В этой статье я покажу, как быстро и просто визуализировать данные, которые представлены в виде таблицы Excel или CSV-файла. Визуализировать будем при помощи библиотек pandas и matplotlib, используя обычный график, гистограмму и круговую диаграмму ("пирог").
Готовим данные
Для этой статьи я нашел на просторах сети файл со статистическими данными, в котором были собраны популярные "русские" имена на просторах Америки. Некоторые имена показались мне странными, но правдивость данных не тема этой статью, поэтому перейдем к делу.
На входе имеем CSV-файл с какой-то информацией, заглянем в него блокнотом:
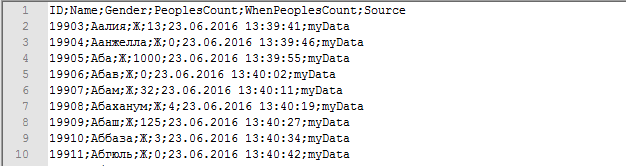
Структура, в целом, несложная. Наибольший интерес представляют поля Name (имя), Gender (пол) и PeoplesCount (количество людей). В качестве разделителя используется ";" - это нам пригодится. Поставим себе задачи:
- Выявить и отобразить на графике (гистограмма) 15 самых популярных имён;
- Вычислить и отобразить соотношение мужских и женских имен (круговая диаграмма);
- Отобразить график количества имен в зависимости от его длины.
Начинаем писать скрипт. Импортируем необходимые библиотеки и считываем данные из файла (считывание из Excel здесь):

Для решения первой задачи необходимо найти 15 самых популярных имён, для этого отсортируем полученный датафрейм names по столбцу PeoplesCount в порядке убывания и возьмем 15 первых записей сверху. Делаем это легко и непринужденно, в две строки:
В первой строке осуществляем сортировку столбца (by=['PeoplesCount']) по убыванию (ascending=False), а во второй берем 15 первых строк полученного фрейма. Первая порция данных получена!
Переходим к сбору данных для второй задачи. Здесь все еще проще и решается в одну строку. Делаем группировку по столбцу Gender и считаем количество методом count():
Приступаем к третьей задачей. Здесь уже сложнее, но не драматически. Необходимо пройтись по элементам столбца Names и вычислить длину каждого имени, после чего, применив уже знакомую группировку, посчитать количество повторений каждой вычисленной длины.
Для вычисления длины имени нам поможет лямбда-функция и метод apply() датафрейма. По сути своей, этот метод модифицирует данные в столбце, применяя к ним переданную в аргументы функцию. Наша функция будет считать количество символов в имени и заменять каждое имя в строке его длиной.
Кто-то из вас еще может не знать, что такое лямбда-функции, в этой статье я не буду подробно про них рассказывать. Однако скажу, что использовать ее вовсе необязательно. Можно обойтись и обычной функцией, но мне больше по нраву лаконичность и простота лямбды в данном случае. Сравним.
В верхней части следующей иллюстрации объявлена функция, которая принимает на вход переменную, преобразует ее в строку, считает и возвращает ее длину. Затем, эта функция передается в метод apply() датафрейма top_names. В итоге, нам пришлось потратить время и несколько лишних строк, для того, чтобы преобразовать данные в нужный нам вид. Это чаще всего оправданно, когда функция нетривиальна и выполняет непростые манипуляции. Но в нашем случае дейтсвие предельно простое, и мы можем получить абсолютно идентичный результат, написав лямбда-функцию прямо в аргументе метода apply(), что и сделано в последней строке:
Далее применяем группировку и делаем подсчёт. Все три порции данных получены - можно переходить к визуализации.
Рисуем графики
Переходим к самому интересному - визуализация. Чтобы вы обрели некоторую уверенность и понимание происходящего отмечу, что график состоит из трёх основных элементов - figure (поле для творчества), axes (оси, между которыми будет график) и сам график (plot, pie, bar и т.п.)
Сначала нам необходимо определиться со структурой figure и его размерами. Нам необходимо полотно, на котором мы сможем расположить три графика, для этого зададим размер 1 на 3, укажем размер полотна в дюймах, чтобы все поместилось визуально и отобразим фигуру вызовом метода show():
Теперь можно добавлять сами графики на размеченные оси. Приступим. Когда мы размечали фигуру при помощи вызова метода subplots() мы получили объект фигуры - fig и объект её осей - axes. Обратимся к первой оси и разместим на ней гистограмму по первой задаче.
Нарисуем горизонтальную гистограмму вызовом метода barh(), передав ему данные из столбца Name для оси X и данные из столбца PeoplesCount для оси Y. Попутно укажем заголовок, избавимся от степеней в записи больших чисел по оси X и немного повернем подписи по ней, чтобы не перекрывали друг друга:
И вот, что мы имеем на выходе:
Немного порадуемся и перейдем ко второй оси. Будем рисовать пирог!
Вызываем метод pie() и передаем ему данные - количество имен для каждого пола и подписи (label - "М" и "Ж"), также указываем формат вывода долей в процентах прямо на пироге и заголовок:
Настало время заполнить третью ось обычным графиком. Вызываем для нее метод plot() и передаем в него данные для оси X (количество букв), оси Y (количество имен) и укажем толщину линии побольше для наглядности:
Заключение
Надеюсь эта статья принесла вам немного пользы и вы теперь сможете строить графики по своим данным. Написанное здесь - самый базовый уровень, существует куда больше типов доступных графиков и очень много возможностей для тонкой настройки их отображения. На сегодня всё, заяц из последнего графика машет вам рукой и я прощаюсь. До скорых встреч!