Распараллеливайте любую функцию с помощью одного декоратора

Все мы знаем, что Python - не самый быстрый язык программирования. Его механизм глобальной блокировки интерпретатора (GIL) позволяет только одному потоку одновременно выполнять байт-код Python. Вы можете избежать этого ограничения, изменив интерпретатор или реализовав методы параллелизма на основе процессов.
Я уже говорил о параллелизме в Python, поэтому обязательно ознакомьтесь с этими статьями, если вы не знакомы с этой темой:
Python Parallelism: важное руководство по ускорению написания кода Python за считанные минуты
Параллелизм в Python: как ускорить код с помощью потоков
Эти методы работают как шарм, но есть более простая альтернатива - параллельная обработка с помощью библиотеки Dask.
Если вы не знакомы с Dask, это в основном эквивалент Pandas для больших наборов данных. Это чрезмерное упрощение, поэтому, пожалуйста, прочтите больше о библиотеке здесь.
Эта статья построена следующим образом:
описание проблемы
Тест: последовательное выполнение задач
Тест: выполнение задач параллельно с Dask
Заключение
Вы можете скачать исходный код этой статьи здесь.
*******
Описание проблемы
Цель состоит в том, чтобы подключиться к jsonplaceholder.typicode.com - бесплатному поддельному REST API.
Вы подключитесь к нескольким конечным точкам и получите данные в формате JSON. Всего будет шесть конечных точек. Не очень много, и Python, скорее всего, выполнит задачу за секунды. Не слишком хорош для демонстрации возможностей параллелизма, поэтому мы немного оживим.
Помимо получения данных API, программа также будет спать на секунду между выполнением запросов. Поскольку существует шесть конечных точек, программа не должна ничего делать в течение шести секунд - но только тогда, когда вызовы выполняются последовательно.
Следующий фрагмент кода импортирует необходимые библиотеки, объявляет список URL-адресов и функцию для получения данных с одного URL-адреса:
import time
import requests
from dask import delayed, compute
URLS = [
'https://jsonplaceholder.typicode.com/posts',
'https://jsonplaceholder.typicode.com/comments',
'https://jsonplaceholder.typicode.com/albums',
'https://jsonplaceholder.typicode.com/photos',
'https://jsonplaceholder.typicode.com/todos',
'https://jsonplaceholder.typicode.com/users'
]
def fetch_single(url: str) -> None:
print(f'Fetching: {url}...')
req = requests.get(url)
time.sleep(1)
print(f'Fetched {url}!')
return req.content
Давайте сначала проверим время выполнения без параллелизма.
Тест: последовательное выполнение задач
%%time
fetch_normal = []
for url in URLS:
single = fetch_single(url)
fetch_normal.append(single)
После выполнения этой ячейки вы увидите аналогичный результат:
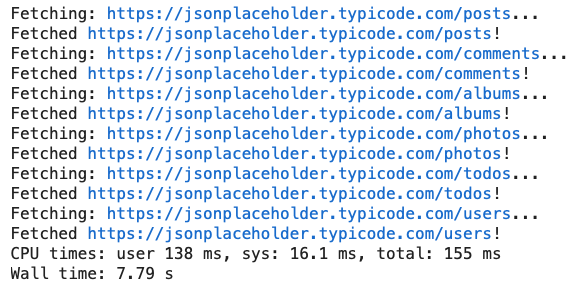
Ничего удивительного в этом нет - Python извлекает данные из конечных точек API в объявленном порядке, и это заняло около 8 секунд, в основном из-за вызовов sleep ().
Как оказалось, эти вызовы API независимы и могут вызываться параллельно. Посмотрим, как это сделать дальше.
Тест: выполнение задач параллельно с Dask
Придется немного изменить код. Первое, что нужно сделать, это обернуть нашу функцию fetch_single отложенным декоратором. Выйдя из цикла, мы также должны вызвать функцию вычисления из Dask для каждого элемента в массиве fetch_dask, поскольку вызов delayed не выполняет вычислений.
Вот весь код:
%%time
fetch_dask = []
for url in URLS:
single = delayed(fetch_single)(url)
fetch_dask.append(single)
results_dask = compute(*fetch_dask)
Альтернативой обертке функции отложенным декоратором является использование обозначения @delayed над объявлением функции. Не стесняйтесь использовать любой.
В любом случае результаты выполнения показаны на изображении ниже:
Как видите, порядок печати другой. Это потому, что Даску было поручено запускать все задачи по отдельности. Общее время выполнения было чуть менее 1,5 секунд, из которых 1 секунда использовалась для сна.
Хорошее улучшение в целом.
Остается вопрос - идентичны ли возвращаемые результаты? Ну и да, и нет. Значения, полученные в последовательном примере, находятся в списке, тогда как значения, полученные после вызова compute, находятся в кортеже.
Следующее изображение подтверждает, что:
В результате мы не можем сравнивать структуры данных напрямую, но можем провести сравнение после преобразования второй в список:
Окончательный ответ - да - вы получите одинаковые результаты с обоими подходами, но распараллеливание занимает меньше времени.
***
Заключение.
Реализация параллелизма в ваших приложениях или конвейерах обработки данных требует много обдумывания. К счастью, реализация в коде тривиальна, так как нужны всего две функции.
Хорошая новость в том, что вы можете использовать Dask для распараллеливания практически всего. От загрузки базовых наборов данных, статистических сводок до обучения модели - Dask справится с этим.
Напишите в комментариях, если вам нужен более продвинутый учебник по Dask, основанный на науке о данных.