
C (параметр регуляризации) – мера степени наказания Модель (Model) за каждую неверно классифицированную точку.
Метод опорных векторов – это такая разновидность Алгоритма (Algorithm) Классификации (Classification), которая пытается найти плоскости, отделяющие положительные точки от отрицательных:
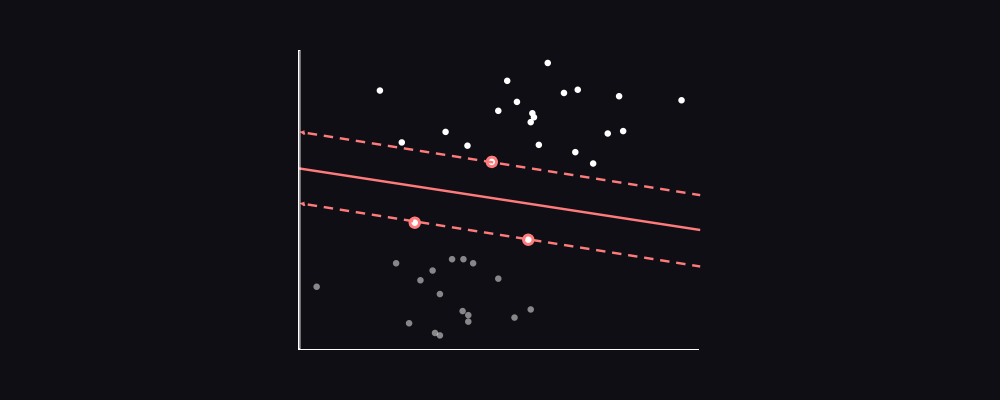
Сплошная линия посередине представляет собой наилучшую возможную линию разделения положительных Наблюдений (Observation) от отрицательных. Точки в кружке – это Опорные векторы (Support Vector).
SVM также может находить разделительные кривые:
Ядра – функции преобразования могут так трансформировать набор точек, что разделяющая гиперплоскость будет найдена.
Шум
Реальные данные содержат так называемый шум, так что надежный классификатор SVM должен уметь игнорировать "зашумленные" Выбросы (Outlier), чтобы обнаружить обобщаемую плоскость:
Соответственно, выделяют две разновидности зазоров (разделительных полей вдоль гиперплоскости) – жесткие (Hard) и мягкие (Soft). Первые находят лучшую гиперплоскость, отделяющую положительные точки от отрицательных, так что ни один элемент не классифицируется неправильно. Второй же допускает неверную классификацию таких отстоящих наблюдений, и в этом случае разделяющая функция подвергается так называемому Наказанию (Penalizing) пропорционально степени ошибочной классификации. По умолчанию в большинстве библиотек реализованы мягкие зазоры.
Теперь понять значение гиперпараметра C будет легко: он контролирует, насколько мы хотим наказать модель за каждую неверно классифицированную точку. Большое значение C приводит к тому, что из всех возможных гиперплоскостей будет иметь приоритет тот, что совершил наименьшее количество классификационных ошибок. Низкое значение C, наоборот, выберет такую разделительную границу, что хорошо разделяет точки, допуская некоторую погрешность.
Параметр регуляризации C и Scikit-learn
Посмотрим, как влияет C на согласованность прогнозов. Для начала импортируем необходимые библиотеки:
Сгенерируем датасет из 100 случайных наблюдений с 300 признаками у каждого:
В SkLearn принято выделять два вида значений C: l1 и l2. Первая теория утверждает, что согласованность прогнозов невозможна из-за смещения l1. Однако согласованность модели с точки зрения нахождения правильного набора ненулевых параметров, а также их знаков, может быть достигнута путем Нормализации (Normalization) C.
Инициируем два алгоритма LinearSVC c двумя типами наказаний. Для классифицирующих моделей, особенно для метода опорных векторов, используют свой вид потерь – Потери Шарнира (Hinge Loss). Параметризуем цвета кривых обучения:
Настроим функцию графика, отображающего динамику параметра C для разных частей датасетов:
На двух рисунках ниже показаны значения C на оси x и соответствующие баллы Кросс-валидации (Cross Validation) на оси y для нескольких различных частей сгенерированного набора данных:
Теория гласит, что для достижения согласованности прогнозирования параметр штрафа l2 должен оставаться постоянным по мере роста количества выборок:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Фото: @sabeerdarr
Автор оригинальной статьи: Felipe
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курс «Введение в Машинное обучение» на Udemy.