Geometric Deep Learning - это попытка геометрического объединения широкого класса задач машинного обучения с точки зрения симметрии и инвариантности. Эти принципы не только лежат в основе прорывной производительности сверточных нейронных сетей и недавнего успеха графовых нейронных сетей, но также обеспечивают принципиальный способ построения новых типов индуктивных предубеждений для конкретных задач
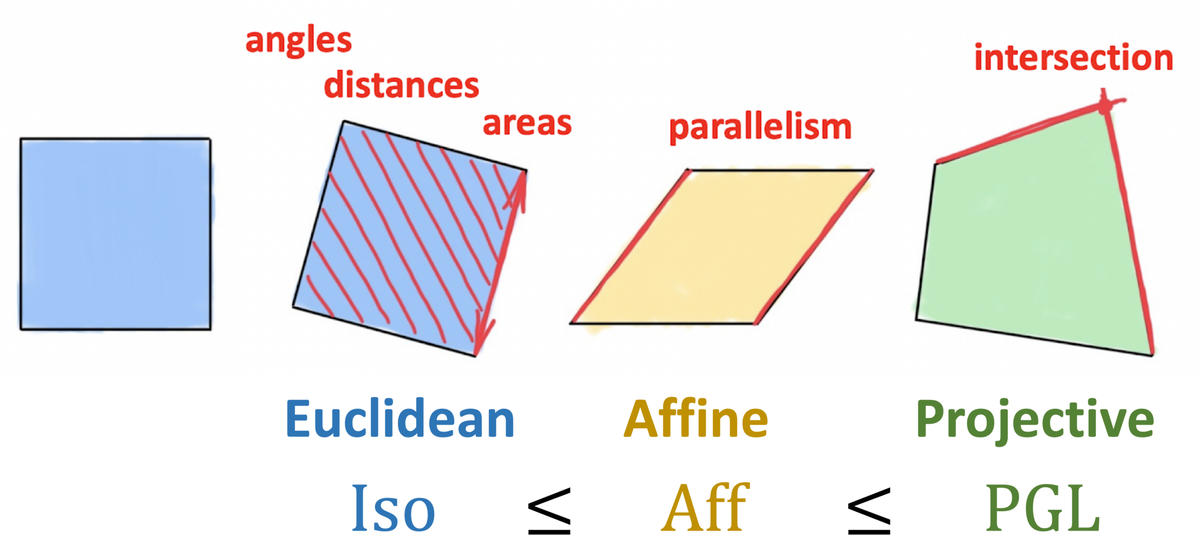
Октябрь 1872, философский факультет в Смаль л университета в баварском городе Эрлангене назначен новый молодой профессор. Как обычно, его попросили выступить с первой исследовательской программой, которую он опубликовал под довольно длинным и скучным названием Vergleichende Betrachtungen über neuere geometrische Forschungen («Сравнительный обзор последних исследований в области геометрии»). Профессором был Феликс Кляйн , которому тогда было всего 23 года, и его первая работа вошла в анналы математики как « Программа Эрлангена » [1].

Девятнадцатый век был удивительно плодотворным для геометрии. Впервые почти за две тысячи лет после Евклида построение проективной геометрии Понселе , гиперболической геометрии Гаусса, Бойяи и Лобачевского и эллиптической геометрии Римана показало, что возможен целый зоопарк разнообразных геометрий. Однако эти конструкции быстро разошлись в независимых и несвязанных областях, и многие математики того периода задавались вопросом, как разные геометрии связаны друг с другом и что на самом деле определяет геометрию.
Прорывной идеей Кляйна был подход к определению геометрии как к изучению инварианты, или другими словами, структуры, которые сохраняются при определенном типе преобразований (симметрии).Кляйн использовал формализм теории групп для определения таких преобразований и использовал иерархию групп и их подгрупп для классификации различных геометрий, возникающих из них. Таким образом, группа жестких движений приводит к традиционной евклидовой геометрии, в то время как аффинные или проективные преобразования производят соответственно аффинную и проективную геометрии. Важно отметить, что программа Эрлангена была ограничена однородными пространствами [2] и изначально исключала риманову геометрию.
Влияние Эрлангенской программы на геометрию и математику в целом было очень глубоким. Это также распространилось на другие области, особенно в физику, где соображения симметрии позволили вывести законы сохранения из первых принципов - удивительный результат, известный как теорема Нётер [3]. Потребовалось несколько десятилетий, прежде чем этот фундаментальный принцип - через понятие калибровочной инвариантности (в его обобщенной форме, развитой Янгом и Миллсом в 1954 году) - оказался успешным в объединении всех фундаментальных сил природы, за исключением гравитации. Это то, что называется Стандартной моделью, и она описывает всю физику, которую мы знаем в настоящее время. Мы можем только повторить слова лауреата Нобелевской премии физика Филипа Андерсона [4] о том, что
«Сказать, что физика занимается изучением симметрии, будет лишь немного преувеличением».
Мы считаем, что текущее состояние дел в области глубокого (репрезентативного) обучения напоминает ситуацию с геометрией в девятнадцатом веке: с одной стороны, за последнее десятилетие глубокое обучение произвело революцию в науке о данных и сделало возможным многие задачи, которые ранее считались недоступными - будь то компьютерное зрение, распознавание речи, перевод на естественный язык или игра в го. С другой стороны, теперь у нас есть зоопарк разных архитектур нейронных сетей для разных типов данных, но мало объединяющих принципов. Как следствие, трудно понять отношения между различными методами, что неизбежно приводит к переосмыслению и ребрендингу одних и тех же концепций.
Геометрическое глубокое обучение - это обобщающий термин, который мы ввели в [5], имея в виду недавние попытки придумать геометрическую унификацию машинного обучения, подобную программе Эрлангена Кляйна. Он служит двум целям: во-первых, предоставить общую математическую основу для построения наиболее успешных архитектур нейронных сетей, а во-вторых, дать конструктивную процедуру для принципиального построения будущих архитектур.
SМашинное обучение с учителем в его простейшей настройке - это, по сути, проблема оценки функции: учитывая выходные данные некоторой неизвестной функции в обучающем наборе (например, помеченные изображения собаки и кошки), каждый пытается найти функцию f из некоторого класса гипотез, которая хорошо подходит для обучения. data и позволяет прогнозировать выходы на ранее невидимых входах. В последнее десятилетие доступность больших высококачественных наборов данных, таких как ImageNet, совпала с ростом вычислительных ресурсов (GPU), что позволило разрабатывать богатые функциональные классы, способные интерполировать такие большие наборы данных.
Нейронные сети кажутся подходящим выбором для представления функций, потому что даже простейшая архитектура, такая как Perceptron, может создавать плотный класс функций при использовании всего двух слоев, что позволяет аппроксимировать любую непрерывную функцию с любой желаемой точностью - свойство, известное как универсальное приближение. [6].
Постановка этой задачи в малых размерностях является классической задачей теории приближений, которая широко изучалась с точным математическим контролем ошибок оценивания. Но в больших размерностях ситуация совершенно иная: можно быстро увидеть, что для аппроксимации даже простого класса, например, липшицевых функций, количество выборок растет экспоненциально с размерностью - явление, в просторечии известное как «проклятие размерности». Поскольку современные методы машинного обучения должны работать с данными в тысячах или даже миллионах измерений, проклятие размерности всегда находится за кулисами, делая такой наивный подход к обучению невозможным.
Возможно, лучше всего это проявляется в задачах компьютерного зрения, таких как классификация изображений. Даже крошечные изображения имеют тенденцию быть очень многомерными, но интуитивно они имеют много структуры, которая нарушается и выбрасывается, когда кто-то анализирует изображение в вектор, чтобы передать его в перцептрон. Если изображение теперь сдвинуто всего на один пиксель, векторизованный вход будет сильно отличаться, и нейронной сети нужно будет показать множество примеров, чтобы понять, что сдвинутые входные данные должны классифицироваться таким же образом [7].
FК счастью, во многих случаях многомерных задач машинного обучения у нас есть дополнительная структура, которая исходит из геометрии входного сигнала. Мы называем эту структуру «априорной симметрией», и это общий мощный принцип, который вселяет в нас оптимизм в проблемах с проклятыми размерностями. В нашем примере классификации изображений входное изображение x - это не просто d- мерный вектор, а сигнал, определенный в некоторой области Ω, которая в данном случае представляет собой двумерную сетку. Структура домена фиксируется группой симметрии𝔊 - группа 2D-переводов в нашем примере - которая действует на точки в области. В пространстве сигналов 𝒳 (Ω) групповые действия (элементы группы, 𝔤∈𝔊) в основной области проявляются через то, что называется групповым представлением ρ (𝔤) - в нашем случае это просто сдвиг оператор , матрица размера d × d , действующая на d -мерный вектор [8].
Геометрическая структура области, лежащей в основе входного сигнала, накладывает структуру на класс функций f, которые мы пытаемся изучить. Могут быть инвариантные функции, на которые не влияет действие группы, т. Е. F ( ρ (𝔤) x ) = f ( x ) для любых 𝔤∈𝔊 и x . С другой стороны, может быть случай, когда функция имеет ту же структуру входа и выхода и преобразуется так же, как вход - такие функции называются эквивариантными и удовлетворяют условию f ( ρ (𝔤) x ) = ρ (𝔤 ) f (х ) [9]. В области компьютерного зрения классификация изображений является хорошей иллюстрацией ситуации, в которой желательно иметь инвариантную функцию (например, независимо от того, где находится кошка на изображении, мы все равно хотим классифицировать ее как кошку), в то время как сегментация изображения , где вывод представляет собой пиксельную маску метки, является примером эквивариантной функции (маска сегментации должна следовать за преобразованием входного изображения).
АЕще один важный геометрический приоритет - это «масштабное разделение». В некоторых случаях, мы можем построить иерархию многомасштабных доменов (Q и Q»на рисунке ниже) с помощью„ассимилировать“ближайшие точки и производить также иерархию пространств сигналов, которые связаны посредством огрубления оператора P . К этим грубым масштабам мы можем применять функции грубого масштаба. Будем говорить , что функция F является локально стабильным , если оно может быть аппроксимировано как состав огрубления оператора Р и функции грубого масштаба, F ≈ F» ∘ P . Пока f может зависеть от дальнодействующих зависимостей, если он локально стабилен, их можно разделить на локальные взаимодействия, которые затем распространяются в сторону грубых масштабов [10].
Эти два принципа дают нам очень общий план геометрического глубокого обучения, который можно распознать в большинстве популярных глубоких нейронных архитектур, используемых для обучения представлению: типичный дизайн состоит из последовательности эквивариантных слоев (например, сверточных слоев в CNN), которым, возможно, следуют с помощью инварианта глобальных объединения слоя агрегирующих все в один выход. В некоторых случаях также возможно создать иерархию доменов с помощью некоторой процедуры огрубления, которая принимает форму локального объединения .
Это очень общий дизайн, который может быть применен к различным типам геометрических структур, таким как сетки , однородные пространства с глобальными группами преобразований, графы (и множества, как частный случай) и многообразия, где у нас есть глобальная изометрическая инвариантность и локальная инвариантность. калибровочные симметрии. Реализация этих принципов приводит к некоторым из наиболее популярных архитектур , которые существуют сегодня в глубоком обучении: сверточных сетей (CNNs), возникающих из трансляционной симметрии , Graph Neural Networks, DeepSets [11], и трансформаторы [12], осуществляя перестановки инвариантность , стробированные RNN (такие как сети LSTM), которые инвариантны к деформации времени[13] и CNN с внутренней сеткой [14], используемые в компьютерной графике и зрении, которые могут быть получены из калибровочной симметрии .
В будущих публикациях мы будем более подробно исследовать примеры геометрического проекта глубокого обучения в «5G» [15]. В заключение мы должны подчеркнуть, что симметрия исторически была ключевым понятием во многих областях науки, из которых физика, как уже упоминалось в начале, является ключевой. В сообществе машинного обучения важность симметрии давно признана, в частности, в приложениях к распознаванию образов и компьютерному зрению, причем ранние работы по эквивариантному обнаружению признаков восходят к Шунити Амари [16] и Райнеру Ленцу [17]. В литературе по нейронным сетям теорема групповой инвариантности для персептронов Марвина Мински и Сеймура Паперта [18] налагает фундаментальные ограничения на возможности (однослойных) персептронов изучать инварианты.
