Цепи Маркова — способ моделирующий наступление случайного события который не учитывает события которые уже произошли. Простыми словами — цепи Маркова могут предсказать что будет вне зависимости от того что произошло.
Простой пример на пальцах: «Стоя перед пропастью, он решил прыгнуть» — если разобрать это предложение, то после словосочетания «он решил прыгнуть» понятно что человек прыгает в пропасть и что он труп получит повреждения позвоночника.
Если попросить Цепи Маркова предсказать что будет после словосочетания «он решил прыгнуть» — то результат , скорее всего, будет отличаться он предсказуемого, потому что алгоритм не учитывает факт того что человек стоит перед пропастью, может же он прыгнуть к баскетбольному кольцу, например ?
Теперь более подробнее о том как это работает. В данной статье цепь Маркова рассматривается на примере генерации текста, но использовать ее можно во многих областях. К тому же статья охватывает материал очень поверхностно, в конце приложу ссылки на более глубокий материал.
У нас есть три буквенных выражения:

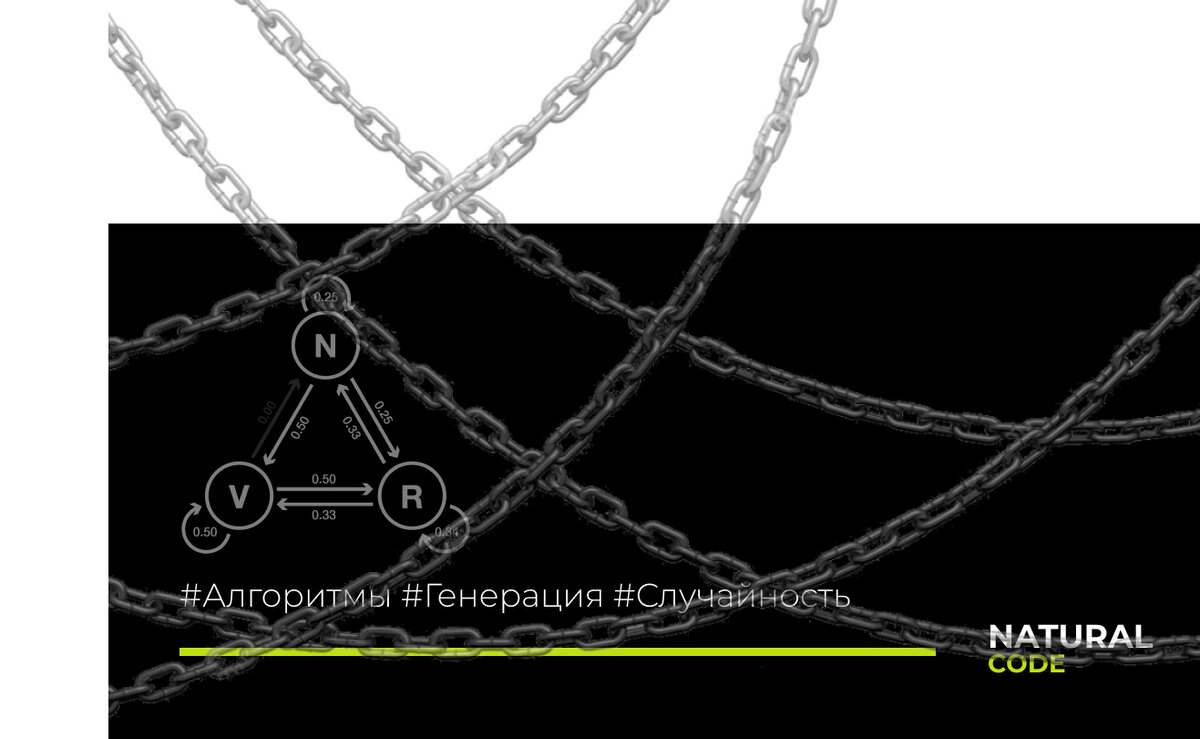
Если каждое выражение разобрать на составляющие, которыми в нашем случае будут слова отделенные пробелами — то мы получим набор слов. Сам по себе он бесполезен, его необходимо обработать для дальнейших действий.
Под обработкой набора я подразумеваю распределение вероятностей. То есть необходимо разобраться — какое слово может идти следующее и с какой вероятностью.
Но для начала нужно определиться с каких слов выражение может начинаться и каким словом оно может заканчиваться.
В нашем случае выражение может начинаться со слов:
А заканчиваться следующими тремя словами:
Для более удобного представления буду показывать данные в формате JSON.
В каждом объекте данного массива атрибуты «canStart» и «canEnd» определяют может ли выражение начинаться с этого слова или заканчиваться соответственно. Теперь мы знаем с какого слова выражение может начинаться и каким заканчиваться, осталось определить какое слово может идти после каждого существующего и с какой вероятностью.
Например после слова «Сто» может идти только слово «Сорок«, таким образом вероятность подбора именно этого слова равно 100%.
А после слов «Сорок» могут идти слова : «Пять, Один, Четыре«, причем с равной вероятностью, т.к количество повторов каждого слова в исходных данные одинаково, следовательно вероятность подбора каждого из этих слов после слова «Сорок» равно 33.3%.
Теперь на основе этих данных можно сгенерировать новые выражения (в нашем случае — числа). Каким образом?
Для начала необходимо случайным или специальным образом выбрать слово с которого выражение может начинаться. У нас таких слов ровно 3 : «Сто, Триста, Пятьсот».
Для примера возьмем слово «Сто», после которого с вероятностью 100% может идти только слово «сорок». Таким образом выражение складывается в «Сто сорок» если слово «сорок» подходит для завершения выражения — завершаем, но оно не подходит :-). Поэтому ищем слова которые могут идти после слова «сорок». Их тоже три: «Один, Пять, Четыре». У каждого из них вероятность одинаковая и каждое из этих слов — завершающее, то есть на нем выражение должно закончится. Таки образом на этом этапе с равной доле вероятности мы может получить 3 выражения:
- Сто сорок пять — оригинальное выражение
- Сто сорок один
- Сто сорок четыре
Ниже представлен генератор, словарь для которого подбирался из следующих новостных заголовков:
На сайте можно посмотреть результат работы генератора в реальном времени: Ссылка на статью