
Переобучение – это случай, когда значение Функции потери (Loss Function) действитеьно малó, но Модель (Model) Машинного обучения (ML) ненадежна. Это связано с тем, что модель «слишком много учится» на обучающем наборе данных.
Когда мы входим в сферу ML, появляются двусмысленные термины: Переобучение, Недообучение (Underfitting) и Дилемма смещения-дисперсии (Bias-Variance Trade-off). Эти концепции лежат в основе Машинного обучения в целом. Почему нам вообще должно быть до этого дело?
Возможно, модели машинного обучения преследуют одну единственную цель: хорошо обобщать.
Обобщение (генерализация) – это способность модели давать разумные предсказания на основе входных данных, которых она никогда раньше не видела.
Обычные программы не могут этого сделать, так как они могут выдавать выходные данные только алгоритмически, то есть на основании вручную определенных опций (например, если зарплата человека меньше определенного порога, банковский алгоритм не предлагает кредит в приложении). Производительность модели, а также ее полезность в целом во многом зависит от ее обобщающей способности. Если модель хорошо обобщает, она служит своей цели. Существует множество методов оценки такой производительности.
Основываясь на этой идее, пере- и недообучение относятся к недостаткам, от которых может пострадать предсказательная способность модели. «Насколько плохи» ее прогнозы – это степень близости ее к пере- или недообучению.
Модель, которая хорошо обобщает, не является ни переобученной, ни недообученной.
Возможно, это пока не имеет большого смысла, но мне нужно, чтобы Вы запомнили это предложение на протяжении всей статьи, так как это общая картина темы.
Пример
Допустим, мы пытаемся построить модель машинного обучения для следующего набора данных:
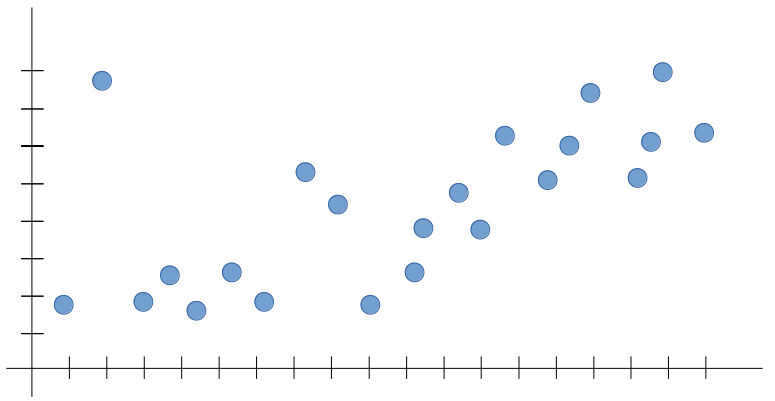
Ось X – это Предикторы (Predictor Variable) – например, площадь дома, а ось Y – Целевая переменная (Target Variable) – стоимость дома. Если у Вас есть опыт обучения модели, Вы, вероятно, знаете, что есть несколько Алгоритмов (Algorithm), однако для простоты в нашем примере выберем одномерную Линейную регрессию (Linear Regression).
Этап обучения
Обучение модели линейной регрессии в нашем примере сводится к минимизации общего расстояния (т.е. стоимости) между линией, которую мы пытаемся проложить, и фактическими точками Наблюдений (Observation). Проходит несколько итераций, пока мы не найдем оптимальную конфигурацию нашей линии. Это именно то место, где происходит пере- и недообучение. Мы хотим, чтобы наша модель следовала примерно такой линии:
Несмотря на то, что общие потери не являются минимальными (т.е. существует лучшая конфигурация, в которой линия может давать меньшее расстояние до точек данных), линия выше очень хорошо вписывается в тенденцию, что делает модель надежной. Допустим, мы хотим знать значение Y при неизвестном доселе модели значении X (т. е. обобщить). Линия, изображенная на графике выше, может дать очень точный прогноз для нового X, поскольку с точки зрения машинного обучения ожидается, что результаты будут следовать тенденции, наблюдаемой в обучающем наборе.
Переобучение
Когда мы запускаем обучение нашего алгоритма на Датасете (Dataset), мы стремимся уменьшить потери (т.е. расстояния от каждой точки до линии) с увеличением количества итераций. Длительное выполнение этого обучающего алгоритма приводит к минимальным общим затратам. Однако это означает, что линия будет вписываться во все точки, включая Шум (Noise), улавливая вторичные закономерности, которые не требуются модели.
Возвращаясь к нашему примеру, если мы оставим алгоритм обучения запущенным на долгое время, он, в конце концов, подгонит строку следующим образом:
Выглядит хорошо, правда? Да, но насколько это надежно? Не совсем. Суть такого алгоритма, как линейная регрессия, состоит в том, чтобы захватить доминирующий тренд и подогнать нашу линию к нему. На рисунке выше алгоритм уловил все тенденции, но не доминирующую. Если мы хотим протестировать модель на входных данных, которые выходят за пределы имеющихся у нас строк (т.е. обобщить), как бы эта линия выглядела? На самом деле нет возможности сказать. Следовательно, результаты ненадежны. Если модель не улавливает доминирующую тенденцию, которую мы все видим (в нашем случае с положительным увеличением), она не может предсказать вероятный результат для входных данных, которых никогда раньше не видела, что противоречит цели машинного обучения с самого начала!
Переобучение – это случай, когда общие потери-затраты действительно невелики, но обобщение модели ненадежно. Это связано с тем, что модель «слишком много учится» на обучающем наборе. Это может показаться абсурдным, но переобучение, или высокая Дисперсия (Variance), приводит к бóльшему количеству плохих, чем хороших результатов. Какая польза от модели, которая очень хорошо усвоила данные обучения, но все еще не может делать надежные прогнозы для новых входных данных?
Недообучение
Мы хотим, чтобы модель совершенствовалась на обучающих данных, но не хотим, чтобы она училась слишком многому (то есть слишком много паттернов). Одним из решений может быть досрочное прекращение тренировки. Однако это может привести к тому, что модель не сможет найти достаточно шаблонов в обучающих данных и, возможно, даже не сможет уловить доминирующую тенденцию. Этот случай называется недообучением:
Это случай, когда модель «недостаточно усвоила» обучающие данные, что приводит к низкому уровню обобщения и ненадежным прогнозам. Как вы, вероятно, и ожидали, такое большое Смещение (Bias) так же плохо для модели, как и переобучение. При большом смещении модель может не обладать достаточной гибкостью с точки зрения подгонки линии, что приводит к чрезмерной упрощенности.
Дилемма смещения-дисперсии
Итак, какова правильная мера? Этот компромисс является наиболее важным аспектом обучения модели машинного обучения. Как мы уже говорили, модели выполняют свою задачу, если хорошо обобщают, а это связано с двумя нежелательными исходами – большим смещением и высокой дисперсией. Это и есть Дилемма смещения-дисперсии. Ответственность за определение того, страдает ли модель от одного из них, полностью лежит на разработчике модели.
Переобучение графически
Давайте посмотрим, как выглядит переобучение в сравнении с остальными сценариями развития. Для начала импортируем необходимые библиотеки:
Сгенерируем датасет – набор точек, "укладывающихся" в параболу:
Добавим Выбросы (Outlier), чтобы сделать данные шумнее и реалистичнее, а демонстрацию концепции нагляднее:
Усложним алгоритму задачу еще и сгруппируем записи в две группы:
Настал черед отобразить переобучение на графике. Построим три таких, первый – недообучение, второй – адекватное обучение, третий – переобучение. Обратите внимание на уравнения, описывающие положение точек: в первом случае, модель опишет набор линейным уравнением underfit = (m * x + c), во втором – кубическим goodfit = (a * x ** 2 + m * x + c), то есть подходящем параболе. В третьем случае мы попробуем описать точки кривой overfit = np.poly1d(fit).
Теперь разница между сценариями наглядна:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Фото: @kalenemsley
Автор оригинальной статьи: Anas Al-Masri, Carl McBride Ellis
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курс «Введение в Машинное обучение» на Udemy.