Сложность работы с отсутствующими значениями при определенных знаниях оборачивается преимуществом, и в этой статье я расскажу, как с ними подружиться.
Не будем касаться темы их замены или фильтрации, о которых я рассказывал раннее (например, в этом материале). При этом замечу, что делать это стоит в крайнем случае и не на этапе промежуточной обработки признаков, так как иначе по прошествии времени сложно будет определить, что использовалось для замены (я уже не говорю о проблемах в случае попыток понять ваш код другими разработчиками).
В этой статье коснемся выборки данных путем индексирования по булевым значениям с использованием столбца, содержащего отсутствующие значения. Рассмотрим простой DataFrame:
a = pd.DataFrame({'values':['one', np.nan, None,'four']})
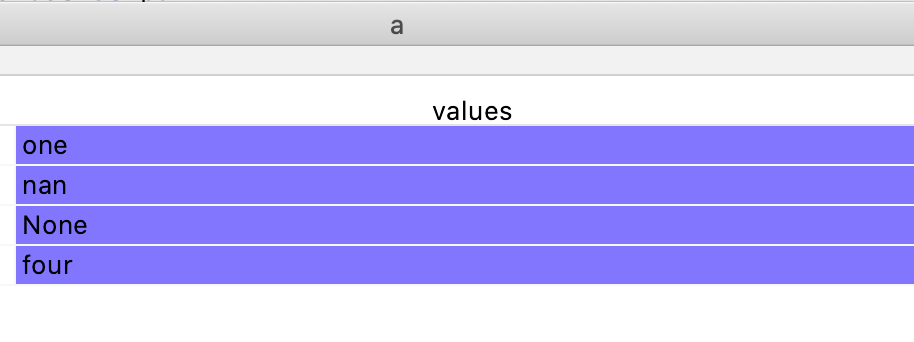
Если попытаться вывести строки, содержащие 'one', получим ошибку:
a[a['values'].str.contains('one')]
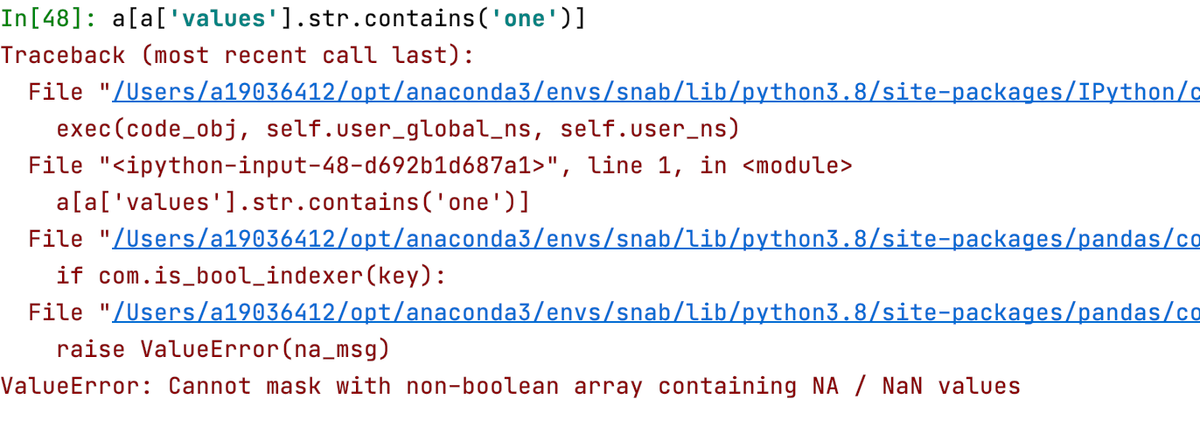
Причиной этого является тот факт, что индексный столбец a['values'].str.contains('one') содержит не только булевы значения (отвечающие на вопрос - содержится ли значение в конкретном поле, но и пустые ячейки):
Двумя распространенными путями борьбы с этим являются:
- добавление к индексному столбцу метода astype(str)
a[a['values'].astype(str).str.contains('one')]
- установление параметра na=False в векторизованном методе contains (или startswith, endswith...)
a[a['values'].str.contains('one', na=False)]
В первом случае можно заметить побочный эффект - наши пустые значения преобразовываются в строки (которые могут содержать поисковую фразу). Поэтому берегитесь искушения преобразовать столбец таким образом:
a['values'] = a['values'].astype(str)
После вы лишитесь возможности работать с пропущенными значениями:
Однако замечу, что в случае использования этого приема только для индексирования (как в примере выше) ваш исходный столбец преобразован не будет.
Теперь о втором способе. Результат нашего булева столбца помечает незаполненные значения как False:
Их также можно пометить как True и включить в итоговый результат: