В процессе обучения нейросети вы можете допустить ошибки при разделении данных на тренировочные и проверочные. Из-за этого возникнет вероятность того, что модель слишком остро среагирует на сложные связи между входом и выходом. В результате вы получите очень неточную в прогнозах нейронную сеть, которая будет далека от внедрения в реальные рабочие процессы.
Поздравляем, вы перетренировали модель. Как и в случае с мышцами, это не есть хорошо. Разбираемся в причинах этого явления и рассказываем, как его избежать.

Что такое перетренировка модели
Эффект перетренировки или переобучения - одна из наиболее частых проблем при создании моделей на основе нейронных сетей. Она возникает, когда вы загрузили слишком много "входов" или "выходов" для нейронной сети и у вас при этом недостаточно ценовой истории (слишком малый период котировок; маловато баров для анализа).
Разберем на конкретном примере. Вы загрузили ценовую историю DJIA с 1885 по 2011 год. Она включает около 35 000 ценовых баров. Мы можем создать нейронку с 10 000 входами.
Соотношение между количеством ценовых баров и количеством входов в нашей нейронной сети составляет 2.8 (35 000 ценовых баров делим на 10 0000 входов). Это значение слишком низкое. Входов слишком много и это вызывает чрезмерный тренировочный эффект.
Отлично иллюстрирует перетренированность следующая диаграмма:
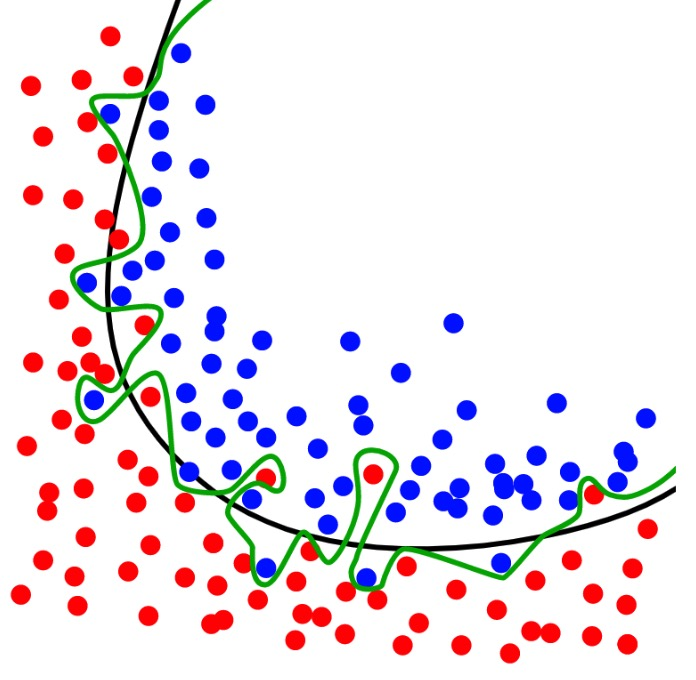
Красные и синие точки представляют обучающие выборки, классифицируемые нейросетью.
Черная линия представляет собой хорошую стратегию классификации. Она следует общему шаблону, который отделяет красный от синего, и должна в теории привести к самой низкой ошибке в реальных данных.
Зеленая линия – это перетренированная стратегия классификации. Она слишком хорошо следует обучающим данным: в своей попытке идеально классифицировать обучающие выборки, она создала связь вход-выход, которая является менее обобщенной и, следовательно, менее подходящей для реальных данных.
Довольно часто этот эффект называют GIGO (Garbage In, Garbage Out, «Мусор на входе — мусор на выходе»).
Как понять, что ваша модель перетренирована
Прежде всего - не радоваться выдающимся показателям. Например, если у вас отличная корреляция, под 100%, на данных до LBC - это повод всё перепроверить.
На первом рисунке мы видим умеренно обученную модель, а на втором - перетренированную. Оранжевая линия справа - контрольная подсказка, которую называют корреляционной ловушкой.
Вы также можете использовать различные инструменты. Например, Weightwatcher, который может обнаруживать признаки перетренированности в определенных слоях предварительно обученных глубоких нейронных сетей.
Weightwatcher - это диагностический инструмент с открытым исходным кодом для анализа глубоких нейронных сетей (DNN) без необходимости доступа к обучающим или даже тестовым данным. Он анализирует весовые матрицы предварительно / обученного DNN, слой за слоем, чтобы помочь вам обнаружить потенциальные проблемы. Проблемы, которые нельзя увидеть, просто посмотрев на точность теста или потери в обучении.
Установка Weightwatcher:
pip install weightwatcher
Запуск:
Для каждого слоя Weightwatcher строит эмпирическую спектральную плотность или ESD. Это просто гистограмма собственных значений матрицы слоя корреляции:
Указывая опцию рандомизации, Weightwatcher рандомизирует элементы весовой матрицы W, а затем вычисляет ее ESD. Этот рандомизированный ESD накладывается на исходный ESD X и наносится на график в логарифмической шкале. Пример выше:
- исходный слой ESD - зеленый;
- рандомизированный ESD - красный;
- оранжевая линия - наибольшее собственное значение λ{max} рандомизированного ESD.
Если слой в меру обучен, то рандомизированный W будет отображать корректное ESD. Если же слой переобучен, тогда W может иметь необычно большие элементы, из-за чего корреляции могут концентрироваться или застревать. Это показано на втором рисунке с оранжевой линией, идущей к дальнему правому краю основной части красного ESD.
Обратите внимание, что первом рисунке у ESD очень тяжелые хвосты, а гистограмма расширяется до log10 = 2 или доходит до наибольшего собственного значения 100:
Но на втором рисунке зеленый ESD имеет совершенно другую форму и меньше по масштабу, чем на первом. Фактически, в во втором случае зеленый (исходный) и красный (рандомизированный) слои ESD выглядят почти одинаково, за исключением небольшого участка зеленых собственных значений, простирающихся до оранжевой линии и концентрирующиеся вокруг нее.
В таких случаях мы можем воспринимать оранжевую линию как корреляционную ловушку. Следовательно, что-то пошло не так при обучении этого слоя, и модель не зафиксировала корреляции, чтобы хорошо работать с другими примерами.
Заключение
Теперь вы знаете, что такое переобучение модели. Как в случае с тренажерным залом, перетренировка не сулит ничего хорошего и в случае машинного обучения может пустить коту под хвост часы работы.
Чтобы не переделывать всё с нуля, мы советуем чаще проверять все промежуточные этапы и настороженно относится к чересчур впечатляющим показателям.
Мы надеемся, что статья была для вас полезна. Сталкивались ли вы с перетренировкой модели и как пофиксили проблему? Пишите в комментариях.
Другие наши статьи:
Наши соцсети:
