Пагинация: меньшие таблицы
Мы готовы обсудить вторую проблему которая возникает при использовании пагинации: таблицы страниц слишком большие следовательно потребляют слишком много памяти. Давайте начнём с линейной таблицы страниц. Как вы помните, линейные таблицы страниц очень большие. Снова рассмотрим 32 битное адресное пространство (2^32 бит), с 4 Kb (2^12 бит) страницами в которых одна запись будет равна 4 байтам. Такое адресное пространство будет содержать примерно 1 млн виртуальных страниц (2^32 / 2^12); умножьте на размер 1 записи и наша таблица страниц окажется размером в 4 Mb. Также имейте ввиду: мы обычно имеем одну таблицу страниц на каждый процесс! Если активных процессов будет 100 (ничего необычного в современных системах) мы займём в памяти сотни мегабайт только для хранения таблиц страниц. Наша задача применить технику которая позволит сократить столь огромный объём. Существует множество техник, так что давайте приступим к их изучению. Но не раньше чем формализуем проблему:
КАК СДЕЛАТЬ ТАБЛИЦЫ СТРАНИЦ МЕНЬШЕ
Простые таблицы страниц основанные на массивах (обычно называемых линейными таблицами страниц памяти) большие и забирают слишком много памяти. Как мы можем сделать их меньше? Каковы ключевые идеи? Какие проблемы появляются по мере внедрения этих идей?
20.1 ПРОСТОЕ РЕШЕНИЕ - ТАБЛИЦЫ БОЛЬШЕГО РАЗМЕРА
Мы можем изменить размер таблицы страниц одним простым способом: использовать страницы большего размера. Рассмотрим снова 32 битное пространство, но на этот раз выделим для страниц 16 Кб. Таким образом мы получим 16 битный VPN и 14 битное смещение. Оставим размер записи в странице 4 байта и получим возможность создать 2^18 записей в нашей линейной таблице страниц и размер одной таблицы страниц равный 1 Мб, увеличение размера страницы в 4 раза привело к 4х кратному уменьшению размера таблицы.
Основная проблема данного подхода заключается в том, что место избыточно тратится в каждой странице (внутренняя фрагментация). Приложения, таким образом, заполняют страницы неполностью, используя только маленькое пространство в них и память быстро заканчивается. Таким образом системы используют относительно небольшие размеры страниц (4Кб в х86, 8Кб в SPARCv9). Наша проблема не может быть решена таким простым способом, увы.
20.02 ГИБРИДНОЕ РЕШЕНИЕ - ПАГИНАЦИЯ И СЕГМЕНТАЦИЯ
Когда у вас имеется два разумных но разных подхода для какой-то проблемы, всегда нужно попробовать соединить оба подхода в попытке взять лучшее из обоих решений. Мы называем такую комбинацию hybrid.
- Годы назад, создатель Multics (Jack Dennis) случайно наткнулся на идею связанную со строением системы виртуальной памяти в Multics. Её суть в одновременном применении пагинации и сегментации в попытке снизить накладные расходы связанные с памятью. Мы можем увидеть почему это сработало разобрав обычную линейную таблицу страниц более подробно. Предположим у нас есть адресное пространство в котором используемое пространство кучи и стека мало. Например мы используем маленькое адресное пространство 16Кб со страницами по 1Кб (рис. 20.1); таблица страниц для этого адресного пространства на рисунке 20.02
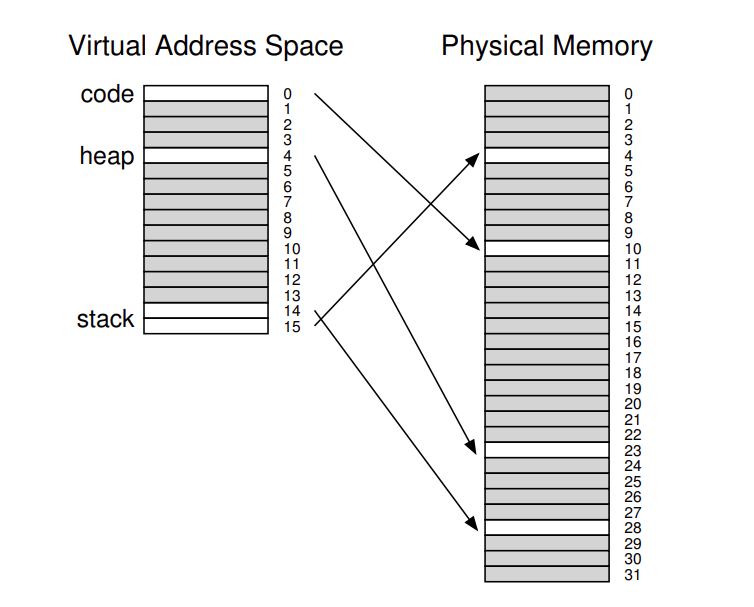
Пример предполагает то что единственная страница кода (vpn 0) мапится на физическую страницу 10. Единственная страница кучи vpn 4 на физическую страницу 23 и две страницы стека в другом конце адресного пространства vpn 14, 15 мапятся на физические страницы 28 и 4. Как вы можете увидеть из рисунка - основная масса из таблицы страниц неиспользуется и полна невалидных записей. Так много мусора для такого маленького 16 Кб пространства. Представьте сколько мусора будет в 32 битном адресном пространстве и весь потенциальный мусор в нём.
Вот что предлагает наше гибридное решение: вместо выделения таблицы страниц для конкретного адресного пространства, почему бы ни иметь её для каждого логического сегмента? В данном примере мы можем иметь три таблицы страниц по одной для кода, кучи и стека. Теперь вспомнить про сегментацию, у нас есть базовый регистр который помогает понять где именно в физической памяти расположен каждый сегмент и bound и limit регистры которые указывают на размер этих сегментов. В нашей гибридной системе, мы храним эти структуры в MMU; здесь мы используем базовый регистр не для указания на сам сегмент, но для хранения физического адреса таблицы страниц данного сегмента. Bounds регистр используется для индикации конца таблицы страниц.
Для большей ясности приведём простой пример. Рассмотрим 32 битное виртуальное адресное пространство со страницами по 4 Кб, и адресное пространство разбитое на 4 сегмента. Для нашего примера мы используем только 3 сегмента: для кода, для кучи и для стека.
Для того чтобы определить какой адрес куда ссылается, мы используем верхние два бита адресного пространства. Предположим что 00 это неиспользуемый сегмент, 01 для кода, 10 для кучи и 11 для стэка. Соответственно виртуальный адрес будет выглядеть следующим образом:
Предположим, что в аппаратном обеспечении существуют три пары base/bounds регистров по одной для кода, кучи и стэка. Когда процесс запущен, base регистр для каждого из этих сегментов содержит физический адрес линейной таблицы страниц для этого сегмента; таким образом, каждый процесс в системе теперь имеет три таблицы страниц ассоциированных с ним. При переключении контекста эти регистры должны быть изменены, чтобы отразить расположение таблиц страниц вновь запущенного процесса.
При срабатывании события TLB miss (при условии, что TLB управляется аппаратным обеспечением, т. е. аппаратное обеспечение отвечает за обработку событий TLB miss), аппаратное обеспечение использует биты сегмента (SN), чтобы определить, какую пару base and bounds использовать. Затем аппаратное обеспечение читает физический адрес в регистре и объединяет его с VPN следующим образом, чтобы сформировать адрес записи таблицы страниц (PTE или page table entry):
Эта последовательность должна выглядеть знакомой; она практически идентична тому, что мы видели раньше с линейными таблицами страниц. Единственное отличие, конечно, заключается в использовании одного из трех base регистров сегментов вместо base регистра таблицы одной страницы.
СОВЕТ: ИСПОЛЬЗУЙТЕ ГИБРИДЫ
Когда у вас есть две хорошие и, казалось бы, противоположные идеи, вы всегда должны попытаться понять, сможете ли вы объединить их в гибрид, который сможет достичь лучшего из обоих миров. Например, гибридные виды кукурузы, как известно, более устойчивы, чем любые естественные виды. Конечно, не все гибриды являются хорошей идеей; посмотрите на Zeedonk (или Zonkey), который представляет собой скрещивание Зебры и Осла. Если вы не верите, что такое существо существует, найдите его и приготовьтесь удивиться.
Критическим отличием нашей гибридной схемы является наличие bounds регистра для каждого сегмента; каждый bounds регистр содержит значение максимально допустимой страницы в сегменте. Например, если сегмент кода использует свои первые три страницы (0, 1 и 2), в таблице страниц сегмента кода будет выделено только три записи, а bounds регистру будет присвоено значение 3; доступ к памяти после окончания сегмента создаст исключение и, вероятно, приведет к завершению процесса. Таким образом, наш гибридный подход обеспечивает значительную экономию памяти по сравнению с линейной таблицей страниц; нераспределенные страницы между стеком и кучей больше не занимают места в таблице страниц (весь смысл которых был в том, что они помечены как невалидные).
Однако, как вы могли заметить, этот подход не лишен проблем. Во-первых, это все еще требует от нас использования сегментации; как мы обсуждали ранее, сегментация не так гибка, как хотелось бы, поскольку предполагает определенную схему использования адресного пространства; например, если у нас большая, но редко используемая куча, мы все равно можем получить много мусора в таблице страниц. Во-вторых, этот гибрид вызывает повторное возникновение внешней фрагментации. Хотя большая часть памяти управляется в единицах размера страницы, таблицы страниц теперь могут иметь произвольный размер (кратный PTE). Таким образом, найти для них свободное место в памяти сложнее. По этим причинам люди продолжали искать лучшие способы реализации таблиц страниц меньшего размера.
20.3 МНОГОУРОВНЕВЫЕ ТАБЛИЦЫ СТРАНИЦ
Другой подход не основан на сегментации, но решает ту же проблему: как избавиться от всех этих пустых невалидных записей в таблице страниц вместо того чтобы хранить их все в памяти? Мы называем этот подход многоуровневой таблицей страниц, поскольку он превращает линейную таблицу страниц в нечто вроде дерева. Этот подход настолько эффективен, что его используют многие современные системы (например, x86 [BOH 10]). Теперь мы подробно опишем этот подход.
Основная идея многоуровневой таблицы страниц проста. Сначала разделите таблицу страниц на блоки размером со страницу; затем, если вся страница записей (PTE) невалидна, вообще не выделяйте эту страницу в памяти. Чтобы отслеживать, является ли страница валидной (и, если валидна, где она находится в памяти), используйте новую структуру, называемую каталогом страниц. Каталог страниц может использоваться либо для указания того, где находится страница таблицы, либо для указания того, что вся страница таблицы не содержит допустимых страниц (невалидна).
На рисунке 20.3 показан пример. Слева от рисунка изображена классическая линейная таблица страниц; хотя большинство средних областей адресного пространства невалидны, нам все равно требуется пространство таблицы, выделенное в памяти для этих областей (т. е. две средние страницы таблицы). Справа находится многоуровневая таблица страниц. Каталог страниц помечает только две страницы таблицы страниц как допустимые (первую и последнюю); таким образом, только эти две страницы таблицы находятся в памяти. Вы можете увидеть один из способов визуализации того, что делает многоуровневая таблица: она просто удаляет части линейной таблицы страниц (освобождая место для других целей) и отслеживает, какие страницы таблицы выделены каталогом страниц.
Каталог страниц в простой двухуровневой таблице содержит по одной записи на страницу. Он состоит из нескольких записей каталога страниц (PDE). PDE (минимально) имеет бит валидности и номер фрейма страницы (PFN), аналогичный PTE. Однако, как указывалось выше, значение этого бита валидности немного отличается: если PDE является валидным, это означает, что по крайней мере одна из страниц таблицы, на которую указывает запись (через PFN), является валидной, т. е. по крайней мере в одном PTE на этой странице, на которую указывает этот PDE, бит валидности в этом PTE установлен равным единице. Если PDE невалиден (т. е. равен нулю), остальная часть PDE не определена.
Многоуровневые таблицы страниц имеют некоторые очевидные преимущества перед подходами, которые мы видели до сих пор. Во-первых, и, возможно, наиболее очевидно, что многоуровневая таблица выделяет пространство таблицы страниц только пропорционально объему используемого вами адресного пространства; таким образом, она, как правило, компактна и поддерживает разреженные адресные пространства.
Во-вторых, при тщательном построении каждая часть таблицы страниц аккуратно помещается на странице, что облегчает управление памятью; операционная система может просто захватить следующую свободную страницу, когда ей нужно выделить или расширить таблицу страниц. Сравните это с простой (без подкачки) линейной таблицей страниц, которая представляет собой просто массив PTE, индексируемых VPN; при такой структуре вся линейная таблица страниц должна непрерывно находиться в физической памяти. Для большой таблицы страниц (скажем, 4 МБ) найти такой большой кусок неиспользуемой непрерывной свободной физической памяти может быть довольно сложной задачей. При многоуровневой структуре мы добавляем уровень косвенности за счет использования каталога страниц, который указывает на фрагменты таблицы страниц; это косвенное указание позволяет нам размещать страницы таблицы страниц везде, где мы хотели бы, в физической памяти.
СОВЕТ: ПОЙМИТЕ КОМПРОМИССЫ МЕЖДУ ПРОСТРАНСТВОМ И ВРЕМЕНЕМ
При построении структуры данных всегда следует учитывать пространственно-временные компромиссы при ее построении. Обычно, если вы хотите ускорить доступ к определенной структуре данных, вам придется заплатить штраф за использование пространства для этой структуры.
Следует отметить, что многоуровневые таблицы обходятся дорого; при срабатывании TLB miss потребуется две загрузки из памяти для получения правильной информации о переводе из таблицы страниц (одна для каталога страниц и одна для самого PTE), в отличие от только одной загрузки с линейной таблицей страниц. Таким образом, многоуровневая таблица является небольшим примером компромисса между пространством и временем. Мы хотели таблицы меньшего размера (и получили их), но не бесплатно; хотя в обычном случае (TLB hit) производительность, очевидно, одинакова, TLB miss страдает от более высокой стоимости с этой меньшей таблицей.
Еще один очевидный минус-сложность. Независимо от того, является ли это аппаратным обеспечением или операционной системой, обрабатывающей поиск по таблице страниц (при TLB miss), это, несомненно, более сложно, чем простой линейный поиск по таблице страниц. Часто мы готовы увеличить сложность, чтобы повысить производительность или снизить накладные расходы; в случае многоуровневой таблицы мы усложняем поиск по таблицам страниц, чтобы сэкономить ценную память.
Детальный многоуровневый пример
Для того чтобы лучше понять идею лежащую в основе многоуровневых страниц памяти, рассмотрим пример. Представим маленькое адресное пространство размером 16Кб, со страницами по 64 байта. Таким образом, у нас есть 14-битное виртуальное адресное пространство с 8 битами для VPN и 6 битами для смещения. Линейная таблица памяти будет иметь 2^8 (256) вхождений, даже если будет использоваться небольшая порция адресного пространства. Рисунок 20.4 изображает такое адресное пространство.
В этом примере виртуальные страницы 0 и 1 предназначены для кода, виртуальные страницы 4 и 5-для кучи, а виртуальные страницы 254 и 255-для стека; остальные страницы адресного пространства не используются.
Чтобы построить двухуровневую таблицу страниц для этого адресного пространства, мы начинаем с нашей линейной таблицы и разбиваем ее на блоки размером со страницу каждый. Напомним, что наша полная таблица (в этом примере) содержит 256 записей; предположим, что размер каждого PTE составляет 4 байта. Таким образом наша таблица будет иметь размер 1Кб (256х4). Исходя из того что страницы имеют размер 64 байта, таблица в 1Кб может быть разделена на 16 страниц по 64 байт; каждая страница может содержать 16 PTE.
Теперь нам нужно понять, как взять VPN и использовать его для индексирования сначала в каталог страниц, а затем на страницу таблицы страниц. Помните, что каждая запись представляет собой массив записей; таким образом, все, что нам нужно выяснить, - это как построить индекс для каждой из частей VPN.
Давайте сначала проиндексируем его в каталоге страниц. Наша таблица страниц в этом примере невелика: 256 записей, разбросанных по 16 страницам. Каталог страниц нуждается в одной записи на страницу таблицы; таким образом, в нем 16 записей. В результате нам нужно четыре бита VPN для индексирования в каталог; мы используем четыре верхних бита VPN следующим образом:
Как только мы извлечём индекс каталога страниц (page-directory index или PDIndex) из VPN, мы можем использовать его чтобы найти адрес в каталоге страниц (page-directory entry PDE) с помощью простых вычислений: PDEAddr = PageDirBase + (PDIndex * sizeof(PDE)). Это приводит нас в каталог страниц (page directory).
Если запись в page-directory помечена как invalid, мы знаем что доступ невозможен, и можем вызвать исключение. Если PDE помечен как valid мы продолжаем трансляцию. Теперь мы пытаемся получить доступ к page-table entry (PTE) из страницы таблицы на которую ссылается page-directory entry (PDE). Чтобы найти этот PTE, мы должны проиндексировать часть таблицы, используя оставшиеся биты VPN:
Этот page-table index (PTIndex для краткости) затем можно использовать для индексирования в самой таблице страниц, для того чтобы узнать PTE
Обратите внимание, что page-frame number (PFN), полученный из page-table index, должен быть сдвинут влево, прежде чем объединять его с индексом таблицы страниц для формирования адреса PTE.
Чтобы понять, имеет ли все это смысл, мы теперь заполним многоуровневую таблицу страниц некоторыми фактическими значениями и переведем один виртуальный адрес. Давайте, в рамках данного примера, начнём с page directory (левая сторона рисунка 20.5).
На рисунке вы можете видеть, что каждая запись каталога страниц (page-directory entry - PDE) описывает что-то о странице таблицы страниц для адресного пространства. В этом примере у нас есть две допустимые области в адресном пространстве (в начале и в конце) и ряд недопустимых сопоставлений между ними.
На физической странице 100 (номер физического кадра 0-й страницы таблицы страниц) у нас есть первая страница из 16 записей таблицы страниц для первых 16 VPN в адресном пространстве. Содержание этой части таблицы страниц см. на рис. 20.5 (средняя часть).
Эта страница таблицы страниц содержит сопоставления для первых 16 VPN; в нашем примере допустимы VPN 0 и 1 (сегмент кода), а также 4 и 5 (куча). Таким образом, в таблице содержится информация о сопоставлении для каждой из этих страниц. Остальные записи помечены как недействительные.
СОВЕТ: БУДЬТЕ ОСТОРОЖНЫ СО СЛОЖНОСТЯМИ
Разработчики систем должны с осторожностью относиться к усложнению своей системы. Что делает хороший разработчик систем, так это внедряет наименее сложную систему, которая решает поставленную задачу. Например, если на диске много места, вам не следует создавать файловую систему, которая усердно работает, чтобы использовать как можно меньше байтов; аналогично, если процессоры быстры, лучше написать чистый и понятный модуль в ОС, чем, возможно, оптимизированный для процессора mos, собранный вручную код для данной задачи. Будьте осторожны с ненужной сложностью, в преждевременно оптимизированном коде или других формах; такие подходы усложняют понимание, обслуживание и отладку систем. Как прекрасно написал Антуан де Сент-Экзюпери: “Совершенство, наконец, достигается не тогда, когда больше нечего добавить, а когда больше нечего отнять”. Что он не написал: “Гораздо легче сказать что-то о совершенстве, чем на самом деле достичь его”.
Другая допустимая страница таблицы страниц находится внутри PDF 101. Эта страница содержит сопоставления для последних 16 VPN адресного пространства; подробности см. на рис. 20.5 (справа).
В примере VPN 254 и 255 (стек) имеют допустимые сопоставления. Надеюсь, из этого примера мы увидим, насколько возможна экономия места при многоуровневой индексированной структуре. В этом примере вместо выделения полных шестнадцати страниц для линейной таблицы страниц мы выделяем только три: одну для каталога страниц и две для фрагментов таблицы страниц, которые имеют допустимые сопоставления. Очевидно, что экономия для больших (32-разрядных или 64-разрядных) адресных пространств может быть намного больше.
Наконец, давайте используем эту информацию для выполнения перевода. Вот адрес, который относится к 0-му байту VPN 254: 0x3F80 или 11 1111 1000 0000 в двоичном формате.
Напомним, что мы будем использовать 4 верхних бита VPN для индексирования в каталог страниц. Таким образом, 1111 выберет последнюю (15-ю, если вы начнете с 0-й) запись каталога страниц выше. Это указывает нам на действительную страницу таблицы страниц, расположенную по адресу 101. Затем мы используем следующие 4 бита VPN (1110) для индексирования этой страницы таблицы страниц и поиска нужного PTE. 1110 является предпоследней (14-й) записью на странице и сообщает нам, что страница 254 нашего виртуального адресного пространства отображается на физической странице 55. Объединив PFN=55 (или шестнадцатеричный 0x37) со смещением=000000, мы можем, таким образом, сформировать желаемый физический адрес и отправить запрос в систему памяти: PhysAddr = (PTE.PFN << СДВИГ) + смещение = 00 1101 1100 0000 = 0x0DC0.
Теперь у вас должно быть некоторое представление о том, как создать двухуровневую таблицу страниц, используя каталог страниц, который указывает на страницы таблицы страниц. Однако, к сожалению, наша работа не завершена. Как мы сейчас обсудим, иногда двух уровней таблицы страниц недостаточно!
Больше чем два уровня
В нашем примере до сих пор мы предполагали, что многоуровневые таблицы страниц имеют только два уровня: каталог страниц и затем части таблицы страниц. В некоторых случаях возможно (и действительно необходимо) более глубокое дерево.
Рассмотрим простой пример который позволит понять ситуации в которых использование большего числа уровней может быть полезным. Предположим мы имеем 30 битное виртуальное адресное пространство и небольшие страницы по 512 байт. Виртуальный адрес состоит из 21 битного номера виртуальной страницы и 9-ти битного смещения.
Помните, что наша цель - это построить многоуровневую таблицу страниц: чтобы уместить каждый фрагмент таблицы страниц на одной странице. До сих пор мы рассматривали только саму таблицу страниц; однако, что делать, если каталог страниц станет слишком большим?
Чтобы определить, сколько уровней необходимо в многоуровневой таблице, чтобы все части таблицы страниц помещались на странице, мы начнем с определения того, сколько записей таблицы страниц помещается на странице памяти. Учитывая размер нашей страницы 512 байт и размер записи (PTE page table entry) в 4 бита, становится ясно, что можно разместить 128 записей (PTE) на одной странице. Когда мы индексируем страницу таблицы страниц, мы можем, таким образом, сделать вывод, что нам понадобятся наименее значимые 7 бит (log2 128) VPN в качестве индекса:
Обратите внимание на то, как много бит выделено для индекса реестра страниц: 14. Если реестр страниц вмещает 2^14 записей, он охватывает не одну страницу а 128, и это мешает нам решить задачу размещения всех частей многоуровневой таблицы на одной странице памяти.
Чтобы устранить эту проблему, мы построим следующий уровень дерева, разделив сам каталог страниц на несколько страниц, а затем добавив поверх него еще один каталог страниц, чтобы указать на страницы каталога страниц.
Теперь при индексации каталога страниц верхнего уровня мы используем самые верхние биты виртуального адреса (индекс PD 0 на диаграмме); этот индекс можно использовать для извлечения записи каталога страниц из каталога верхнего уровня. Если доступ к записи помечен как валидный, со вторым уровнем каталога страниц можно ознакомиться, объединив номер физического кадра из PDE верхнего уровня и следующей части VPN (индекс PD 1). Наконец, если доступ к памяти разрешён, адрес PTE может быть сформирован с помощью индекса таблицы страниц в сочетании с адресом из PDE второго уровня. Ух ты! Это большая работа. И все только для того, чтобы посмотреть что-то в многоуровневой таблице.
Процесс трансляции: хранение TLB
Чтобы обобщить весь процесс трансляции адресов с помощью двухуровневой таблицы страниц, мы еще раз представляем поток управления в алгоритмической форме на рис 20.6. На рисунке показано, что происходит в аппаратном обеспечении (при условии, что TLB управляется аппаратным обеспечением) при каждой ссылке на память.
Как вы можете видеть из рисунка, прежде чем произойдет какой-либо сложный многоуровневый доступ к таблице страниц, аппаратное обеспечение сначала проверяет TLB; при успешном запросе физический адрес формируется напрямую без доступа к таблице страниц вообще, как и раньше. Только если в TLB ничего не найдено (TLB miss) аппаратное обеспечение должно выполнить полный многоуровневый поиск. На этом пути вы можете увидеть стоимость нашей традиционной двухуровневой таблицы страниц: два дополнительных доступа к памяти для поиска допустимого перевода.
20.4 Инвертированные таблицы страниц
Еще более значительную экономию пространства в мире таблиц страниц обеспечивают перевернутые таблицы страниц (inverted page tables). Здесь вместо множества таблиц страниц (по одной на каждый процесс системы) мы сохраняем одну таблицу страниц, в которой есть запись для каждой физической страницы системы. Запись сообщает нам, какой процесс использует эту страницу, и какая виртуальная страница этого процесса сопоставляется с этой физической страницей.
Поиск правильной записи теперь является вопросом поиска в этой структуре данных. Линейное сканирование было бы дорогостоящим, и поэтому хэш-таблица часто строится поверх базовой структуры для ускорения поиска. PowerPC является одним из примеров такой архитектуры [JM98].
В более общем плане перевернутые таблицы страниц иллюстрируют то, что мы говорили с самого начала: таблицы страниц-это просто структуры данных. Вы можете делать много сумасшедших вещей со структурами данных, делая их меньше или больше, делая их медленнее или быстрее. Многоуровневые и перевернутые таблицы страниц-это всего лишь два примера многих вещей, которые можно было бы сделать.
20.5 Сброс таблиц страниц на диск (Подкачка, swapping)
Наконец, мы обсудим одного из последних предположений. До сих пор мы предполагали, что таблицы страниц находятся в физической памяти, принадлежащей ядру. Однако, несмотря на наши многочисленные уловки по уменьшению размера таблиц страниц, все еще возможно, что они могут быть слишком большими, чтобы поместиться в памяти все сразу. Таким образом, некоторые системы помещают такие таблицы страниц в виртуальную память ядра, тем самым позволяя системе перемещать некоторые из этих таблиц страниц на диск, когда объем памяти становится немного ограниченным. Мы поговорим об этом подробнее в следующей главе (а именно, в тематическом исследовании VAX/виртуальных машин), как только мы более подробно поймем, как перемещать страницы в память и из нее.
20.6 Выводы
Теперь мы увидели, как строятся реальные таблицы страниц; не обязательно как линейные массивы, но как более сложные структуры данных. Компромиссы, которые представляют такие таблицы, заключаются во времени и пространстве — чем больше таблица, тем быстрее можно обслуживать TLB miss, а также наоборот, и, следовательно, правильный выбор структуры сильно зависит от ограничений данной среды.
В системе с ограниченным объемом памяти (как и во многих старых системах) небольшие структуры имеют смысл; в системе с разумным объемом памяти и с рабочими нагрузками, которые активно используют большое количество страниц, более крупная таблица, которая ускоряет пропуски TLB, может быть правильным выбором. С помощью управляемых программным обеспечением TLBS все пространство структур данных открывается к удовольствию новатора операционной системы (подсказка: это вы). Какие новые структуры вы можете придумать? Какие проблемы они решают? Думайте об этих вопросах, когда засыпаете, и мечтайте о больших мечтах, которые могут сниться только разработчикам операционных систем.
Ссылки
[BOH10] “Computer Systems: A Programmer’s Perspective” by Randal E. Bryant and David R. O’Hallaron. Addison-Wesley, 2010. We have yet to find a good first reference to the multi-level page table. However, this great textbook by Bryant and O’Hallaron dives into the details of x86, which at least is an early system that used such structures. It’s also just a great book to have.
[JM98] “Virtual Memory: Issues of Implementation” by Bruce Jacob, Trevor Mudge. IEEE Computer, June 1998. An excellent survey of a number of different systems and their approach to virtualizing memory. Plenty of details on x86, PowerPC, MIPS, and other architectures.
[LL82] “Virtual Memory Management in the VAX/VMS Operating System” by Hank Levy, P. Lipman. IEEE Computer, Vol. 15, No. 3, March 1982. A terrific paper about a real virtual memory manager in a classic operating system, VMS. So terrific, in fact, that we’ll use it to review everything we’ve learned about virtual memory thus far a few chapters from now.
[M28] “Reese’s Peanut Butter Cups” by Mars Candy Corporation. Published at stores near you. Apparently these fine confections were invented in 1928 by Harry Burnett Reese, a former dairy farmer and shipping foreman for one Milton S. Hershey. At least, that is what it says on Wikipedia. If true, Hershey and Reese probably hate each other’s guts, as any two chocolate barons should.
[N+02] “Practical, Transparent Operating System Support for Superpages” by Juan Navarro, Sitaram Iyer, Peter Druschel, Alan Cox. OSDI ’02, Boston, Massachusetts, October 2002. A nice paper showing all the details you have to get right to incorporate large pages, or superpages, into a modern OS. Not as easy as you might think, alas.
[M07] “Multics: History” Available: http://www.multicians.org/history.html. This amazing web site provides a huge amount of history on the Multics system, certainly one of the most influential systems in OS history. The quote from therein: “Jack Dennis of MIT contributed influential architectural ideas to the beginning of Multics, especially the idea of combining paging and segmentation.” (from Section 1.2.1)