаратное обеспечение не знает, как справиться, аппаратное обеспечение просто передает управление операционной системе, надеясь, что это может улучшить ситуацию. В этом случае страница, к которой процесс хочет получить доступ, отсутствует в памяти; аппаратное обеспечение делает единственное, что может, а именно создает исключение, и ОС берет на себя управление оттуда. Поскольку это идентично тому, что происходит, когда процесс совершает что-то незаконное, возможно, неудивительно, что мы называем эту деятельность “ошибкой”.
При срабатывании page fault операционная система вызывается для обслуживания этой ошибки. Определенный фрагмент кода, известный как page-fault handler, запускается и должен обслуживать ошибку страницы, как мы сейчас описываем.
The Page Fault
Напомним, что для обработки TLB miss у нас есть два типа систем: управляемые аппаратным обеспечением TLB (где аппаратное обеспечение просматривает таблицу страниц, чтобы найти нужный перевод адреса) и управляемые программным обеспечением TLB (где это делает ОС). В системах любого типа, если страница отсутствует, ответственность за обработку ошибки страницы возлагается на операционную систему, в которой соответствующим образом названый page-fault handler запускается для того, что бы обработать событие. Практически все системы обрабатывают ошибки страниц в программном обеспечении; даже с аппаратно управляемым TLB аппаратное обеспечение доверяет операционной системе управление этой важной обязанностью.
Если страница отсутствует и была перенесена на диск, операционной системе потребуется перенести страницу в память, чтобы устранить page fault. Таким образом, возникает вопрос: откуда ОС узнает, где найти нужную страницу? Во многих системах таблица страниц является естественным местом для хранения такой информации. Таким образом, ОС может использовать биты в PTE, обычно используемые для данных, таких как PFN страницы, для адреса диска. Когда ОС получает page fault для страницы, она просматривает PTE, чтобы найти адрес, и выдает запрос на диск для извлечения страницы в память.
ПОЧЕМУ АППАРАТНОЕ ОБЕСПЕЧЕНИЕ НЕ ОБРАБАТЫВАЕТ ОШИБКИ СТРАНИЦ
Из нашего опыта работы с TLB мы знаем, что разработчики аппаратного обеспечения не хотят доверять операционной системе многое из того, что она делает. Так почему же они доверяют операционной системе обрабатывать page fault? Есть несколько основных причин. Во-первых, запросы к диску после page fault (и вообще) происходят медленно; даже если ОС занимает много времени для обработки сбоя, выполняя тонны инструкций, сама работа с диском традиционно выполняется так медленно, что дополнительные накладные расходы на запуск программного обеспечения минимальны. Во-вторых, чтобы справиться с ошибкой страницы, аппаратное обеспечение должно было бы понимать пространство подкачки, способ ввода-вывода на диск и множество других деталей, о которых оно в настоящее время мало что знает. Таким образом, как по соображениям производительности, так и по причине простоты, ОС обрабатывает ошибки страниц, и даже оборудование может быть довольно.
Когда дисковый ввод-вывод завершится, операционная система обновит таблицу страниц, чтобы пометить страницу как присутствующую, обновит поле PFN записи таблицы страниц (PTE), чтобы записать местоположение в памяти только что извлеченной страницы, и повторит команду. Эта следующая попытка может привести к TLB miss, который затем будет обработан и обновит TLB с переводом (можно поочередно обновлять TLB при обслуживании ошибки страницы, чтобы избежать этого шага). Наконец, последний перезапуск найдет перевод в TLB и, таким образом, продолжит извлекать нужные данные или инструкции из памяти по переведенному физическому адресу.
Обратите внимание, что во время выполнения ввода-вывода процесс будет находиться в заблокированном состоянии. Таким образом, ОС сможет свободно запускать другие готовые процессы во время обслуживания ошибки страницы. Поскольку ввод-вывод является дорогостоящим, этот overlap ввода-вывода (page fault) одного процесса и выполнение другого - еще один способ, которым многопрограммная система может наиболее эффективно использовать свое оборудование.
Что если память заполнена?
В процессе, описанном выше, вы можете заметить, что мы предположили, что имеется достаточно свободной памяти для размещения страницы в пространстве подкачки. Конечно, это может быть не так; память может быть полной (или близкой к заполненной). Таким образом, ОС может захотеть сначала выгрузить одну или несколько страниц, чтобы освободить место для новых страниц, которые ОС собирается ввести. Процесс выбора страницы для удаления или замены известен как политика замены страниц (page-replacement policy).
Как оказалось, много размышлений было вложено в создание хорошей политики замены страниц, поскольку удаление неправильной страницы может привести к большим затратам на производительность программы. Принятие неправильного решения может привести к тому, что программа будет работать со скоростью, подобной скорости диска, вместо скорости, подобной скорости памяти; в современных технологиях это означает, что программа может работать в 10 000 или 100 000 раз медленнее. Таким образом, такая политика-это то, что мы должны изучить более подробно; и это именно то, что мы сделаем в следующей главе. На данный момент достаточно понять, что такая политика существует и построена на основе описанных здесь механизмов.

Page Fault Control Flow
Обладая всеми этими знаниями, мы теперь можем примерно описать полный поток управления доступом к памяти. Другими словами, когда кто-то спрашивает вас: “Что происходит, когда программа извлекает некоторые данные из памяти?”, вы должны иметь довольно хорошее представление обо всех различных возможностях. Смотрите control flow на рисунках 21.2 и 21.3 для получения более подробной информации; на первом рисунке показано, что делает аппаратное обеспечение во время трансляции, а на втором-что делает ОС при page fault.
Из схемы управления аппаратным обеспечением на рис. 21.2 обратите внимание, что теперь необходимо понять три важных случая, когда происходит TLB miss. Во-первых, страница может быть и present и valid одновременно (строки 18-21); в этом случае обработчик TLB miss может просто захватить PFN из PTE, повторить команду (на этот раз, что приведет к TLB hit) и, таким образом, продолжить, как описано (много раз) ранее. Во втором случае (строки 22-23) должен быть запущен page fault handler; не смотря на то что процесс имел права доступа к странице (в конце концов, она валидна), она отсутствует в физической памяти. В-третьих (и, наконец), доступ может быть к недопустимой (invalid) странице, например, из-за ошибки в программе (строки 13-14). В этом случае никакие другие биты в PTE не имеют значения; аппаратное обеспечение блокирует этот не валидный доступ, и запускается обработчик ловушек ОС, вероятно, завершающий процесс нарушения.
Из потока управления программным обеспечением на рис. 21.3 мы можем видеть, что примерно должна делать операционная система для обслуживания ошибки страницы. Во-первых, ОС должна найти физический фрейм для страницы, при доступе к которой скоро произойдёт page fault; если такой страницы нет, нам придется подождать, пока запустится алгоритм замены, и удалить некоторые страницы из памяти.
Имея в руках физический фрейм, обработчик затем выдает запрос ввода-вывода на чтение страницы из пространства подкачки. Наконец, когда эта медленная операция завершается, ОС обновляет таблицу страниц и повторяет инструкцию. Повторная попытка приведет к TLB miss, а затем, при другой повторной попытке, TLB hit, и в этот момент оборудование сможет получить доступ к нужному элементу.
Когда реально происходят замены
До сих пор способ, которым мы описали, как происходят замены, предполагает, что ОС ждет, пока память полностью не заполнится, и только затем заменяет (удаляет) страницу, чтобы освободить место для какой-либо другой страницы. Как вы можете себе представить, это немного нереально, и у операционной системы есть много причин более активно освобождать небольшую часть памяти.
Чтобы освободить небольшой объем памяти, большинство операционных систем используют high watermark (HW) и low watermark (LW), чтобы помочь решить, когда начинать удаление страниц из памяти. Это работает следующим образом: когда ОС замечает, что доступно меньше страниц чем LW, запускается фоновый поток, отвечающий за освобождение памяти. Поток удаляет страницы до тех пор, пока число доступных страниц ни сравняется с HW. Фоновый поток, иногда называемый демоном подкачки или pagedaemon^1, затем переходит в спящий режим, довольный тем, что освободил немного памяти для запущенных процессов и используемой ОС.
^1 - Слово “демон”, является старым термином для фонового потока или процесса, который делает что-то полезное. Оказывается (еще раз!), что источником термина является Multics [CS94].
Выполняя несколько замен одновременно, становится возможной новая оптимизация производительности. Например, многие системы кластеризуют или группируют несколько страниц и сразу записывают их в раздел подкачки, тем самым повышая эффективность диска [LL82]; как мы увидим позже, когда мы более подробно обсудим диски, такая кластеризация снижает накладные расходы на поиск и вращение диска и, таким образом, заметно повышает производительность.
Для работы с фоновым потоком подкачки поток управления на рис. 21.3 следует немного изменить; вместо того, чтобы выполнять замену напрямую, алгоритм вместо этого просто проверит, есть ли свободные страницы. Если нет, он сообщит фоновому потоку подкачки, что необходимы свободные страницы; когда поток освободит несколько страниц, он снова пробудит исходный поток, который затем сможет перейти на нужную страницу и продолжить свою работу.
СОВЕТ: ВЫПОЛНЯЙТЕ РАБОТУ В ФОНОВОМ РЕЖИМЕ
Когда вам нужно выполнить какую-то работу, часто рекомендуется делать это в фоновом режиме, чтобы повысить эффективность и обеспечить группировку операций. Операционные системы часто работают в фоновом режиме; например, многие системы буферизуют запись файлов в память перед фактической записью данных на диск. Это имеет множество возможных преимуществ: повышенная эффективность диска, так как диск теперь может получать много записей одновременно и, следовательно, лучше планировать их; улучшенная задержка записи, так как приложение считает, что записи завершаются довольно быстро; возможность сокращения работы, так как записи, возможно, никогда не потребуется записывать на диск (т. Е., если файл удален); и лучшее использование времени простоя, так как фоновая работа может выполняться, когда система в противном случае простаивает, что позволяет лучше использовать аппаратное обеспечение [G+95].
Выводы
В этой краткой главе мы ввели понятие доступа к большему объему памяти, чем физически присутствует в системе. Для этого требуется большая сложность в структурах таблиц страниц, так как необходимо включить present bit (какого-либо рода), чтобы сообщить нам, присутствует ли страница в памяти. В противном случае обработчик ошибок страниц операционной системы запускается для обслуживания ошибки страницы и, таким образом, организует передачу нужной страницы с диска в память, возможно, сначала заменив некоторые страницы в памяти, чтобы освободить место для тех, которые вскоре будут заменены.
Напомним, что важно (и удивительно!), что все эти действия происходят прозрачно для процесса. Что касается процесса, то он просто получает доступ к своей собственной частной, смежной виртуальной памяти. За кулисами страницы размещаются в произвольных (несмежных) местах физической памяти, а иногда их даже нет в памяти, что требует извлечения с диска. Хотя мы надеемся, что в обычном случае доступ к памяти осуществляется быстро, в некоторых случаях для его обслуживания потребуется несколько операций с диском; выполнение такой простой операции, как выполнение одной инструкции, в худшем случае может занять много миллисекунд.
Ссылки
[CS94] “Take Our Word For It” by F. Corbato, R. Steinberg. www.takeourword.com/TOW146 (Page 4). Richard Steinberg writes: “Someone has asked me the origin of the word daemon as it applies to computing. Best I can tell based on my research, the word was first used by people on your team at Project MAC using the IBM 7094 in 1963.” Professor Corbato replies: “Our use of the word daemon was inspired by the Maxwell’s daemon of physics and thermodynamics (my background is in physics). Maxwell’s daemon was an imaginary agent which helped sort molecules of different speeds and worked tirelessly in the background. We fancifully began to use the word daemon to describe background processes which worked tirelessly to perform system chores.”
[D97] “Before Memory Was Virtual” by Peter Denning. In the Beginning: Recollections of Software Pioneers, Wiley, November 1997. An excellent historical piece by one of the pioneers of virtual memory and working sets
[G+95] “Idleness is not sloth” by Richard Golding, Peter Bosch, Carl Staelin, Tim Sullivan, John Wilkes. USENIX ATC ’95, New Orleans, Louisiana. A fun and easy-to-read discussion of how idle time can be better used in systems, with lots of good examples.
[LL82] “Virtual Memory Management in the VAX/VMS Operating System” by Hank Levy, P. Lipman. IEEE Computer, Vol. 15, No. 3, March 1982. Not the first place where page clustering was used, but a clear and simple explanation of how such a mechanism works. We sure cite this paper a lot!