Словосочетание "модель машинного обучения" - часто используемое определение, можно сказать, что модное. Его используют инженеры, менеджеры и даже руководители бизнеса, однако все ли из них представляют один и тот же образ за своими словами? Попробуем предметно и без специальных терминов разобраться с этим понятием.
Статья может быть полезна для проектных менеджеров, собственников бизнеса. Терминология предельно упрощена, алгоритмы сведены до уровня общего понимания.

Предположим, что у вас есть исторические данные, описывающие бизнес в виде аналитической таблицы. Слева (1) выделены некие показатели, такие как оборот бизнеса, генерируемая им прибыль и стоимость активов (сейчас не важно каких именно).
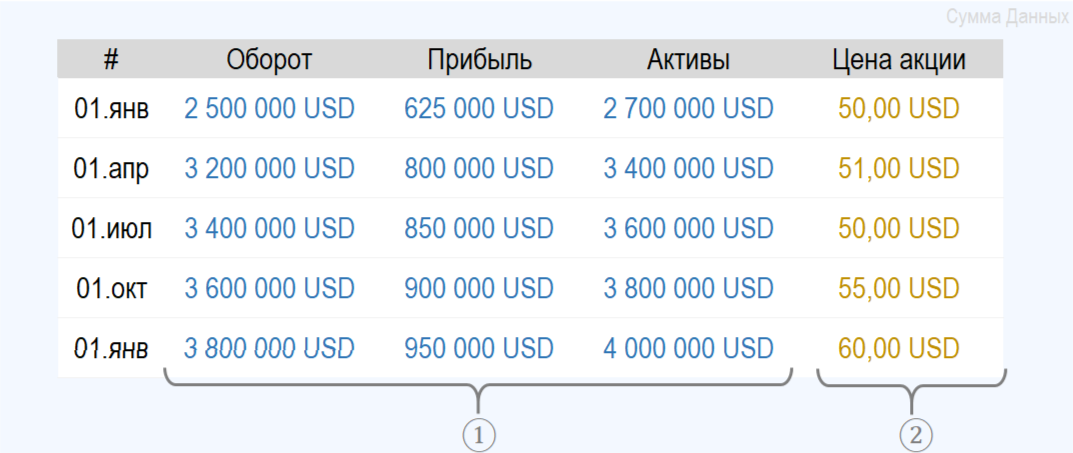
Справа (2) - тоже показатель, но нам бы хотелось его предсказывать, прогнозировать в будущем, зная только показатели слева, например, сразу после выхода квартальной финансовой отчетности. Решение такой задачи на практике может быть крайне востребованным, если вы планируете покупку или продажу акций.
Для того, чтобы понять логику поведения прогнозируемого показателя (справа), необходимо выявить зависимости между ним и теми данными, которые предположительно его объясняют (слева).
Отметим на вертикальной оси (y) Цену акции, а на горизонтальной оси (X) покажем данные о Прибыльности бизнеса. Это позволит увидеть зависимость между двумя показателями.
Очевидно, что зависимость между объясняемым показателем и объясняющими его данными в нашем условном примере - линейная, поскольку при росте прибыли бизнеса, цена акции линейно растет. Линия, проведенная сквозь облако точек данных, наглядно это демонстрирует.
Если мы добавим к объясняющим данным еще один показатель и сделаем визуализацию в трехмерном пространстве, то определить зависимость интуитивно - человеку будет явно сложнее.
Столбцов объясняющих данных может быть 10, 100, 1000... и взаимосвязь между ними и объясняемым показателем окажется в таком случае предельно сложной.
Выявлением подобных сложных зависимостей в бизнесе занимается Machine Learning Engineer / Data Scientist (отличие второго от первого заключается в том, что он занимается более академической, научной работой; первый - более прикладной с точки зрения бизнеса).
В своей ежедневной работе указанные специалисты используют как готовые решения (библиотеки), так и решения, разработанные собственноручно.
К готовым решениям относятся такие популярные библиотеки для машинного обучения как:
- CatBoost (от Яндекс);
- LightGBM;
- TensorFlow (от Google - для построения нейронных сетей);
- Scikit-learn;
- и многие другие.
Рабочий стол Machine Learning Engineer / Data Scientist выглядит примерно следующим образом. Открыт специализированный редактор для кода, в первой строчке которого импортируются нужные для работы библиотеки, например, CatBoost (от Яндекс).
Далее, описывается алгоритм для подготовки наших данных - они разбиваются на "левую" и "правую" части, после чего отправляются в библиотеку при помощи команд на языке программирования Python - для поиска нужных зависимостей между ними. Этот процесс называется обучением модели.
На картинке выше, также видна команда для обучения модели - `model.fit()`.
В том случае, если данных действительно много (сотни Gb), то для машинного обучения потребуются соответствующие вычислительные мощности. Это может быть корпоративный дата-центр, арендованный дата-центр, облачные вычислительные ресурсы как сервис и т.п. Стоимость последних вполне приемлема и может составлять от ~ 20 тыс.руб. в месяц.
На выходе библиотеки машинного обучения появляется некий абстрактный объект, который содержит внутри себя все искомые зависимости между "левой" и "правой" частями исходных обучающих данных.
Абстрактный объект сохраняется во вполне конкретный файл, который и является моделью машинного обучения.
Другими словами, модель машинного обучения - это файл, который содержит зависимости между прогнозируемым показателем и объясняющими его данными.
Если мы ради любопытства откроем получившийся файл в текстовом редакторе, то увидим поток байтов, который описывает нашу абстрактную модель.
Теперь модель машинного обучения готова для использования в прогнозировании нашего искомого показателя. Ее снова необходимо загрузить в библиотеку, а на вход библиотеки подать данные, по которым требуется сделать прогноз. На выходе получим числовой результат.
Подробнее о жизненном цикле моделей машинного обучения в бизнесе можно прочитать тут.
Если материал был вам интересен и/или полезен, не забывайте подписываться на канал и поощрять авторов лайками.