Второй семестр нагрянул сразу после новогодних праздников и началось все с NLP
Natural Language Processing - используется чтобы применять алгоритмы машинного обучения для текста, речи и их анализа.
Мы изучали NLP на базе R.
В наших assignments (контрольные) мы должны были проанализировать твиты с на тему лиги Call of Duty и NBA, чтобы дать рекомендации стэйкхолдерам что же им делать с бизнесом, чтобы у них было больше денег.
Сначала нужно согнать все твиты в один дадасет, потом очистить его от повторяющихся слов и слов, не имеющих эмоциональной окраски (личные местоимения, предлоги)
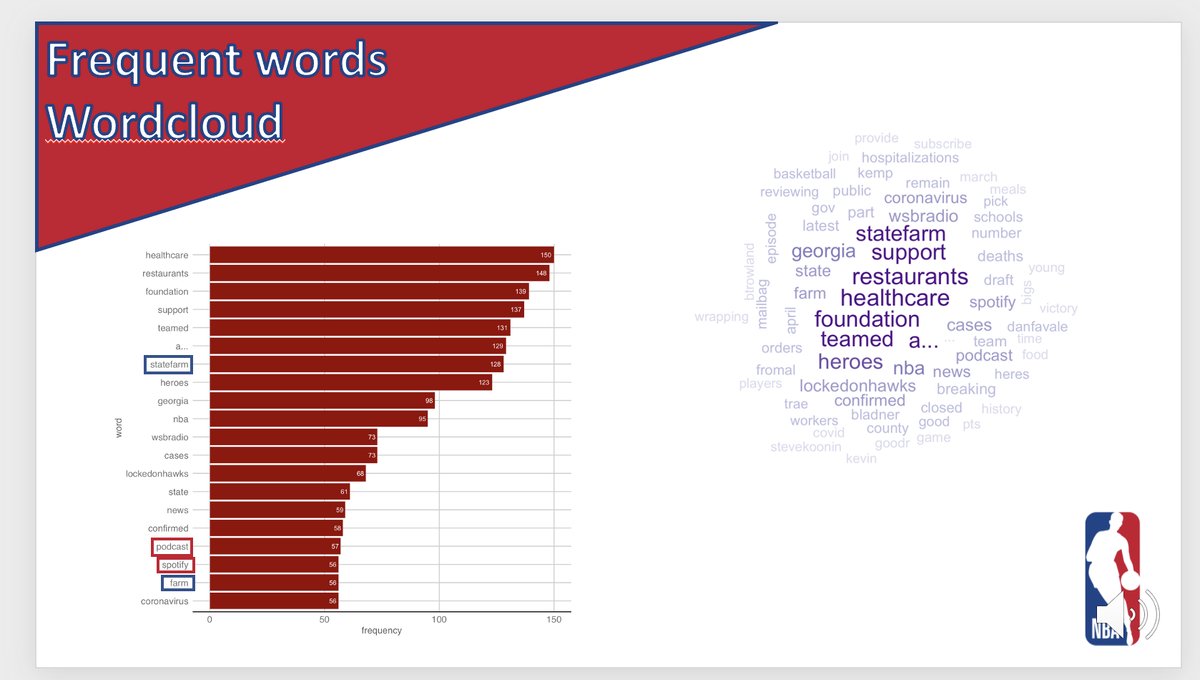
Потом можно найти наиболее часто встречающиеся слова в твитах, сгруппировать их
После этого можно использовать имеющиеся библиотеки эмоциональной окраски слов (disgusting -2, bad -1, well 0, nice 1, amazing 2) чтобы понять, о чем люди отзываются положительно, чем недовольны и что самое главное найти во всем этом связь и дать рекомендации по изменению политики компании.
Machine Learning - множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных.
Мы изучали ML на базе Python и мы должны были использовать алгоритмы для определения факторов, влияющих на желание клиента покупать готовые обеды с доставкой на дом.
Компания, чью дату мы анализировали имела даже продолжительность пребывания на сайте (mob/desktop), количество кликов, просмотренных фото, принятые/отколенные предложения. Из всего этого можно выудить закономерности поведения людей даже из определенного района. Например, если у вас рядом с домом рыбный рынок зачем вам заказывать рыбу по интернету? Соответственно, нужно предлагать другие опции жителям таких зон.
Еще одно интересное задание было основано на анализе результатов опросника студентов. Нужно было избавиться от рандомных ответов (для этого и существуют одинаковые вопросы с разной формулировкой) Те респонденты, у кого в «одинаковых» вопросах была разница более 2ух единиц по шкале (strongly disagree-disagree-neutral-agree-strongly agree) остальные ответы аннулировались.
Живую аудиторию мы разбивали на закономерные паттерны поведения, после чего распределяли их по подгруппам и после тестирования выясняли какой компьютер они купят в будущем Mac или PC.
Эти данные необходимы компаниям, чтобы понять на какую аудиторию создавать рекламную компанию.