Часто данные в датасетах бывают разного масштаба, что очень мешает алгоритмам хорошо работать. В большинстве случаев прибегают к нормализации данных - приведению данных к одному масштабу.
Основные методы:
- minmax нормализация
- std нормализация
Два этих метода есть в библиотеке sklearn.
MinMaxScaler - приводит независимо каждый признак к значению между 0 и 1. Для каждого признака мы находим минимальное и максимальное значение, из всех значений вычитаем минимальное значение и делим это на разницу между максимальным и минимальным значениями.
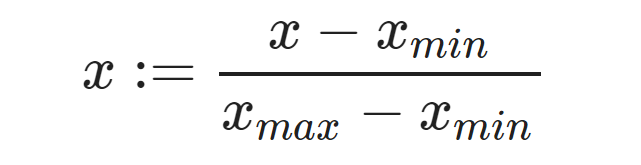
StandardScaler - находит среднее значение для признака, затем стандартное отклонение, из каждого значения в текущем признаке вычитаем среднее значение для всего признака и делим на стандартное отклонение.
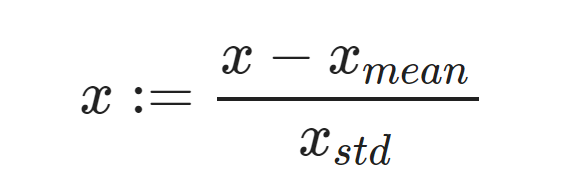
Создадим тестовые датасет и посмотрим на него:
Перед тем как мы займёмся нормализацией данных, заполним пропуски нулями:
Теперь посмотрим на сами методы нормализации и что получим после их применения:
Сначала загружаем библиотеку и определенный метод из неё. Затем применяем его к датасату.
P.S. На основе конспектов из магистратуры. Если, нашли ошибки, недочёты или хотите дополнить сказанное, всегда рада конструктивному мнению специалистов.