С выходом Apache Spark 3.1 в марте 2021-го проект Spark on Kubernetes официально перешел в статус общедоступного и готового к эксплуатации.

Это стало результатом трехлетней работы быстрорастущего сообщества, участники которого помогали в разработке и внедрении (изначально поддержка Spark on Kubernetes появилась в Spark 2.3 в феврале 2018 года). Перевели самое важное из статьи об основных возможностях Spark 3.1, в которой автор подробно остановился на улучшениях в Spark on Kubernetes.
Полезные источники информации:
- Введение в использование Kubernetes в качестве менеджера ресурсов для Spark (вместо YARN): Pros & Cons of Running Spark on Kubernetes
- Техническое руководство по успешной работе со Spark on Kubernetes: Setting Up, Managing & Monitoring Spark on Kubernetes
- Про Data Mechanics: Spark on Kubernetes Made Easy: How Data Mechanics Improves On The Open-Source Version
Путь Spark on Kubernetes: от бета-поддержки в 2.3 до нового стандарта в 3.1
С выходом Spark 2.3 в начале 2018 года Kubernetes стал новым диспетчером для Spark (помимо YARN, Mesos и автономного режима) в крупных компаниях, возглавляющих проект: RedHat, Palantir, Google, Bloomberg и Lyft. Сначала поддержка имела статус экспериментальной, функций было мало, стабильность и производительность были невысокими.
С тех пор сообщество проекта получило поддержку многочисленных крупных и маленьких компаний, которых заинтересовали преимущества Kubernetes:
- Нативная контейнеризация. Упаковывайте зависимости (и сам Spark) с помощью Docker.
- Эффективное совместное использование ресурсов и ускорение запуска приложений.
- Обширная Open Source-экосистема уменьшает зависимость от облачных провайдеров и вендоров.
В проект было внесено несколько нововведений: от базовых требований вроде поддержки PySpark и R, клиентского режима и монтирования томов в версии 2.4 до мощных оптимизаций вроде динамического выделения (в 3.0) и улучшения обработки выключения нод (в 3.1). За последние три года вышло больше 500 патчей, сильно повысивших надежность и производительность Spark on Kubernetes.
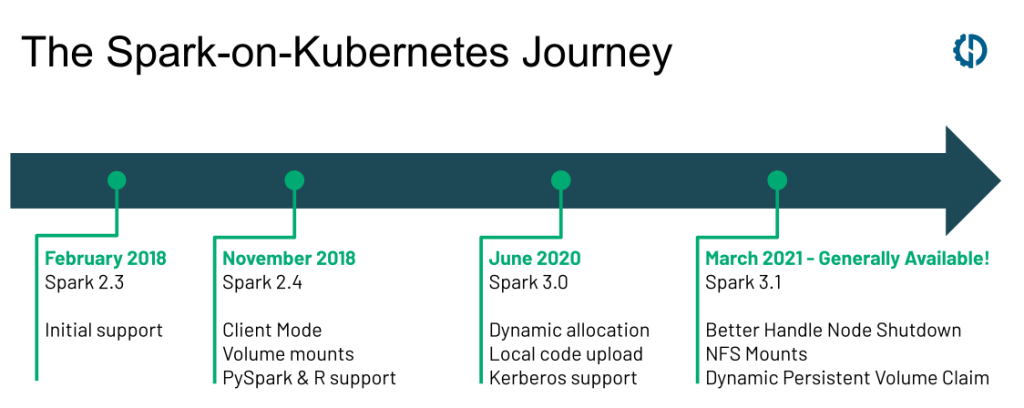
В результате в новых Spark-проектах в 2021 году Kubernetes все чаще рассматривается в роли стандартного менеджера ресурсов: это следует из популярности Open Source-проекта оператора Spark on Kubernetes и объявлений крупных вендоров, внедряющих Kubernetes вместо Hadoop YARN.
С выходом Spark 3.1 проект Spark on Kubernetes получил статус общедоступного и готового к эксплуатации. В этом релизе было внесено больше 70 исправлений и улучшений производительности. Давайте рассмотрим самые важные функции, которых с нетерпением ждали заказчики.
Улучшенная обработка выключения нод: постепенное отключение исполнителя (новая функция в Spark 3.1)
Эту функцию (SPARK-20624) реализовал Holden Karau, и пока что она доступна только для автономных развертываний и в Kubernetes. Называется функция «улучшенная обработка выключения нод», хотя еще одно подходящее название — «постепенное отключение исполнителя» (Graceful Executor Decommissioning).
Эта функция повышает надежность и производительность Spark при использовании Spot-нод (вытесняемые ноды в GCP). Перед остановкой спота с него перемещаются shuffle-данные и содержимое кэша, поэтому влияние на работу Spark-приложения оказывается минимальное. Раньше, когда система убивала спот, все shuffle-файлы терялись, поэтому их приходилось вычислять заново (снова выполнять потенциально очень долгие задачи). Новая фича не требует настройки внешнего shuffle-сервиса, для которого нужно по запросу запускать дорогие ноды хранения и который совместим с Kubernetes.
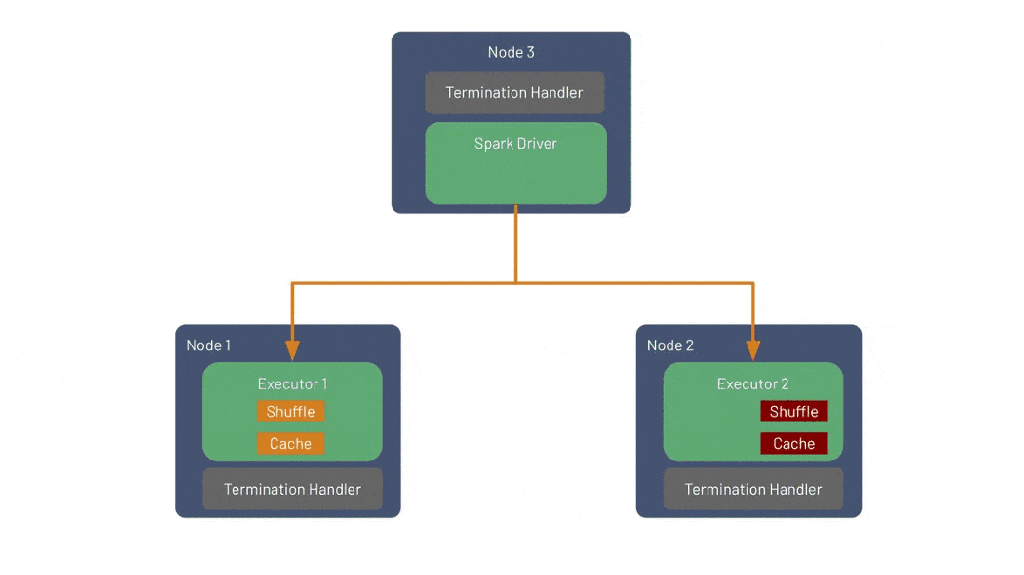
Что делает эта функция?
- Исполнитель, который нужно выключить, вносится в черный список: драйвер Spark не будет назначать ему новые задачи. Те задачи, которые сейчас исполняются, не будут принудительно прерваны, но если они сбоят из-за остановки исполнителя, то перезапустятся в другом исполнителе, как и сейчас, а их сбой не будет учитываться в максимальном количестве сбоев (новинка).
- Shuffle-файлы и кэшированные данные мигрируют из выключаемого исполнителя в другой. Если другого нет, например, мы выключаем единственный исполнитель, то можно настроить объектное хранилище (вроде S3) в качестве запасного.
- После завершения миграции исполнитель умирает, а Spark-приложение продолжает работать как ни в чем не бывало.
Когда работает эта функция?
- При использовании Spot / вытесняемых нод облачный провайдер уведомляет о выключении за 60–120 секунд. Spark может использовать это время для сохранения важных shuffle-файлов. Этот механизм используется и в тех случаях, когда экземпляр на стороне провайдера по каким-то причинам выключают, допустим, при обслуживании EC2.
- Когда нода Kubernetes пустеет, например для технического обслуживания, или когда вытесняется под исполнителя Spark, например более высокоприоритетным подом.
- Когда убранный исполнитель является частью динамического выделения при уменьшении размера системы из-за простоя исполнителя. В этом случае тоже будут сохранены кэш и shuffle-файлы.
Как включить функцию?
- С помощью конфигурационных флагов. Нужно включить четыре основных флага Spark:spark.decommission.enabled;
spark.storage.decommission.rddBlocks.enabled;
spark.storage.decommission.shuffleBlocks.enabled;
spark.storage.decommission.enabled.
Другие доступные настройки рекомендую поискать прямо в исходном коде.
- Для получения предупреждения от облачного провайдера о скором отключении ноды, например из-за выключения спота, нужна специфическая интеграция.
Новые опции с томами в Spark on Kubernetes
Начиная со Spark 2.4 при использовании Spark on Kubernetes можно монтировать три типа томов:
- emptyDir: изначально пустая директория, существующая, пока работает под. Полезна для временного хранения. Можно поддерживать ее с помощью диска ноды, SSD или сетевого хранилища.
- hostpath: в ваш под монтируется директория прямо из текущей ноды.
- Заранее статически создаваемый PersistentVolumeClaim. Это Kubernetes-абстракция для разных типов персистентного хранилища. Пользователь должен создать PersistentVolumeClaim заранее, существование тома не привязано к поду.
В Spark 3.1 появилось два новых варианта: NFS и динамически создаваемый PersistentVolumeClaims.
NFS — это том, который могут одновременно использовать несколько подов и который можно заранее наполнить данными. Это один из способов обмена информацией, кодом и конфигурациями между Spark-приложениями либо между драйвером и исполнителем внутри какого-нибудь Spark-приложения. В Kubernetes нет NFS-сервера, вы можете запустить его самостоятельно или использовать облачный сервис.
После создания NFS вы можете легко монтировать этот том в Spark-приложение с помощью таких настроек:
spark.kubernetes.driver.volumes.nfs.myshare.mount.path=/shared
spark.kubernetes.driver.volumes.nfs.myshare.mount.readOnly=false
spark.kubernetes.driver.volumes.nfs.myshare.options.server=nfs.example.com
spark.kubernetes.driver.volumes.nfs.myshare.options.path=/storage/shared
Второй новый вариант — динамический PVC. Это более удобный способ использования персистентных томов. Раньше нужно было сначала создавать PVC, а затем монтировать их. Но при использовании динамического выделения вы не знаете, сколько можно создать исполнителей в ходе работы вашего приложения, поэтому старый способ был неудобен. К тому же приходилось самостоятельно вычищать ненужные PersistentVolumeClaims либо смиряться с потерей места в хранилище.
Со Spark 3.1 все стало динамическим и автоматизированным. Когда вы инициализируете Spark-приложение или в ходе динамического выделения запрашиваете новые исполнители, в Kubernetes динамически создается PersistentVolumeClaims, который автоматически предоставляет новый PersistentVolumes запрошенного вами класса хранилища. При удалении пода ассоциированные с ним ресурсы автоматически удаляются.
Другие функции Spark 3.1: PySpark UX, стейджинговая диспетчеризация, повышение производительности
В Spark 3.1 появилось два крупных улучшения в UX для разработчиков на PySpark:
- Документация PySpark полностью переделана, теперь она больше соответствует Python и удобна для использования.
- Теперь поддерживаются подсказки типов: получение в IDE бесплатного автозавершения кода и обнаружения статических ошибок.
Spark History Server, который отображает интерфейс Spark после завершения вашего приложения, теперь может показывать статистику выполненных вами запросов на Structured Streaming.
Стейджинговая диспетчеризация (SPARK-27495) применима только для YARN- и Kubernetes-развертываний при включенном динамическом выделении. Она позволяет вам управлять в коде количеством и типом запрашиваемых для исполнителя ресурсов с точностью на уровне стадий. В частности, вы можете настроить приложение под использование исполнителей с процессорными ресурсами в ходе первой стадии (например, при выполнении ETL или подготовке данных), а в ходе второй стадии — на использование видеокарт (скажем, для моделей машинного обучения).
В Spark 3.1 улучшили производительность shuffle хеш-соединения, добавили новые правила для прерывания подвыражений и в оптимизатор Catalyst. Для пользователей PySpark будет полезно то, что в Spark теперь применяется колоночный формат in-memory хранения Apache Arrow 2.0.0 вместо 1.0.2. Это повысит скорость работы приложений, особенно если вам нужно преобразовывать данные между Spark и фреймами данных Pandas. Причем все эти улучшения производительности не потребуют от вас менять код или конфигурацию.
Оригинал статьи на Habr.com.
Автор: Андрей Пшеничнов
Источник: https://mcs.mail.ru/blog/apache-spark-3-1-spark-on-kubernetes-obshhedostupen