
Функция потерь (Loss Function, Cost Function, Error Function; J) – фрагмент программного кода, который используется для оптимизации Алгоритма (Algorithm) Машинного обучения (ML). Значение, вычисленное такой функцией, называется «потерей».
Функция (Function) потерь может дать бо́льшую практическую гибкость вашим Нейронным сетям (Neural Network) и будет определять, как именно выходные данные связаны с исходными.
Нейронные сети могут выполнять несколько задач: от прогнозирования непрерывных значений, таких как ежемесячные расходы, до Бинарной классификации (Binary Classification) на кошек и собак. Для каждой отдельной задачи потребуются разные типы функций, поскольку выходной формат индивидуален.
С очень упрощенной точки зрения Loss Function может быть определена как функция, которая принимает два параметра:
- Прогнозируемые выходные данные
- Истинные выходные данные
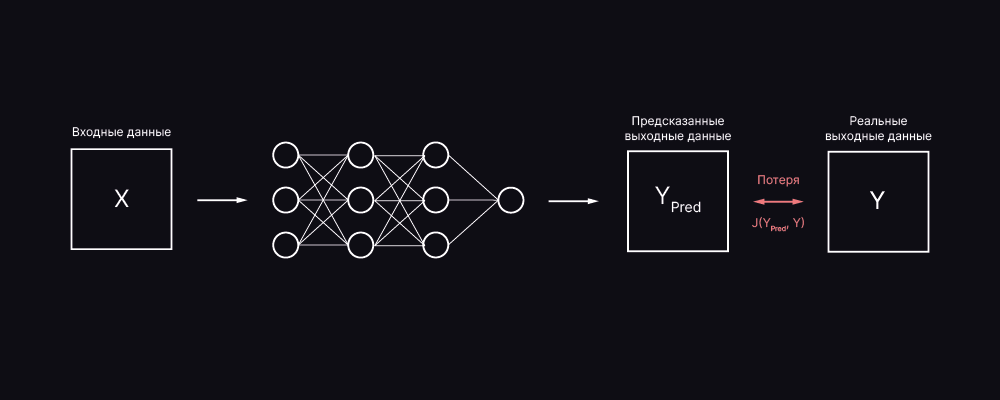
Эта функция, по сути, вычислит, насколько хорошо работает наша модель, сравнив то, что модель прогнозирует, с фактическим значением, которое она выдает. Если Ypred очень далеко от Yi, значение потерь будет очень высоким. Однако, если оба значения почти одинаковы, значение потерь будет очень низким. Следовательно, нам нужно сохранить функцию потерь, которая может эффективно наказывать модель, пока та обучается на Тренировочных данных (Train Data).
Этот сценарий в чем-то аналогичен подготовке к экзаменам. Если кто-то плохо сдает экзамен, мы можем сказать, что потеря очень высока, и этому человеку придется многое изменить внутри себя, чтобы в следующий раз получить лучшую оценку. Однако, если экзамен пройдет хорошо, студент может вести себя подобным образом и в следующий раз.
Теперь давайте рассмотрим классификацию как задачу и поймем, как в этом случае работает функция потерь.
Классификационные потери
Когда нейронная сеть пытается предсказать дискретное значение, мы рассматриваем это как модель классификации. Это может быть сеть, пытающаяся предсказать, какое животное присутствует на изображении, или является ли электронное письмо спамом. Сначала давайте посмотрим, как представлены выходные данные классификационной нейронной сети.
Количество узлов выходного слоя будет зависеть от количества классов, присутствующих в данных. Каждый узел будет представлять один класс. Значение каждого выходного узла по существу представляет вероятность того, что этот класс является правильным.
Как только мы получим вероятности всех различных классов, рассмотрим тот, что имеет наибольшую вероятность. Посмотрим, как выполняется двоичная классификация.
Бинарная классификация
В двоичной классификации на выходном слое будет только один узел. Чтобы получить результат в формате вероятности, нам нужно применить Функцию активации (Activation Function). Поскольку для вероятности требуется значение от 0 до 1, мы будем использовать Сигмоид (Sigmoid), которая приведет любое реальное значение к диапазону значений от 0 до 1.
По мере того, как входные реальные данные становятся больше и стремятся к плюс бесконечности, выходные данные сигмоида будут стремиться к единице. А когда на входе значения становятся меньше и стремятся к отрицательной бесконечности, на выходе числа будут стремиться к нулю. Теперь мы гарантированно получаем значение от 0 до 1, и это именно то, что нам нужно, поскольку нам нужны вероятности.
Если выход выше 0,5 (вероятность 50%), мы будем считать, что он попадает в положительный класс, а если он ниже 0,5, мы будем считать, что он попадает в отрицательный класс. Например, если мы обучаем нейросеть для классификации кошек и собак, мы можем назначить собакам положительный класс, и выходное значение в наборе данных для собак будет равно 1, аналогично кошкам будет назначен отрицательный класс, а выходное значение для кошек будет быть 0.
Функция потерь, которую мы используем для двоичной классификации, называется Двоичной перекрестной энтропией (BCE). Эта функция эффективно наказывает нейронную сеть за Ошибки (Error) двоичной классификации. Давайте посмотрим, как она выглядит.
Как видите, есть две отдельные функции, по одной для каждого значения Yi. Когда нам нужно предсказать положительный класс (Y = 1), мы будем использовать следующую формулу:
И когда нам нужно предсказать отрицательный класс (Y = 0), мы будем использовать немного трансформированный аналог:
Для первой функции, когда Ypred равно 1, потеря равна 0, что имеет смысл, потому что Ypred точно такое же, как Y. Когда значение Ypred становится ближе к 0, мы можем наблюдать, как значение потери сильно увеличивается. Когда же Ypred становится равным 0, потеря стремится к бесконечности. Это происходит, потому что с точки зрения классификации, 0 и 1 – полярные противоположности: каждый из них представляет совершенно разные классы. Поэтому, когда Ypred равно 0, а Y равно 1, потери должны быть очень высокими, чтобы сеть могла более эффективно распознавать свои ошибки.
Полиномиальная классификация
Полиномиальная классификация (Multiclass Classification) подходит, когда нам нужно, чтобы наша модель каждый раз предсказывала один возможный класс. Теперь, поскольку мы все еще имеем дело с вероятностями, имеет смысл просто применить сигмоид ко всем выходным узлам, чтобы мы получали значения от 0 до 1 для всех выходных значений, но здесь кроется проблема. Когда мы рассматриваем вероятности для нескольких классов, нам необходимо убедиться, что сумма всех индивидуальных вероятностей равна единице, поскольку именно так определяется вероятность. Применение сигмоида не гарантирует, что сумма всегда равна единице, поэтому нам нужно использовать другую функцию активации.
В данном случае мы используем функцию активации Softmax. Эта функция гарантирует, что все выходные узлы имеют значения от 0 до 1, а сумма всех значений выходных узлов всегда равна 1. Вычисляется с помощью формулы:
Пример:
Как видите, мы просто передаем все значения в экспоненциальную функцию. После этого, чтобы убедиться, что все они находятся в диапазоне от 0 до 1 и сумма всех выходных значений равна 1, мы просто делим каждую экспоненту на сумму экспонент.
Итак, почему мы должны передавать каждое значение через экспоненту перед их нормализацией? Почему мы не можем просто нормализовать сами значения? Это связано с тем, что цель Softmax – убедиться, что одно значение очень высокое (близко к 1), а все остальные значения очень низкие (близко к 0). Softmax использует экспоненту, чтобы убедиться, что это произойдет. А затем мы нормализуем результат, потому что нам нужны вероятности.
Теперь, когда наши выходные данные имеют правильный формат, давайте посмотрим, как мы настраиваем для этого функцию потерь. Хорошо то, что функция потерь по сути такая же, как у двоичной классификации. Мы просто применим Логарифмическую потерю (Log Loss) к каждому выходному узлу по отношению к его соответствующему целевому значению, а затем найдем сумму этих значений по всем выходным узлам.
Эта потеря называется категориальной Кросс-энтропией (Cross Entropy). Теперь перейдем к частному случаю классификации, называемому классификацией по нескольким меткам.
Классификация по нескольким меткам
Классификация по нескольким меткам (MLC) выполняется, когда нашей модели необходимо предсказать несколько классов в качестве выходных данных. Например, мы тренируем нейронную сеть, чтобы предсказывать ингредиенты, присутствующие на изображении какой-то еды. Нам нужно будет предсказать несколько ингредиентов, поэтому в Y будет несколько единиц.
Для этого мы не можем использовать Softmax, потому что он всегда заставляет только один класс "становиться единицей", а другие классы приводит к нулю. Вместо этого мы можем просто сохранить сигмоид на всех значениях выходных узлов, поскольку пытаемся предсказать индивидуальную вероятность каждого класса.
Что касается потерь, мы можем напрямую использовать логарифмические потери на каждом узле и суммировать их, аналогично тому, что мы делали в полиномиальной классификации.
Теперь, когда мы рассмотрели классификацию, перейдем к регрессии.
Потеря регрессии
В Регрессии (Regression) наша модель пытается предсказать непрерывное значение, например, цены на жилье или возраст человека. Наша нейронная сеть будет иметь один выходной узел для каждого непрерывного значения, которое мы пытаемся предсказать. Потери регрессии рассчитываются путем прямого сравнения выходного и истинного значения.
Самая популярная функция потерь, которую мы используем для регрессионных моделей, – это Среднеквадратическая ошибка (MSE). Здесь мы просто вычисляем квадрат разницы между Y и YPred и усредняем полученное значение.
Автор оригинальной статьи: deeplearningdemystified.com
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал . И попробуйте наши курсы по Машинному обучению на Udemy .