Разберем диагностические средства библиотеки Pandas для определения мусора в данных. Полученные результаты агрегируем и напишем функцию, чтобы избавить себя от рутинной работы.
В качестве примера воспользуемся игрушечным набором (рассмотрен при изучении описательных характеристик таблицы), содержащим информацию о поломках машин, а именно - тип машины, флаг наличия дефекта, дату поломки, дату поставки (начала эксплуатации), разницы между этими датами (в месяцах):
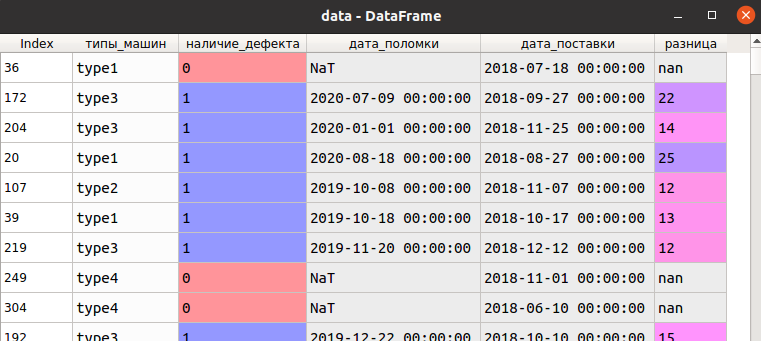
В качестве мусорных нас прежде всего интересуют незаполненные и нулевые значения, пустые строки. Для получения незаполненных значений можно воспользоваться методом isnull, а пустых и нулевых - операциями сравнения. Кроме того, нас могут интересовать индексы "мусорных" строк, которые можно получить, обратившись к свойству index.
На этой базе напишем следующую функцию:

Рассмотрим ее применение на примере столбца дата_поломки:
Для применения df_col_rubbish_info ко всей таблице потребуется в цикле вызвать ее на каждой колонке, что и сделано в приведенных ниже функциях:
Код для генерации набора представлен ниже: