
Обзор программы "Мультипарсер" я решил начать с рассмотрения периферийных модулей, которые контактируют непосредственно с сайтом-донором и выходными листами Excel. На мой взгляд, было бы не правильно сразу переходить к рассмотрению ядра системы. Вначале надо показать в целом, как система работает, чтобы Вы могли понять, что это и для чего, и вообще надо ли Вам читать всё это дальше.
В этой статье рассматривается парсинг сайта www.abac-air.com . Он выбран не только потому, что бренд стоит первым по алфавиту (хотя согласитесь, что порядок ни когда не помешает), а потому, что структура карточек товара на этом сайте довольно проста. Изображение у каждого товара только одно, и опций у товара нет (например, в виде переключателей в карточках). Поэтому при формировании файла импорта данных нам предстоит работать только со вкладками Products и ProductAttributes.
Но для начала давайте определимся, что за структура будет использоваться для переноса данных с сайта-донора в Excel-файл. На листе Products будут находится строки с основными сведениями о товарах (название, модель, цена, масса, габариты), на листе ProductAttributes - данные о товаре, обусловленные его спецификой (производительность, мощность, рабочее давление и некоторые другие параметры). Эти листы представляют собой, по сути, две таблицы, связанные "один ко многим". То есть, каждая карточка товара интерпретируется как одна строка листа Products и несколько строк листа ProductAttributes.
Строку листа Excel можно представить как ассоциативный массив "номер столбца - значение", несколько строк одной таблицы (для одного листа) - это список ассоциативных массивов, а несколько строк для нескольких листов будут представлять собой ассоциативный массив списков ассоциативных массивов, в котором ключи - это имена листов.
Выглядит это так.
Dictionary<string, List<Dictionary<int, string>>>
Общая структура Интернет-магазина
При всём кажущемся разнообразии Интернет-магазинов в глобальной сети, набор страниц на таких сайтах и их структура примерно одинаковы.
1) Прежде всего, есть список товаров. Это либо одна страница на весь сайт, либо на главной странице есть ссылки на подразделы сайта, в каждом из которых есть своя страница со списком товаров (которую часто называют List-страницей).
2) В центральной части List-страницы располагается таблица (возможно, с пагинацией), которая содержит ссылки на карточки товаров, это страницы с подробным описанием, которые ещё называют Detail-страницами.
3) Каждая Detail-страница содержит следующую информацию.
- Полное наименование товара.
- Главное фото (как правило, большого размера).
- Так же может быть несколько дополнительных миниатюр, каждая из которых содержит ссылку на большой графический файл.
- Описание товара (если не видно сразу, проверьте, может оно на одной из вкладок, но оно там точно есть).
- И наконец, таблица спецификаций
Общая схема обработки страниц
Чтобы осуществить процесс переноса данных с сайта-донора в файл Excel, нам нужны три вещи. Во-первых, определить общий порядок перебора страниц сайта-донора и элементов их разметки. Во-вторых, создать Excel-файл, структура которого соответствует системе, в которую мы собираемся импортировать данные. В третьих, нужен функционал, который читает данные с сайта-донора и переносит в выходной файл.
Эти задачи решает иерархия из трёх классов, перечисленных ниже.
- HtmlParserBase - базовый класс, определяющий общий порядок вызова функций для обработки веб-страниц.
- OpencartHtmlParserBase - определяет структуру выходного файла.
- AbacOpencartHtmlParser - содержит реализацию функций для обработки веб-страниц конкретного сайта.
В базовом классе реализована функция DoParsingOfIncomingHtml, которой, кроме ссылки на сайт-донор, передаётся начальное значение идентификатора товара (пока явно, возможно, в дальнейшем реализую нумераторы), и объект для обмена информацией с потоком обработки. Все теги передаются с помощью абстрактных функций, которые должны быть реализованы в производных классах.
Рекурсивная функция GetListOfPages формирует список страниц, переходя по Next-ссылке до тех пор, пока она доступна.
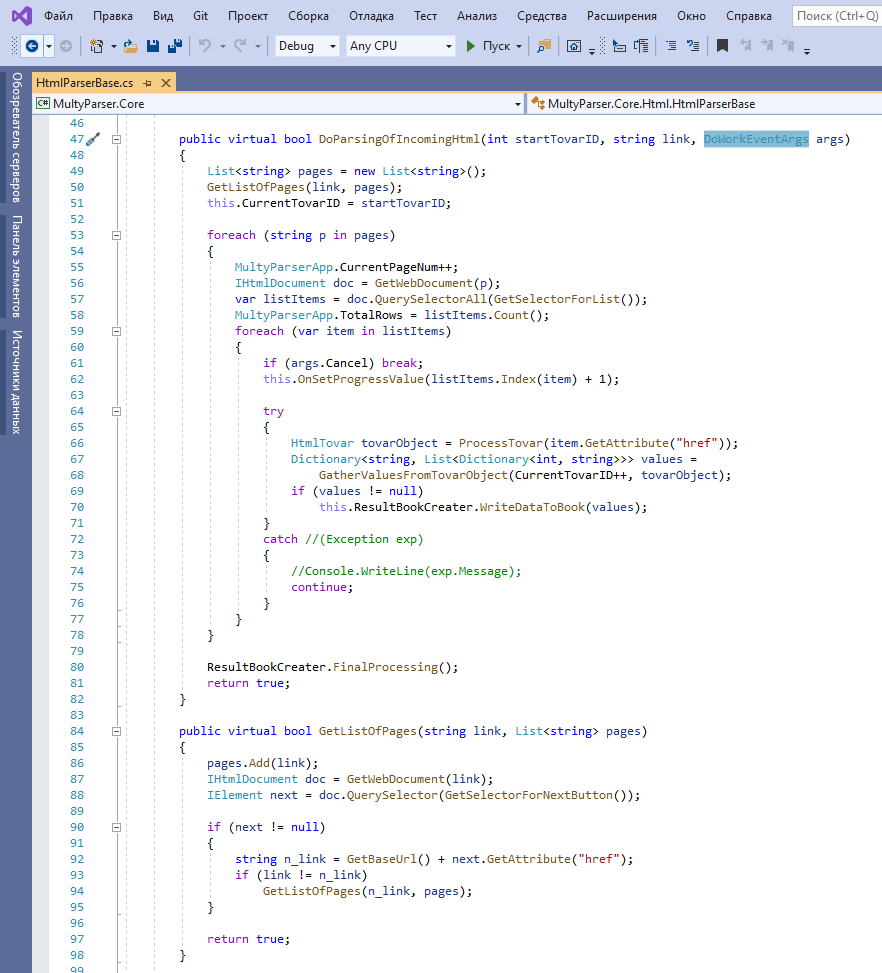
Информация со страницы сайта читается в объект класса HtmlTovar, который затем используется для заполнения таблиц в файле импорта. Механизм создания файла импорта (выходного файла) задаётся в классе OpencartHtmlParserBase. Хоть это и не конечный класс иерархии, но на этапе его работы уже известна CMS-система (в данном случае это Opencart), так что именно здесь реализована функция, заполняющая конкретные ячейки таблиц.
Совершенно ясно, что сейчас нужно заполнить две структуры: таблицу на странице товаров и атрибуты. На рисунке как раз показано заполнение первой структуры. Вторую, в общем-то, мы могли бы сейчас тоже заполнить, используя для этого значения из массива спецификаций, который содержится в объекте tovarObject, но эти данные не пройдут валидацию при импорте.
Дело в том, что импортировать можно только те атрибуты, которые есть в базе данных. И сейчас я готов спорить, что многие из Вас подумали, что было бы очень хорошо, если бы атрибуты создавались автоматически при импорте товаров. Но не всё так просто. На разных сайтах одни и те же параметры могут называться по-разному. Например, на одних написано "Вес", а на других - "Масса". На одних написано "Габариты", на других - "Размеры", а на третьих вообще длинна ширина и высота написаны на отдельных строчках.
Как ни крути, мы приходим к необходимости завести свой собственный список спецификаций, и при обработке информации с других сайтов приводить их спецификации в соответствие нашим.
Поскольку нам в будущем может понадобиться обрабатывать товары любых типов (не только компрессорного оборудования), то желательно иметь несколько наборов спецификаций. Воплощено это в конфигурационном файле.
На обработке этой секции останавливаться не буду - стандартный набор классов, который очень просто реализовать. Гораздо интереснее, как определённые в этой секции группы товаров используются в дальнейшем.
В приложении есть класс MultyParserApp, который содержит статические функции, касающиеся программы в целом. Например, функции поиска подходящего обработчика для веб-страницы или Excel-файла, функции получения информации о текущем ходе процесса обработки. Работу с общими спецификациями я тоже реализовал здесь.
Группы товаров, которые считываются из файла конфигурации, записываются в ассоциативный массив, ключом которого становятся мнемонические коды групп. По этому коду парсер для конкретного сайта находит тот набор спецификаций, с которым должен работать.
Но парсер, кроме этого, содержит функцию, которая возвращает список его собственных спецификаций, с теми названиями, которые содержатся на сайте-доноре. По структуре этот ассоциативный массив зеркален по отношению к массиву спецификаций, который содержится в группе товаров. Группа товаров содержит массив "целое-строка", а парсер создаёт свой собственный массив по типу "строка-целое".
Поиск соответствия осуществляется таким образом. Из массива спецификаций объекта tovarObject берётся строка, ключ которой мы пытаемся найти среди ключей спецификаций парсера. Если ключ находится, мы берём соответствующее ключу целое число и по нему находим спецификацию в массиве группы (той, что прочитали из конфига). Далее берём название спецификации, название группы и значение, которое было в объекте tovarObject.
Ну и последняя задача, которую я тоже решаю с помощью ассоциативного массива. Перенесение метрических параметров из таблицы атрибутов в основную таблицу товаров. Для этого возвращаю массив пар, состоящих из начала названия спецификации и номера столбца на листе Products, в который надо перенести её значение.
Формирует этот массив производный класс. На следующем скриншоте показан класс для обработки сайта продукции ABAC. Вот именно сейчас и откроются все карты. Это по сути конечный класс иерархии. Но делать его упакованным я не стал: может на его основе понадобится реализовать какой-то дополненный функционал.
Итак, что же нам тут открывается. Прежде всего, реализация всех функций, возвращающих элементы разметки страницы сайта-донора, те самые которые ищет в цикле функция DoParsingOfIncomingHtml класса HtmlParserBase. Заметьте, что благодаря лямбда-синтаксису эти функции получились необычайно компактными.
Ну и далее идут две функции: функция отображения спецификаций сайта на спецификации группы товаров и функция переноса метрических параметров в основную таблицу - эти функции тоже зависят от конкретного сайта-донора, а значит, могут быть реализованы только в терминальном классе.
Испытание системы
Работая с плагином импорта, я к сожалению, обнаружил один неприятный сюрприз, суть которого не разгадал до сих пор. Плагин отказывается работать с теми заголовками, которые я вывожу в таблицах файла импорта самостоятельно, то есть с помощью своей программы. Я пытался их центрировать и выделять жирным шрифтом, но при попытке импорта из таких файлов, плагин неизменно выдаёт ошибку валидации.
Мне пришлось реализовать в программе возможность формировать выходные файлы с помощью шаблона, в качестве которого используется образец, полученный при пробном экспорте товаров. Итак, берём файл с экспортированной продукцией, и удаляем из него все данные. Но это ещё не всё. Так же мы должны удалить листы, которые в данный момент не будем использовать, то есть все, кроме Products и ProductAttributes. Иначе плагин "увидит" листы, предназначенные, вроде бы, для импорта, но на которых не указаны идентификаторы, и опять заругается.
Да, очень капризный плагин! Но при должном обращении всё делает довольно чисто. Получившийся урезанный шаблон сохраните, пожалуйста, под другим именем - полный вариант нам понадобится, когда мы будем расширять возможности "Мультипарсера". Этот шаблон нужно выбрать в верхней части окна программы перед осуществлением прсинга.
Тут, кстати, есть небольшой недочёт. Поле надо назвать "Шаблон выходного файла", так как непосредственно выходные файлы складываются в папку "Result". В следующих версиях программы я это исправлю. На следующем рисунке показан ход выполнения. Как видите, программа "Мультипарсер" оснащена окном, с прогрессбаром и текстовыми полями, информирующими пользователя о ходе процесса обработки данных.
Как я уже говорил, перед импортом, непосредственно, товаров, необходимо импортировать опции. Найдите среди образцов файлов, с которыми работает плагин, файл атрибутов и запишите в него актуальные данные. Их можно взять из файла конфигурации.
Если Вы всё сделали правильно, в админке Опенкарта увидите все импортированные товары с картинками.
В следующих статьях канала я собираюсь рассказать о работе с другими сайтами, более сложными по своей структуре, которые потребуют внесения дополнительного функционала в программу. До встречи!
Глава 03 - Карта канала - Глава 05