
Метод опорных векторов (Support Vector Machine) – это алгоритм Машинного обучения (ML), который проецирует Наблюдения (Observation) в n-мерном пространстве Признаков (Feature) с целью нахождения гиперплоскости, разделяющей наблюдения на классы:
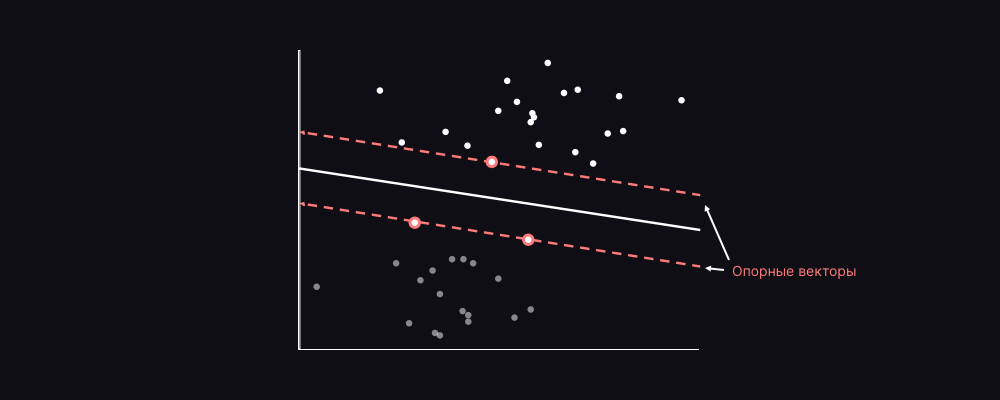
Подход можно использовать как для Классификации (Classification), так и для задач Регрессии (Regression). Чаще всего он используется в задачах классификации. Мы изображаем каждый элемент данных как точку в n-мерном пространстве, где n – количество признаков, причем значение каждой ячейки наблюдения является конкретной координатой в соответствующей плоскости. Затем мы выполняем классификацию, находя разделяющую гиперплоскость, которая разграничивает два класса.
Опорные векторы (обозначены розовым на изображении выше) формируются за счет пограничных наблюдений. Классификатор SVM – это граница, которая лучше всего разделяет два класса.
Как мы можем определить наилучшую гиперплоскость? Давайте разберемся:
- Сценарий 1: на картинке ниже у нас изображено три гиперплоскости (A, B и C). Легко заметить, что только гиперплоскость B правильно отделяет один класс записей от других.
Сценарий 2: на изображении теперь три гиперплоскости, и все они хорошо разделяют классы. Как мы определим правильную?
Плоскость с наибольшим расстоянием от крайних наблюдений обоих классов является наилучшей. Это расстояние называется Полем (Margin).
- Сценарий 3: если спроецировать крайние точки на каждую из разделяющих гиперплоскостей, то наилучшей окажется срединная:
Важная причиной выбора гиперплоскости с более высоким запасом является надежность. Если мы выберем гиперплоскость с низким запасом, то высока вероятность ошибки в классификации.
- Сценарий 4: Несмотря на большие поля гиперплоскости B, наилучшей границей будет A, поскольку последняя не совершает ошибок классификации:
- Сценарий 5: разделить наблюдения на группы с помощью линейной гиперплоскости не получится, поскольку одна из записей серого цвета находится на территории кластера другого класса, и это Выброс (Outlier):
Алгоритм SVM обладает Устойчивостью (Robustness) к выбросам и позволяет игнорировать выбросы и находить гиперплоскость с максимальным полем:
- Сценарий 6: и снова линейного решения задаче не существует:
SVM может решить и эту проблему без труда с помощью дополнительной функции z = x^2 + y^2. Благодаря введению оси z кластеры выглядят по-другому в паре осей x и z:
На приведенном выше графике следует учитывать следующее:
- Все значения z всегда будут положительными, потому что это сумма квадратов x и y
- На исходном графике белые точки появляются рядом с началом координат осей x и y, что снижает значение z. В то же время серые точки более удалены от начала координат, и это увеличивает z.
В классификаторе SVM легко создать линейную гиперплоскость между этими двумя классами. Но возникает еще один животрепещущий вопрос: нужно ли добавлять эту функцию вручную, чтобы получить гиперплоскость? Нет, в алгоритме SVM есть метод, называемый Ядерным методом (Kernel Trick). Это функция, которая берет низкоразмерное входное пространство и преобразует его в более высокоразмерное, то есть преобразует неразрешимую проблему в разрешимую. Проще говоря, он выполняет несколько чрезвычайно сложных преобразований данных, а затем обнаруживает простой способ классификации.
Возвращаясь к исходным условиям сценария 6, мы получаем окружность как нелинейную гиперплоскость:
SVM и Scikit-learn
SVM прекрасно реализован в SkLearn. Для начала импортируем необходимые библиотеки:
Сгенерируем датасет, где наблюдения сгруппированы в два кластера-класса по 25 наблюдений каждое. Стандартное отклонение внутри каждой группы равно 0.6. Построим Точечную диаграмму (Scatterplot) для нашего датасета:
Цветовая гамма "осень" окрасила кластеры в два цвета:
Наш классификатор попытается провести прямую линию, разделяющую два набора данных, и тем самым создать классифицирующую модель. Для двумерных данных задача зачастую легко выполнить вручную. Но сразу же мы видим проблему: существует несколько возможных разделительных линий, которые могут идеально различать два класса!
Некоторые вариации гиперплоскостей ошибаются и в условиях задачи сразу будут признаваться непригодными. Однако среди сотен возможных границ есть множество тех, кто классфицирует записи корректно. Как выбрать наилучший вариант?
Будущая гиперплоскость будет обладать полями, которые будут резервировать пространство на случай появления новых наблюдений ближе к разделительной черте.
Выбор между имеющимися многочисленными вариантами с появлением полей, к сожалению, не стал легче:
На помощь здесь придет SVC (Support Vector Classification), который рассчитает оптимальную ширину поля и направление разделяющей гиперплоскости:
Настройки алгоритма по умолчанию выглядят следующим образом:
Нам предстоит инициализировать кастомную функцию plot_svc_decision_function():
Несмотря на подробное описание функции, некоторые элементы (например, support_vectors_) работают неявно, что позволяет отнести SVM к Черным ящикам (Black Box).
Наилучшее решение – гиперплоскость с максимальной шириной поля без классификационных ошибок выглядит так:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Sunil Ray, Jake VanderPlas
Фото: @utsmanmedia
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курс «Введение в Машинное обучение» на Udemy.