Преобразования полей в больших массивах данных зачастую сопровождаются ошибками. В данной статье я расскажу, как уберечь себя от них и быстро убедиться в правильности своих действий.
Допустим вы располагаете массивом, описывающим время работы офисов вашей организации в различные дни следующего вида:
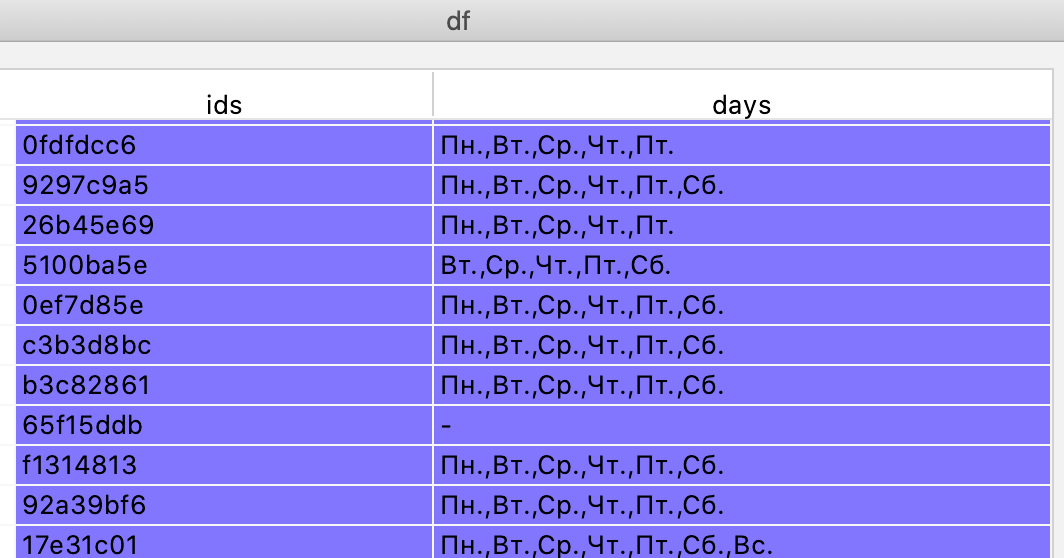
Вашей задачей является парсинг столбца days и приведение его к единообразному виду.
Предположим, вы захотели на предварительном этапе все пустые и отсутствующие значения собрать для последующего выбора стратегии их заполнения. При этом появилось желание добавить поля с единственным символом "-" к их числу.
Если вы попытаетесь вызвать для столбца метод replace и заменить "-" на None, то попадете в ловушку:
df['days'] = df['days'].replace('-', None)
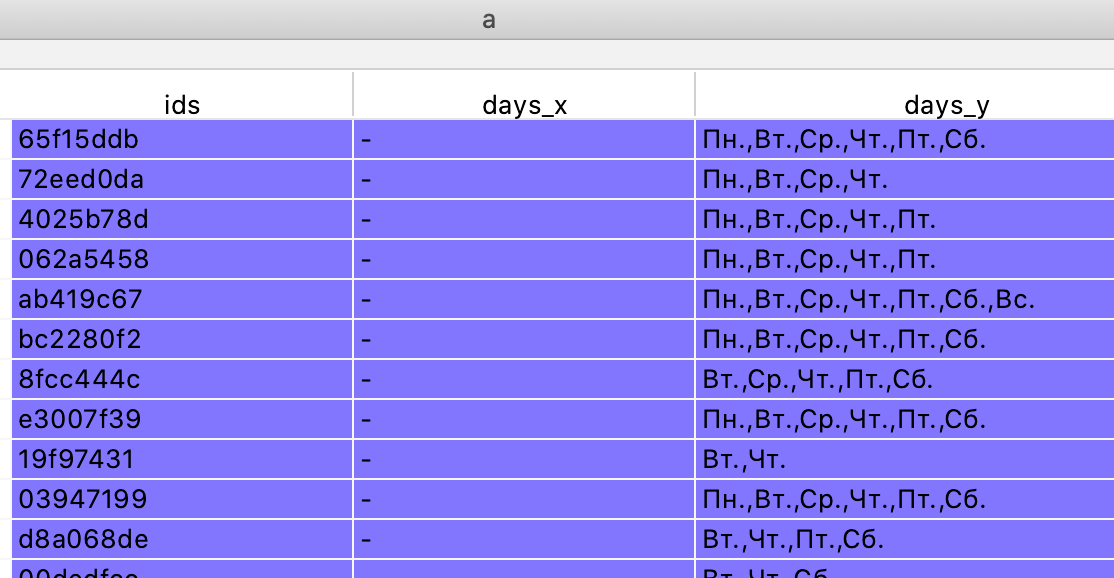
В таблице days_x отражает, что было до, а days_y - после. Как видим, не просто ничего не было заменено ожидаемым образом, но еще и поля заполнены осмысленными значениями (хотя для нашего примера это настораживает).
В действительности, согласно документации Pandas для метода replace параметр, отвечающий за заменяемое значение (называется value), в случае равенства None задает некое предопределенное поведение. В частности, в нашем примере замещение производилось заполнением из предыдущих ненулевых значений (ffill). Для корректности действий следовало набрать:
df['days'] = df['days'].replace({'-': None})
Вот такие подводные камни нас могут ожидать при обработке полей. Поэтому на каждом шаге следует перепроверять корректность своих действий. Для этого я написал простенькую функцию get_diffs_data_cols, которая принимает два одинаковых датафрейма с одноименными исходным и преобразованным столбцами (параметр data_col) и набором общих столбцов (параметр gen_cols), а возвращает строки с различающимися значениями:
Ее запуск происходит следующим образом. Имея таблицу df, получаем ее копию, например, df2, в которой преобразовываем нужный нам столбец, а затем на этим датафреймах вызываем функцию:
Результат ее работы как раз и был продемонстрирован выше.