Shapash - это инструмент, который облегчает понимание моделей машинного обучения и анализа данных на Python.
Звучит, как описание практически любой библиотеки. Их развелось так много, что уже практически не веришь подобным описаниями. Многие специалисты хвалят Shapash за качественную и понятную визуализацию, другие за упорядоченность, третьи за возможность вывести полученные результаты через веб.
Так ли Shapash хорош на самом деле? Сейчас разберемся с его функционалом и проверим на конкретном примере.
Ключевые особенности Shapash

- Легко читаемые визуализации (не зависимо от уровня владение наукой о данных .
- Веб-приложение: позволяет покопаться в данных, просматривать графики, оценивать важность функций и глобальный вклад функции в модель.
- Препроцессинг, обратная обработка, постобработка - Вы можете легко добавить свои словари данных, объект category-encoders или трансформатор столбцов sklearn для более явных выходов.
- Функции для простого сохранения файлов Pickle и экспорта результатов в таблицы.
- Настраиваемая сводка отчета: можно выбрать, какие именно параметры учитывать. Удобно при детальном рассмотрении статистики и бизнес-процессов на разных уровнях производства.
- Возможность простого развертывания в производственной среде и завершения каждого прогноза / рекомендации с локальной сводкой объяснимости для каждого рабочего приложения (пакетного или API)
- Shapash подходит для нескольких способов применения: его можно использовать для легкого доступа к результатам или для работы над лучшей формулировкой.
Shapash работает с задачами регрессии, двоичной классификации или мультикласса. Он совместим со многими моделями:
- Catboost
- Xgboost
- LightGBM
- Sklearn Ensemble
- Linear models
- SVM
Shapash основан на локальных вкладах, рассчитанных с помощью Shapley Value, Lime или любого другого метода, который позволяет вычислять суммируемые локальные вклады.
Установка и начало работы
Вы можете установить пакет через pip:
$ pip install shapash
Сейчас мы рассмотрим, как можно использовать Shapash при работе с конкретной моделью. Для этого используем датасет со "стоимостью на жилье" от Kaggle, чтобы подобрать регрессор и спрогнозировать цены на недвижимость.
Начнем с загрузки набора данных:

Далее нужно закодировать категориальные признаки:
Обучаем, тестируем разделение и подгоняем модель:
И спрогнозируем тестовые данные:
y_pred = pd.DataFrame (reg.predict (Xtest), columns = ['pred'], index = Xtest.index)
Работа с Shapash SmartExplainer
Шаг 1 - Импорт
from shapash.explainer.smart_explainer import SmartExplainer
Шаг 2 - Инициализация SmartExplainer
xpl = SmartExplainer(features_dict=house_dict) # Optional parameter
*features_dict: dict, который определяет значение каждого имени столбца x pd.DataFrame.
Шаг 3 - Компиляция
Метод компиляции позволяет использовать еще один необязательный параметр: Postprocessing (Постобработка). Это дает возможность применять новые функции для указания лучшей формулировки (regex, mapping dict и т.д.)
Теперь мы можем отобразить результаты и понять, как работает регрессионная модель!
Шаг 4 - Запуск веб-приложения
app = xpl.run_app()
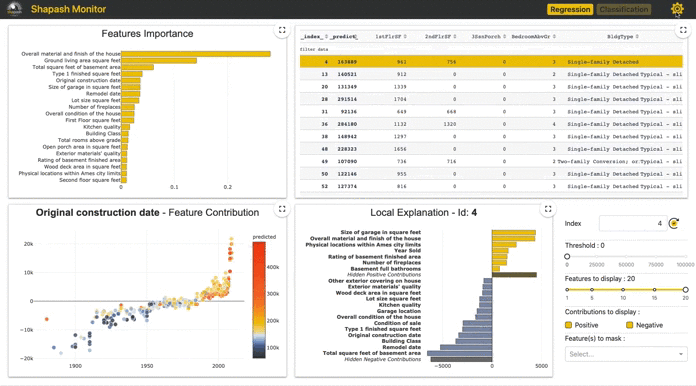
Ссылка на веб-приложение отображается в выходных данных Jupyter (смотреть здесь). Интерфейс разделен на четыре части и позволяет оценивать разные функции модели:
1. Features Importance: вы можете нажать на каждую функцию, чтобы обновить график.
2. Contribution plot: как функция влияет на прогноз? Визуализируйте диаграмму каждого локального вклада функции.
3. Local Plot:
- Локальное объяснение: какие функции больше всего влияют на прогнозируемое значение.
- Вы можете использовать несколько кнопок/списков для настройки сводки этой локальной объяснимости.
- Это веб-приложение - полезный инструмент, позволяющий обсудить с бизнес-аналитиками наилучший способ обобщения объяснимости для удовлетворения оперативных потребностей.
4. Selection Table позволяет пользователю веб-приложения выбирать:
- Подмножество, чтобы сосредоточить исследование на этом подмножестве;
- Одну строку для отображения соответствующего местного объяснения.
Как использовать таблицу данных для выбора подмножества? Вверху таблицы, чуть ниже имени столбца, который вы хотите использовать для фильтрации, укажите
- = Значение,> Значение, <Значение
- Если вы хотите выделить каждую строку, содержащую определенное слово, просто введите это слово без «=».
В этом веб-приложении доступно несколько опций. Одна из самых важных - размер выборки (по умолчанию: 1000). Чтобы избежать задержки, веб-приложение использует образец для отображения результатов. Используйте эту опцию, чтобы изменить размер выборки:
app.kill ()
Виды графиков
Все графики доступны в записных книжках jupyter, а ниже описаны ключевые моменты каждого графика.
Важность функции
Этот параметр позволяет сравнивать важность признаков подмножества. Полезно обнаруживать конкретное поведение в подмножестве.
Графики вклада
Они позволяют нам ответить на такие вопросы, как:
Как функция влияет на мой прогноз? Положительно ли это? Есть ли пороговые эффекты? Какую роль играет каждая модальность для категориальной переменной?
Этот график завершает важность функций для интерпретируемости, общей понятности модели, чтобы лучше понять влияние функции на модель.
На графике ниже есть несколько параметров. Обратите внимание, что он адаптируется в зависимости от того:
- Интересует ли вас категориальная или непрерывная переменная.
- Какой типа использования рассматриваете (регрессия, классификация)
xpl.plot.contribution_plot("OverallQual")
График влияния, примененный к непрерывному объекту.
Пример классификации: пассажиры «Титаника» - график влияния, примененный к категориальному признаку.
Локальный график
Методы filter() и local_plot() позволяют протестировать и выбрать наилучший способ суммирования сигнала, который уловила модель. Вы можете использовать его во время исследовательской фазы, затем развернуть отчет в рабочей среде, чтобы конечный пользователь за несколько секунд понял, какие критерии являются наиболее важными для каждой рекомендации.
Объединение filter и local_plot
Используйте фильтрацию, чтобы указать, как суммировать локальную объяснимость. У вас есть четыре параметра для настройки вашей сводки:
- max_contrib: максимальное количество критериев для отображения
- threshold: минимальное значение вклада (в абсолютном значении), необходимое для отображения критерия
- positive: отображение только положительного вклада
- features_to_hide: список функций, которые вы не хотите отображать
После определения этих параметров мы можем отобразить результаты с помощью local_plot () или экспортировать их с помощью to_pandas ().
xpl.filter(max_contrib=8,threshold=100)
xpl.plot.local_plot(index=560)
Экспорт в pandas DataFrame:
xpl.filter(max_contrib=3,threshold=1000)
summary_df = xpl.to_pandas()
summary_df.head()
Сравнение графиков
С помощью метода compare_plot () SmartExplainer позволяет понять, почему два или более индивидов не имеют одинаковых предсказанных значений. Определяющий критерий появляется вверху графика.
xpl.plot.compare_plot (row_num = [0, 1, 2, 3, 4], max_features = 8)
Заключение
Shapash - действительно богатый функции пакет, который может значительно упростить жизнь и при анализе данных, и доработке модели машинного обучения.
В нем нет ничего сверхреволюционного, но совокупность возможностей, собранных в одной библиотеке, позволяет закрывать множество задач с помощью всего одного инструмента.
Пользоваться им или нет - решать вам, но ознакомиться лично было бы полезно. Расскажите в комментариях, дали бы вы шанс Shapash или лучше воспользуетесь проверенными и отработанными способами?
Другие наши статьи: