Обработка данных в информационных системах чаще всего проводится в три этапа: извлечение, трансформация и загрузка (Extract Transform Load, ETL). В решениях, использующих Big Data, именно с помощью ETL исходные («сырые») данные преобразуются в информацию, пригодную для бизнес-анализа.

Однако с увеличением данных и усложнением аналитических задач увеличивается и количество ETL-процессов, которые необходимо планировать, отслеживать и перезапускать в случае сбоев — возникает необходимость в оркестраторе.
В статье расскажем об эффективном Open-Source инструменте Apache Airflow, который помогает в управлении сложными ETL-процессами и отлично сочетается с принципами Cloud-Native приложений.
Основные сущности AirFlow
Процессы обработки данных, или пайплайны, в Airflow описываются при помощи DAG (Directed Acyclic Graph). Это смысловое объединение задач, которые необходимо выполнить в строго определенной последовательности согласно указанному расписанию. Визуально DAG выглядит как направленный ациклический граф, то есть граф, не имеющий циклических зависимостей.
В качестве узлов DAG выступают задачи (Task). Это непосредственно операции, применяемые к данным, например: загрузка данных из различных источников, их агрегирование, индексирование, очистка от дубликатов, сохранение полученных результатов и прочие ETL-процессы. На уровне кода задачи могут представлять собой Python-функции или Bash-скрипты.
За реализацию задач чаще всего отвечают операторы (Operator). Если задачи описывают, какие действия выполнять с данными, то операторы — как эти действия выполнять. По сути, это шаблон для выполнения задач.
Особую группу операторов составляют сенсоры (Sensor), которые позволяют прописывать реакцию на определенное событие. В качестве триггера может выступать наступление конкретного времени, получение некоторого файла или строки с данными, другой DAG/Task и так далее.
В AirFlow богатый выбор встроенных операторов. Кроме этого, доступно множество специальных операторов — путем установки пакетов поставщиков, поддерживаемых сообществом. Также возможно добавление пользовательских операторов — за счет расширения базового класса BaseOperator. Когда в проекте возникает часто используемый код, построенный на стандартных операторах, рекомендуется его преобразование в собственный оператор.
Примеры операторов приведены ниже.
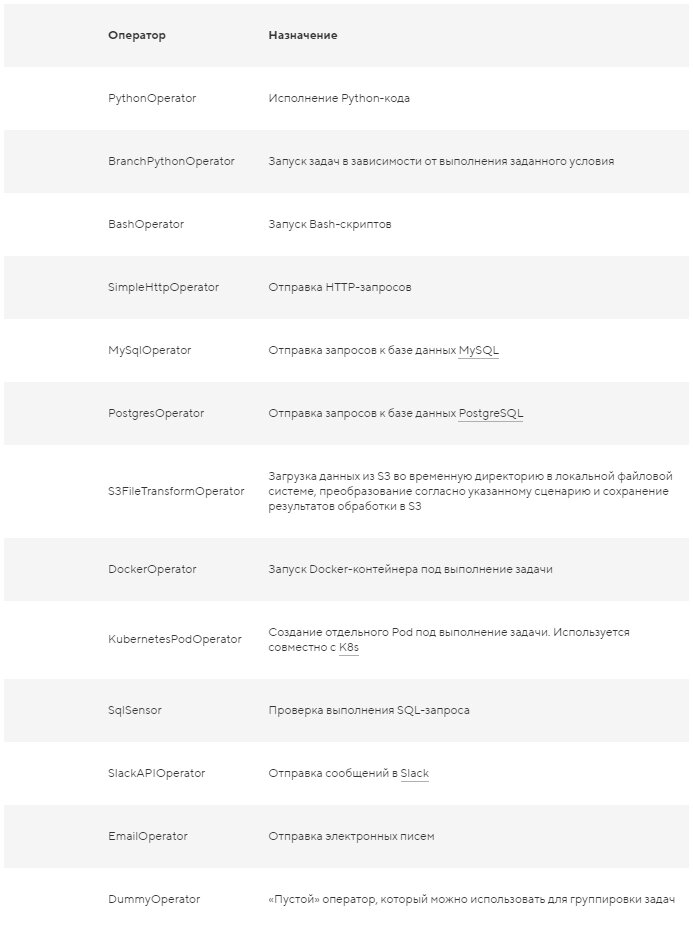
Примечание
Наряду с операторами в последних версиях AirFlow появилась возможность оформления задач в виде TaskFlow — путем объединения задач в цепочки для передачи выходных данных вышестоящим задачам и операторам.
Рассмотрим различия между DAG, Task и Operator на простом примере. Предположим, есть база данных MySQL и необходимо отслеживать появление некоторых данных в одной из ее таблиц. При появлении этих данных нужно выполнить их агрегацию и сохранение в хранилище Apache Hive, после чего отправить почтовое уведомление определенным адресатам.
DAG для этого примера может состоять из трех узлов:
Каждому из них будет соответствовать задача, а за ее выполнение, в свою очередь, будет отвечать оператор. Перечень задач и возможных операторов для их реализации отражает таблица ниже.
Еще одна важная концепция, лежащая в основе AirFlow — это хранение информации о каждом запуске DAG в соответствии с указанным расписанием. Так, если в нашем примере указать, что DAG должен запускаться начиная с 07.05.2021 00:00:00 раз в сутки — AirFlow будет хранить информацию о запуске экземпляров DAG для следующих временных отметок: 07.05.2021 00:00:00, 08.05.2021 00:00:00, 09.05.2021 00:00:00 и так далее. Временные отметки при этом называются execution_date, соответствующие им экземпляры DAG — DAG Run, а связанные с конкретными DAG Run экземпляры задач — Task Instance.
Концепция execution_date очень важна для соблюдения идемпотентности: запуск или перезапуск задачи за какую-то дату в прошлом никак не зависит от времени фактического выполнения. Это позволяет точно воспроизводить результаты, полученные ранее. Кроме этого, возможен одновременный запуск задач одного DAG за различные временные отметки (нескольких Dag Run).
Архитектура AirFlow и принципы его работы
Основу архитектуры AirFlow составляют следующие компоненты:
- Web Server — отвечает за пользовательский интерфейс, где предоставляется возможность настраивать DAG и их расписание, отслеживать статус их выполнения и так далее.
- Metadata DB (база метаданных) — собственный репозиторий метаданных на базе библиотеки SqlAlchemy для хранения глобальных переменных, настроек соединений с источниками данных, статусов выполнения Task Instance, DAG Run и так далее. Требует установки совместимой с SqlAlchemy базы данных, например, MySQL или PostgreSQL.
- Scheduler (планировщик) — служба, отвечающая за планирование в Airflow. Отслеживая все созданные Task и DAG, планировщик инициализирует Task Instance — по мере выполнения необходимых для их запуска условий. По умолчанию раз в минуту планировщик анализирует результаты парсинга DAG и проверяет, нет ли задач, готовых к запуску. Для выполнения активных задач планировщик использует указанный в настройках Executor.
Для определенных версий БД (PostgreSQL 9.6+ и MySQL 8+) поддерживается одновременная работа нескольких планировщиков — для максимальной отказоустойчивости. - Worker (рабочий) — отдельный процесс, в котором выполняются задачи. Размещение Worker — локально или на отдельной машине — определяется выбранным типом Executor.
- Executor (исполнитель) — механизм, с помощью которого запускаются экземпляры задач. Работает в связке с планировщиком в рамках одного процесса. Поддерживаемые типы исполнителей приведены ниже.
Взаимодействие компонентов AirFlow в общем случае можно описать следующей схемой. В зависимости от типа, выбранного Executor на схеме, могут использоваться дополнительные компоненты, например, очередь сообщений для CeleryExecutor.
Плюсы и минусы AirFlow
Чаще всего выделяют следующие преимущества AirFlow:
- Открытый исходный код. AirFlow активно поддерживается сообществом и имеет хорошо описанную документацию.
- На основе Python. Python считается относительно простым языком для освоения и общепризнанным стандартом для специалистов в области Big Data и Data Science. Когда ETL-процессы определены как код, они становятся более удобными для разработки, тестирования и сопровождения. Также устраняется необходимость использовать JSON- или XML-конфигурационные файлы для описания пайплайнов.
- Богатый инструментарий и дружественный UI. Работа с AirFlow возможна при помощи CLI, REST API и веб-интерфейса, построенного на основе Python-фреймворка Flask.
- Интеграция со множеством источников данных и сервисов. AirFlow поддерживает множество баз данных и Big Data-хранилищ: MySQL, PostgreSQL, MongoDB, Redis, Apache Hive, Apache Spark, Apache Hadoop, объектное хранилище S3 и другие.
- Кастомизация. Есть возможность настройки собственных операторов.
- Масштабируемость. Допускается неограниченное число DAG за счет модульной архитектуры и очереди сообщений. Worker могут масштабироваться при использовании Celery или Kubernetes.
- Мониторинг и алертинг. Поддерживается интеграция с Statsd и FluentD — для сбора и отправки метрик и логов. Также доступен Airflow-exporter для интеграции с Prometheus.
- Возможность настройки ролевого доступа. По умолчанию AirFlow предоставляет 5 ролей с различными уровнями доступа: Admin, Public, Viewer, Op, User. Также допускается создание собственных ролей с доступом к ограниченному числу DAG. Дополнительно возможна интеграция с Active Directory и гибкая настройка доступов с помощью RBAC (Role-Based Access Control).
- Поддержка тестирования. Можно добавить базовые Unit-тесты, которые будут проверять как пайплайны в целом, так и конкретные задачи в них.
Разумеется, есть и недостатки, но связаны они по большей части с довольно высоким порогом входа и необходимостью учитывать различные нюансы при работе с AirFlow:
- При проектировании задач важно соблюдать идемпотентность: задачи должны быть написаны так, чтобы независимо от количества их запусков, для одних и тех же входных параметров возвращался одинаковый результат.
- Необходимо разобраться в механизмах обработки execution_date. Важно понимать, что корректировки кода задач будут отражаться на всех их запусках за предыдущее время. Это исключает воспроизводимость результатов, но, с другой стороны, позволяет получить результаты работы новых алгоритмов за прошлые периоды.
- Нет возможности спроектировать DAG в графическом виде, как это, например, доступно в Apache NiFi. Многие видят в этом, напротив, плюс, так как ревью кода проводится легче, чем ревью схем.
- Некоторые пользователи отмечают незначительные временные задержки в запуске задач из-за нюансов работы планировщика, связанных с накладными расходами на постановку задач в очередь и их приоритезацию. Однако в версии Airflow 2 подобные задержки были сведены к минимуму, а также появилась возможность запуска нескольких планировщиков для достижения максимальной производительности.
AirFlow и Cloud-Native подход
Использование локальной инфраструктуры для работы с Big Data часто оказывается дорогим и неэффективным: под задачи, занимающие всего несколько часов в неделю, требуются огромные вычислительные мощности, которые необходимо оплачивать, настраивать и поддерживать. Поэтому многие компании переносят обработку больших данных в облако, где за считаные минуты можно получить полностью настроенный и оптимизированный кластер обработки данных с посекундной оплатой — за фактически используемые ресурсы.
Еще одна причина, по которой работать с BigData предпочтительнее в облаке — возможность использования Kubernetes aaS. Главные преимущества работы с Big Data в Kubernetes — это гибкое масштабирование и изоляция сред. Первое позволяет автоматически изменять выделяемые в облаке ресурсы в зависимости от меняющихся нагрузок, второе — обеспечивает совместимость различных версий библиотек и приложений в кластере за счет контейнеризации.
Если вы хотите разобраться в работе с большими данными в Kubernetes aaS, вам будут интересны эти статьи на Хабре:
Так как AirFlow предназначен для оркестровки ETL-процессов в области Big Data и Data Science — его запуск возможен и даже рекомендован в облаке. Также AirFlow отлично сочетается с Kubernetes. Способы запуска Airflow в Kubernetes кратко упоминались выше — опишем их подробнее:
- С помощью оператора KubernetesPodOperator — в этом случае в Kubernetes выносятся только некоторые Airflow-задачи, которым сопоставлен соответствующий оператор. На каждую задачу внутри Kubernetes будет создан отдельный под. В качестве Executor при этом может использоваться стандартный CeleryExecutor.
- С помощью исполнителя Kubernetes Executor — в этом случае на каждую Airflow-задачу будет создан отдельный Worker внутри Kubernetes, который при необходимости будет создавать новые поды. Если одновременно использовать KubernetesPodOperator и Kubernetes Executor, то сначала будет создан первый под — Worker, а затем он создаст следующий под и запустит на нем Airflow-задачу.
Метод хорош тем, что создает поды только по требованию, тем самым экономя ресурсы и давая масштабироваться по мере необходимости. Однако нужно учитывать задержки в создании новых подов. Поэтому при большом количестве задач, работающих всего несколько минут, лучше использовать CeleryExecutor, а наиболее ресурсоемкие задачи выносить в Kubernetes с помощью KubernetesPodOperator. - С помощью исполнителя CeleryKubernetes Executor — в этом случае могут совместно использоваться CeleryExecutor и KubernetesExecutor. Метод рекомендуется использовать в трех случаях:Есть много небольших задач, которые могут быть выполнены в CeleryExecutor, но также есть ресурсоемкие задачи, требующие KubernetesExecutor.
Относительно малое количество задач требует изолированной среды.
Предполагаемые пиковые нагрузки значительно превышают возможности Kubernetes-кластера.
Подробнее о Kubernetes aaS на платформе Mail.ru Cloud Solutions в этой статье на хабре.
Кому подойдет AirFlow
Конечно, AirFlow — далеко не единственное подобное решение на IT-рынке. Существует множество других инструментов для планирования и мониторинга ETL-процессов — как платных, так и Open-Source. В самых простых случаях можно и вовсе обойтись стандартным планировщиком Cron, настраивая рабочие процессы через Crontab. Назовем ряд типовых сценариев, когда AirFlow может стать наилучшим выбором:
- Для планирования задач недостаточно возможностей Cron — требуется автоматизация.
- У команды уже есть достаточная экспертиза в программировании на Python.
- На проекте используется пакетная обработка данных (Batch), а не потоковая (Stream). AirFlow предназначен для Batch-заданий, для потоковой обработки данных лучше использовать Apache NiFi.
- Для задач, используемых на проекте, возможно определить зависимости, представив их в виде графа DAG.
- Планируется или уже осуществлен переход в облако и необходим надежный оркестратор, поддерживающий все принципы Cloud-Native.
Источник: https://mcs.mail.ru/blog/airflow-what-it-is-how-it-works
Автор: Дарья Барышева
Читайте также статьи по теме:
Как устроен Kubernetes as a Service на платформе Mail.ru Cloud Solutions
Mail.ru Cloud Solutions запускает облачный сервис для обработки большого потока запросов
Не терять клиентов и быстрее обрабатывать запросы пользователей: зачем нужны очереди сообщений в ритейле, видео- и фотохостингах, онлайн-школах и банках