Рассказываем на реальных примерах Netflix, Тинькофф, GitHub и других компаний, как одна технология помогает оптимизировать поиск по сайту, организовать мониторинг бизнес-показателей, обрабатывать неструктурированные сообщения сторонних систем и текстовые журналы, метрики сетевых, IoT и других устройств.

Сегодня компании генерируют всё больше данных, и стандартные системы хранения и привычные инструменты обработки перестают справляться с их объемами. При этом требования к скорости и качеству поиска и анализа информации на сайте или в приложении, в аналитике сервисов и серверов, только растут. Решить такую задачу можно с помощью Elasticsearch.
Справочная: что такое Elasticsearch
Elasticsearch (ES) – поисковая система с открытым исходным кодом, которая позволяет в режиме реального времени искать и анализировать данные в нереляционном хранилище. Elasticsearch – ядро экосистемы Elastic Stack, в состав которой также входят Logstash, Kibana и Beats.
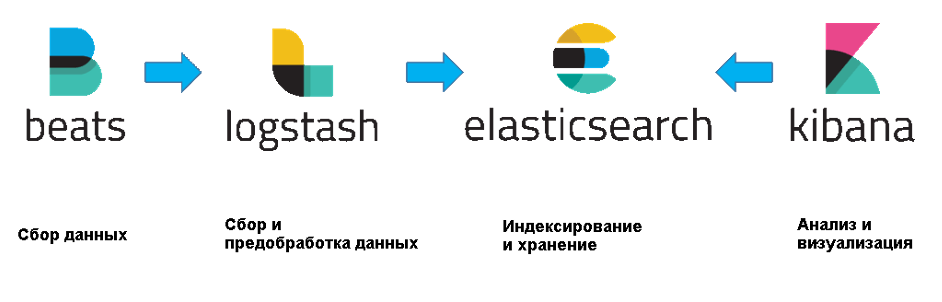
Экосистема Elastic Stack состоит из сервисов, которые помогают собрать разнородные данные в едином хранилище и визуализировать результаты.
- Beats – это компактные агенты для сборки и доставки данных в Elasticsearch или Logstash.
- Logstash – это инструмент для сбора событий из разных источников, их преобразования и отправки в Elasticsearch.
- Kibana – веб-интерфейс для визуализации данных в реальном времени.
ES легко масштабируется и обладает высокой отказоустойчивостью. Когда речь идет о действительно больших объемах данных, многие системы не справляются с индексацией и поиском, и возникает вопрос масштабирования как инфраструктуры, так и сервисов. В Elasticsearch горизонтальное масштабирование реализовано на уровне архитектуры, поэтому в кластер можно «на лету» добавлять сервера, а сервис сам перераспределит нагрузку. Elasticsearch хранит данные в структуре, называемой индексом. Он автоматически распределяется по узлам кластера, а при сбое одного из них — перераспределяется на оставшиеся, используя внутренний механизм репликации данных.
Кластер Elasticsearch можно развернуть и на физических серверах, и в облачных средах.
Для установки и администрирования кластеров ES на физических серверах требуются технические специалисты для конфигурирования, мониторинга и поддержания инфраструктуры.
Развертывание Elasticsearch на виртуальных машинах в облаке позволяет сократить время запуска и трудозатраты. Например, в Облачной платформе Google, Amazon Web Services, Microsoft Azure, Yandex.Cloud можно запустить ES с помощью Elastic Cloud Enterprise – решения для централизованной оркестрации кластеров ES с единой панелью управления и мониторинга.
Однако, наиболее простой способ запуска кластера Elasticsearch – управляемый сервис. Облачные платформы позволяют создать кластер ES с оптимальной конфигурацией в несколько кликов, и при этом не нужно заниматься обновлением программного обеспечения, резервным копированием, мониторингом или обеспечением отказоустойчивости и безопасности. При изменении нагрузки на инфраструктуру масштабирование происходит автоматически и без простоев. Кроме того, клиентам не нужно настраивать интеграции между Elasticsearch и сторонними сервисами или сервисами самой платформы. А также всегда доступны инструменты для оперативного реагирования и управления кластером. Эту услугу предоставляет, например, Yandex.Cloud.
Под капотом: что позволяет Elasticsearch эффективно работать с текстом?
Elasticsearch позволяет качественно и быстро обрабатывать текст, в том числе при полнотекстовом поиске по всем выражениям во всех документах базы данных. Здесь можно привести в пример Яндекс или Google. Вы ввели запрос и система поиска начинает анализировать все страницы в интернете без исключения, а не ищет абсолютно точное или универсальное совпадение с вашим запросом. Elasticsearch также анализирует и сохраняет все данные. Как это происходит?
Основой для работы с текстовыми документами является анализатор. Он представляет собой цепочкупоследовательных обработчиков.
Сначала поступивший в анализатор текст проходит символьные фильтры, которые убирают, добавляют или заменяют отдельные символы в потоке. Например, с их помощью можно заменить арабские цифры (٠ ١٢٣٤٥٦٧٨ ٩) на современные арабские цифры (0123456789), перевести текст в нижний регистр или удалить html-теги.
Обработанный текст передается токенизатору, где поток символов очищается от знаков препинания и разбивается по определенным правилам на отдельные слова. Его выбор является ключевым для результата анализа: он сегментирует текст на токены по пробелам или другим символам, а затем формирует из них набор слов или основ слов (например, корней).
Полученный набор попадает в один или несколько фильтров токенов. Они могут добавлять, удалять или менять слова. Например, фильтры могут удалять часто используемые служебные слова, такие как артикли «a» и «the» в англоязычном тексте. После всех преобразований на выходе из анализатора мы имеем набор, который сохраняется в индексе Elasticsearch. Этот процесс позволяет сохранять максимум смысла при минимуме объема знаков.
Поиск слов из запроса Elasticsearch осуществляет уже по индексу. В зависимости от выбора способа поиска текст запроса может быть как предварительно проанализирован, так и нет, а сам поиск может быть как поиском по точному совпадению, так и нечетким.
Как компании применяют Elastic Stack в системах Big Data?
Для полнотекстового поиска по сайту
Stack Overflow использует Elasticsearch как средство для полнотекстового поиска по вопросам и ответам для пользователей, а также для поиска похожих вопросов и подсказок при создании нового вопроса. С его помощью сервис предоставляет как поиск по точному совпадению (для строки кода), так и нечёткий поиск с большим количеством настроек. Например, можно отдельно искать только по вопросам или только по ответам, по вопросам с заданным количеством ответов, по определенным тегам, автору, или оценке вопроса.
Благодаря Elasticsearch GitHub обеспечивает пользователям как полнотекстовый поиск, так и поиск по отдельным критериям по 8 миллионам репозиториев кода. Например, можно найти проект на языке Clojure, который при этом был активен в течение последнего месяца.
Альфа-Банк применяет Elasticsearch для полнотекстового поиска по транзакциям в личном кабинете и в сервисе «выписка по счёту».
Для хранения и анализа журналов
Elasticsearch позволяет централизованно хранить и обрабатывать системные журналы, статистику по аутентификации, метрики оборудования, журналы веб-серверов, серверов приложений, баз данных. Например, для обработки многочисленных журналов он используется такими организациями, как Netflix, ДомКлик, Medium.
Однажды Эдриан Кокрофт, бывший тогда облачным архитектором Netflix, пошутил, что «Netflix — это компания, генерирующая файлы журналов, которая также занимается потоковым вещанием фильмов». Еще в 2015 году конвейер данных Netflix обрабатывал 500 миллиардов событий в день. Это действия, связанные с просмотром видео, использованием интерфейса, журналы ошибок, производительности, события по диагностике и устранению неполадок – в общей сложности 1,3 петабайта данных. Для хранения, поиска и анализа этих данных используется Elasticsearch. За два года после начала внедрения инфраструктура доросла до 150 кластеров с суммарно более чем 3500 инстансами.
ДомКлик организовали кластер логирования на производительных физических серверах с помощью Elasticsearch. Задача кластера – агрегация и поиск по журналам более 2000 приложений, запущенных в кластере Kubernetes. Благодаря точной настройке Elasticsearch и конфигурированию Logstash система обрабатывает 4.4 ТБ данных в сутки.
Одна из популярных современных платформ для публикации статей, Medium, использует Elastic Stackдля обнаружения проблем в работе системы управления базами данных DynamoDB и для отладки.
Для поиска по продуктам
Leroy Merlin в России создали поиск по продуктам с нуля. Компании требовался адаптированный для русского языка поиск по товарам, их доступности и ценам. Эти данные агрегируются, форматируются и записываются в индекс Elasticsearch. При поиске товара на сайте или в мобильном приложении, созданный компанией продукт search engine ищет товары в индексе ES, затем данные ранжируются с помощью ML-алгоритмов и выдаются на странице.
Кроме того, на базе индекса Elasticsearch была реализована быстрая выдача каталога и сервис поисковых подсказок. С момента запуска сервиса количество товаров в индексе увеличилось в два раза и продолжает расти. В среднем пользователи делают 300 поисковых запросов в секунду, но несмотря на это, время отклика составляет меньше 200 миллисекунд.
Для визуализации и анализа показателей
Тинькофф предоставляет мониторинг как сервис для более чем 200 команд компании – сотрудники загружают файлы журналов, могут использовать свои метрики и следить за показателями собственных систем. Продукт построен на основе Elasticsearch и кроме поиска позволяет строить дашборды и настраивать оповещения, а также отслеживать инфраструктурные и бизнес-показатели.
Каждую секунду в сервис поступает 1ГБ данных с балансировщиков, гипервизоров и коммутаторов, информации о состоянии биржи или платежей, пользовательских инцидентах. Все поступившие журналы хранятся в индексах Elasticsearch. Для удобства пользователей в компании разработали собственный язык запросов, а процессингом и валидацией данных занимаются собственные приложения. Эти решения позволили реализовать поиск, оповещения, создание дашбордов с аналитикой как сервис одного окна.
Elasticsearch хорошо подходит как для больших, высоконагруженных сервисов, так и для небольших проектов, в которых постоянно растут объемы данных и поисковых запросов. Высокое качество и скорость полнотекстового поиска, инструменты для сбора и анализа данных, сделали Elasticsearch одним из самых популярных в мире продуктов среди поисковых систем.
Если статья оказалась полезной, ставьте 👍
Не забывайте подписываться на наши соцсети: Вконтакте, Facebook, Telegram, VC, YouTube.



















