Компьютерное зрение — это область компьютерных наук, которая фокусируется на воспроизведении частей сложной системы зрения человека и позволяет компьютерам идентифицировать и обрабатывать объекты на изображениях и видео, а также людей. Ранние эксперименты в области компьютерного зрения начались в 1950-х годах и впервые были коммерчески использованы для различения печатного и рукописного текста в 1970-х годах. Сегодня приложения компьютерного зрения выросли в геометрической прогрессии. В этой статье показан пример как можно распознавать дорожные знаки с помощью компьютерного зрения.

Набор данных дорожных знаков
В рамках этой статьи используется общедоступный набор данных, доступный в Kaggle: GTSRB — это мультиклассовая задача классификации одного изображения, которая проводилась на Международной совместной конференции по нейронным сетям (IJCNN) 2011. Набор данных содержит более 50 000 изображений различных дорожных знаков и классифицируется на 43 различных класса. Он весьма разнообразен: некоторые классы содержат много изображений, а некоторые классы - несколько изображений.
Изучение набора данных
В начале импортируем все необходимые библиотеки.
import os
import matplotlib
import numpy as np
from PIL import Image
from tensorflow.keras.preprocessing.image import img_to_array
from sklearn.model_selection import train_test_split
from keras.utils import to_categorical
from keras.models import Sequential, load_model
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
Для тренировки нейронной сети будем использовать изображения из папки «train», которая содержит 43 папки отдельных классов. Инициализируем два списка: data и labels. Эти списки будут нести ответственность за хранение наших изображений, которые мы загружаем, вместе с соответствующими метками классов.
data = []
labels = []
Далее, с помощью модуля os мы перебираем все классы и добавляем изображения и их соответствующие метки в список data и labels. Для открытия содержимого изображения используется библиотека PIL.
for num in range(0, classes):
path = os.path.join('train',str(num))
imagePaths = os.listdir(path)
for img in imagePaths:
image = Image.open(path + '/'+ img)
image = image.resize((30,30))
image = img_to_array(image)
data.append(image)
labels.append(num)
Этот цикл просто загружает и изменяет размер каждого изображения до фиксированных 30×30 пикселей и сохраняет все изображения и их метки в списках data и labels.
Затем нужно преобразовать список в массивы numpy для подачи в модель.
data = np.array(data)
labels = np.array(labels)
Форма данных - (39209, 30, 30, 3), означает, что имеется 39 209 изображений размером 30×30 пикселей, а последние 3 означают, что данные содержат цветные изображения (значение RGB).
print(data.shape, labels.shape)
(39209, 30, 30, 3) (39209,)
Из пакета sklearn мы используем метод train_test_split() для разделения данных обучения и тестирования, используя 80% изображений для обучения и 20% для тестирования. Это типичное разделение для такого объема данных.
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(31367, 30, 30, 3) (7842, 30, 30, 3) (31367,) (7842,)
Давайте проверим, сколько классов у нас есть и сколько изображений в обучающем наборе для каждого класса и построим диаграмму распределения классов.
def cnt_img_in_classes(labels):
count = {}
for i in labels:
if i in count:
count[i] += 1
else:
count[i] = 1
return count
samples_distribution = cnt_img_in_classes (y_train)
def diagram(count_classes):
plt.bar(range(len(dct)), sorted(list(count_classes.values())), align='center')
plt.xticks(range(len(dct)), sorted(list(count_classes.keys())), rotation=90, fontsize=7)
plt.show()
diagram(samples_distribution)
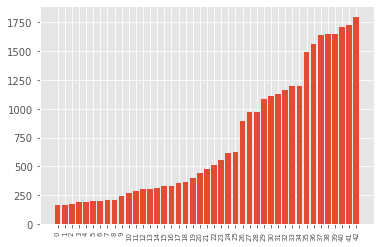
Из графика видно, что обучающий набор данных не сбалансирован, но мы можем справиться с этим фактом, используя метод увеличения данных.
def aug_images(images, p):
from imgaug import augmenters as iaa
augs = iaa.SomeOf((2, 4),
[
iaa.Crop(px=(0, 4)),
iaa.Affine(scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}),
iaa.Affine(translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}),
iaa.Affine(rotate=(-45, 45))
iaa.Affine(shear=(-10, 10))
])
seq = iaa.Sequential([iaa.Sometimes(p, augs)])
res = seq.augment_images(images)
return res
def augmentation(images, labels):
min_imgs = 500
classes = cnt_img_in_classes(labels)
for i in range(len(classes)):
if (classes[i] < min_imgs):
add_num = min_imgs - classes[i]
imgs_for_augm = []
lbls_for_augm = []
for j in range(add_num):
im_index = random.choice(np.where(labels == i)[0])
imgs_for_augm.append(images[im_index])
lbls_for_augm.append(labels[im_index])
augmented_class = augment_imgs(imgs_for_augm, 1)
augmented_class_np = np.array(augmented_class)
augmented_lbls_np = np.array(lbls_for_augm)
imgs = np.concatenate((images, augmented_class_np), axis=0)
lbls = np.concatenate((labels, augmented_lbls_np), axis=0)
return (images, labels)
X_train, y_train = augmentation(X_train, y_train)
После увеличения наш обучающий набор данных имеет следующую форму.
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
(36256, 30, 30, 3) (7842, 30, 30, 3) (36256,) (7842,)
Давайте еще раз проверим распределение данных.
augmented_samples_distribution = cnt_img_in_classes(y_train)
diagram(augmented_samples_distribution)
На графика видно, что наш набор стал более сбалансирован. Далее из пакета keras.utils мы используем метод to_categorical для преобразования меток, присутствующих в y_train и t_test, в one-hot encoding.
y_train = to_categorical(y_train, 43)
y_test = to_categorical(y_test, 43)
Построение нейронной сети
Для создания нейронной сети будет использоваться библиотека Keras. Чтобы классифицировать изображения по соответствующим категориям, мы построим модель CNN (сверточная нейронная сеть). CNN лучше всего подходит для целей классификации изображений.
Архитектура нашей модели:
- 2 Conv2D слоя (filter=32, kernel_size=(5,5), activation=”relu”)
- MaxPool2D слой ( pool_size=(2,2))
- Dropout слой (rate=0.25)
- 2 Conv2D слоя (filter=64, kernel_size=(3,3), activation=”relu”)
- MaxPool2D слой ( pool_size=(2,2))
- Dropout слой (rate=0.25)
- Flatten слой, чтобы сжать слои в 1 измерение
- Dense слой (500, activation=”relu”)
- Dropout слой (rate=0.5)
- Dense слой (43, activation=”softmax”)
class Net:
@staticmethod
def build(width, height, depth, classes):
model = Sequential()
inputShape = (height, width, depth)
if K.image_data_format() == 'channels_first':
inputShape = (depth, heigth, width)
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu', input_shape=inputShape))
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(classes, activation='softmax'))
return model
Обучение и проверка модели
Мы строим нашу модель вместе с оптимизатором Adam, а функция потерь — это categorical_crossentropy, потому что у нас есть несколько классов для категоризации. Затем обучаем модель с помощью функции model.fit().
epochs = 25
model = Net.build(width=30, height=30, depth=3, classes=43)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=64, validation_data=(X_test, y_test), epochs=epochs)
Как вы можете видеть, наша модель обучалась в течении 25 эпох и достигла 93% точности на тренировочном наборе данных. С помощью matplotlib мы строим график для точности и потерь.
plt.style.use("plot")
plt.figure()
N = epochs
plt.plot(np.arange(0, N), history.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), history.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), history.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), history.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.show()
Тестирование модели на тестовом наборе
Набор данных содержит папку «Test», а в файле Test.csv есть сведения, связанные с путем к изображению и метками классов. Мы извлекаем путь к изображению и метки из файла Test.csv с помощью фреймворка Pandas. Затем, мы изменяем размер изображения до 30×30 пикселей и делаем массив numpy, содержащий все данные изображения. С помощью accuracy_score из sklearn metrics проверяем точность предсказаний нашей модели. Мы достигли 96% точности на этой модели.
y_test = pd.read_csv('Test.csv')
labels = y_test["ClassId"].values
imgs = y_test["Path"].values
images=[]
for img in imgs:
image = Image.open(img)
image = image.resize((30,30))
images.append(img_to_array(image))
X_test=np.array(images)
pred = model.predict_classes(X_test)
print(accuracy_score(labels, pred))
0.958590657165479