Технологии искусственного интеллекта с каждым днем становятся всё актуальнее. Их внедряют в самые разные сферы жизни: от наложения масок в Instagram до выявления различных болезней. И, если все мы можем оценить конечный результат, то закулисье нейронок обычно остаётся в тени.
Мы - компания LabelMе, хотим исправить это. Наши специалисты расскажут, из чего состоит тот самый ИИ, как его изготовить и как применять в решении реальных бизнес-задач.
Начать хотим с фундамента любой нейронной сети - обучающего датасета.

Что такое датасет и зачем он нужен?
Dataset – это обработанная и структурированная информация в табличном виде. Строки такой таблицы называются объектами, а столбцы – признаками. В совокупности это и есть размеченные данные, на основе которых происходит машинное обучение.
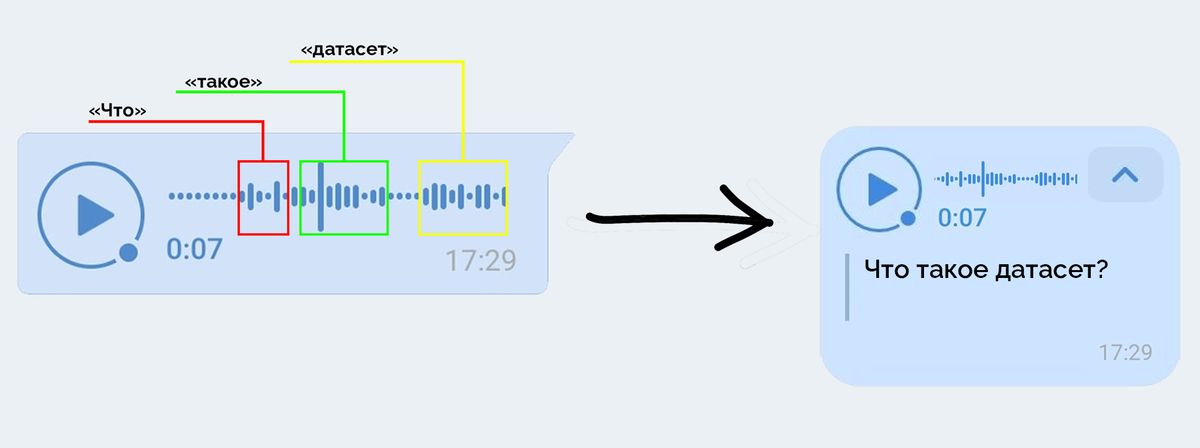
Данные могут быть самыми разными. Например, вы хотите снабдить своё приложение голосовым поиском. Для этого нейронке нужно скормить набор данных с транскрипцией живой речи. Чтобы ИИ не тупил и понимал запросы как можно лучше - нужно очень много подробных примеров. Каждый пример - фрагмент аудиозаписи речи, отмеченные в ней фрагменты и перевод, о чём там говорится.
Под разные задачи есть разные виды разметки данных:
- выделение объектов (2D и 3D),
- сегментация объектов,
- категоризация изображений,
- классификация текстов,
- транскрипция рукописного текста,
- анализ тональности текстов,
- распознавание сущностей в тексте,
- транскрибация речи.
Это далеко не весь список. В будущих статьях мы расскажешь о каждом виде и сферах их применения.
Как размечают данные?
Разметка данных - процесс достаточно рутинный и утомительный. Просто представьте, вы хотите обучить приложение распознавать домашних животных по фото. Для этого вам нужно выделить котиков на сотнях или даже тысячах изображений. Благодаря этому нейронка сможет определять, есть ли на фото котики или нет. А если там вдруг будут пёсики, попугаи или хомячки, то ИИ останется слепым. Поэтому вам придется потратить еще много часов, чтобы разметить всех интересующих вас животных.
Эта жа задача становится в разы сложнее, если вы хотите, чтобы определялся не только вид животного, но и порода. Тогда помимо классификации на виды, нужно будет подразделять их на породы и это еще тысячи размеченных изображений.
Поэтому для решения задач по созданию датасетов или разметке данных обращаются в соответствующие компании. Одной из таких является и LabelMe. Это то, чем мы занимаемся каждый день. Мы привлекаем сотни и тысячи исполнителей со всей России и стран СНГ, которые размечают данные. Затем, чтобы исключить вероятность ошибок, кураторы, а затем и менеджеры проектов проверяют и перепроверяют разметку.
И всё бы ничего, но ведь мы хотим справляться даже с объемными заказами быстрее, не теряя в качестве. В этом нам помогает собственная программное обеспечение - LMTool. Мы разработали его с нуля, чтобы сделать добиться максимального удобства и напихать столько ништяков, сколько это вообще возможно. Давайте немного расскажем про основные.
Знакомство с LMTool
Сразу после установки и запуска нас встречает вот такой минималистичный интерфейс.
Мы намеренно избегали сложных структур. Программа должна быть максимально простой и интуитивно понятной. Поэтому сразу вы видим все доступные на данный момент виды разметки. Мы начали с них, потому что это одни из самых популярных направлений. Но уже сейчас наш отдел разработки создает новый функционал, который будет расширяться с каждым обновлением.
Мы хотим добиться максимальной профитность. Чем умнее будет наш софт, тем меньше работы придется делать исполнителям. Например, если нам прилетает заказ на классификацию изображений, упросить процесс выполнения помогает встроенная в ПО нейронка. Работает она следующим образом:
- У нас есть несколько категорий, по которым нужно рассортировать изображения.
- Исполнитель вручную определяет несколько примеров, после чего встроенная модель начинает обучаться на этих ответ.
- Несколько итераций каждой категории и нейронка сама начинает предлагать исполнителю, что изображено на картинке.
- Человеку уже даже не нужно водить мышкой по курсору в поисках нужной группы. Он просто смотрит, верно ли присужден класс. Если, то просто нажимает enter.
Пример того, как встроенная нейронная сеть позволяет ускорять процесс классификации изображений.
В одном из тестов эта фишка обеспечила прирост производительности на 25%. Но это не предел. Ведь тест проводится на простом примере, где было всего 5 классов. Если бы их было больше, то обучение нейронки заняло бы чуть больше времени, но значительно бы увеличило производительность при дальнейшей разметке.
Заключение
В последующих статьях мы будем подробнее рассказывать про все нововведения, а пока выделим несколько ключевых преимуществ разметки в нашей программе.
- Поддержка всех основных видов файлов - некоторые программы и инструменты, поддерживают лишь несколько форматов, в то время как LMTool - всеяден
- Быстрая адаптация - интуитивно понятный интерфейс и механика работы без всяких туториалов и миллионов комбинаций горячих клавиш
- Универсальность - уже сейчас ПО подходит более чем для … видов разметки
- Подключение нейросетевого API - в тексте мы привели пример с классификацией, но вскоре все виды разметки будут иметь свои нейросетевые апдейты
- Стабильная работа - многие сервисы разметки работают через браузеры. Это значит, что они могут не поддерживать работу с большим количеством файлов или файлы с большим весом. К тому же переполненные или слабые сервера могут не выдерживать нагрузок и вылетать, откатывая назад часы работы.
Есть вопросы или вам что-то не понятно? Пишите в комментарии и мы на всё ответим)
Другие наши статьи:
Наши соцсети: