Для понимания правил работы с текстом при программировании необходимо отойти от стандартного взгляда, предполагающего его однозначное представление в некой кодировке, а принять многоликость в зависимости от угла обзора.
Так, например, в ходе написания скрипта на языке Python вы можете столкнуться с тремя интерпретациями текста:
- кодировка в файле с исходным кодом
- отображение в редакторе вашей среды программирования
- восприятие текста интерпретатором
При этом все эти "версии" могут быть различными. Например, кодировка в файле с исходным кодом при работе со средой PyCharm по умолчанию - UTF-8 (задается в настройках). В этом можно убедиться, открыв файл 2.py:

в онлайн hex-viewer-е, например, здесь:
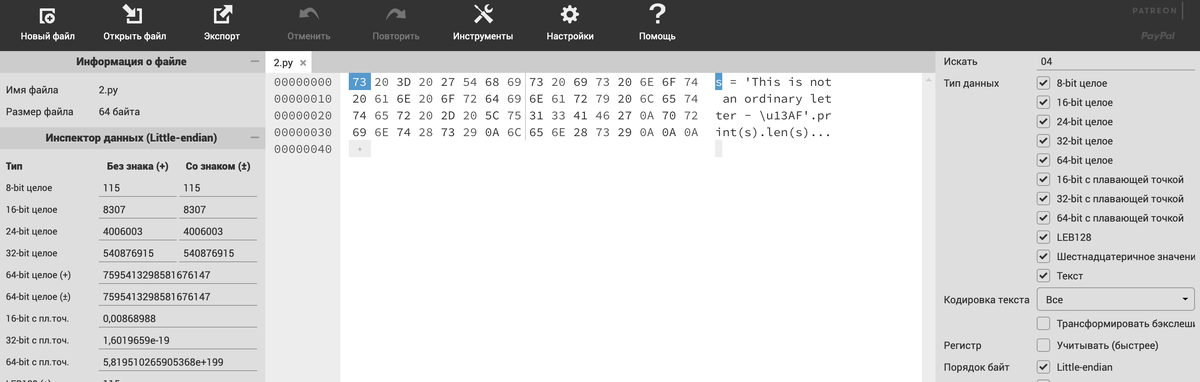
При этом в самом редакторе не все символы отображаются, например, пробел с кодом \x20.
Особняком стоит восприятие текста интерпретатором Python. Например, в Python 3 строки имеют формат Unicode. Это международный стандарт, закрепляющий уникальный номер за каждым символом независимо от платформы.
Интерпретатор Python 3, работая с Unicode, позволяет задавать символы в виде кодов из двух байтов через \u (по два 16-ых числа на каждый) или четырех - \U.
Следует отметить, что Unicode является некой абстракцией для удобной работы, в реальности же символы данного формата хранятся и передаются в связанных с ним кодировках, например, UTF-8, UTF-16, которые используют более оптимальное, но сильно схожее представление.
Так, UTF-8 для кодировки символа Unicode использует от одного до четырех байтов - один для символов ASCII, два для большинства языков, основанных на латинице, три и четыре байта для остальных языков. Сравните Unicode и UTF-8 на примерах:
А для непечатаемого символа End-of-Transmission Unicode состоит из двух байтов, а UTF-8 - одного:
В отличие от Python 3 в предыдущей версии интерпретатора строки рассматривались как последовательности байтов, сравните:
Python 3:
Python 2:
В Python 3 последний символ имеет длину - 1, в то время как в предшествующей версии каждый из символов \u13AF кодируется одним байтом.
Функции для работы с кодировками
Закодировать строку можно с помощью метода encode:
В целом можно задавать следующие кодировки:
ascii, utf-8, latin-1 (ISO 8859-1), cp-1252 (стандартная кодировка Windows)
encode принимает второй аргумент, который определяет реакцию на отсутствие символа в кодировке:
'strict' (по умолчанию) - возникает исключение
'ignore' - игнорировать
'replace' - заменять на ?
Для декодирования строки предназначен метод decode:
Полезные функции для работы с Unicode имеются в модуле unicodedata:
- lookup получает имя и возвращает отображение символа Unicode;
- name получает код Unicode и возвращает имя.