
Microsoft наконец анонсировала коннектор для файлов Parquet в ноябре 2020 года. Формат файлов Parquet разработан фондом Apache как проект с открытым исходным кодом, который стал фундаментальной частью большинства систем Delta Lake в настоящее время.
«Apache Parquet - это столбчатый формат хранения, доступный для любого проекта в экосистеме Hadoop, независимо от выбора структуры обработки данных, модели данных или языка программирования».
Однако Parquet - это всего лишь формат файла, который на самом деле не особо удобен, когда дело доходит до управления данными. Общие операции обработки данных (DML ), такие как обновления и удаления, по-прежнему необходимо обрабатывать вручную конвейером данных. Это было одной из причин, по которой Delta Lake (delta.io ) была разработана помимо множества других функций, таких как транзакции ACID, правильная обработка метаданных и многое другое.
По сути, таблица Delta Lake - это папка в вашем Data Lake (или в другом месте, где вы храните свои данные) и состоит из двух частей:
- Файлы журнала дельты (в подпапке _delta_log)
- Файлы данных (файлы Parquet в корневой папке или подпапках, если используется разделение)
В журнале Delta сохраняются все транзакции, которые изменили данные или метаданные в таблице. Например, если вы выполняете оператор INSERT, новая транзакция создается в журнале Delta, и новый файл добавляется к файлам данных, на которые ссылается журнал Delta. Если выполняется инструкция DELETE, определенный набор файлов данных (логически) удаляется из журнала Delta, но файл данных все еще находится в папке в течение определенного времени. Таким образом, мы не можем просто прочитать все файлы Parquet в корневой папке, но должны сначала обработать журнал Delta, чтобы мы знали, какие файлы Parquet действительны для последнего состояния таблицы.
Эти журналы обычно хранятся в виде файлов JSON (точнее, файлов JSONL ). После 10 транзакций создается так называемый файл контрольной точки в формате Parquet, в котором хранятся все транзакции до этого момента времени. Соответствующие журналы для итоговой таблицы представляют собой комбинацию последнего файла контрольной точки и файлов JSON, которые были созданы впоследствии.
Из этих журналов мы получаем информацию и какие файлы Parquet в основной папке необходимо обработать для получения итоговой таблицы. Затем содержимое этих файлов Parquet можно просто объединить и загрузить в Power BI.
Мы инкапсулировали всю эту логику в настраиваемую функцию Power Query, которая принимает на вход список папок с таблицей Delta и возвращает содержимое таблицы Delta. Список папок может поступать из хранилища Delta Lake Azure, локальной папки или хранилища BLOB-объектов Azure. Обязательные поля / столбцы: [Содержание], [Имя] и [Путь к папке]. Существует также необязательный параметр, который позволяет вам указать дополнительные параметры для чтения таблицы Delta, например Version, если вы хотите использовать путешествие во времени. Однако это все еще эксперимент, и если вы хотите получить последнее состояние таблицы, вы можете просто опустить его.
Остается работа с M-кодом для функции:
После того, как вы добавили функцию в среду PowerBI / Power Query, вы можете вызвать ее так:
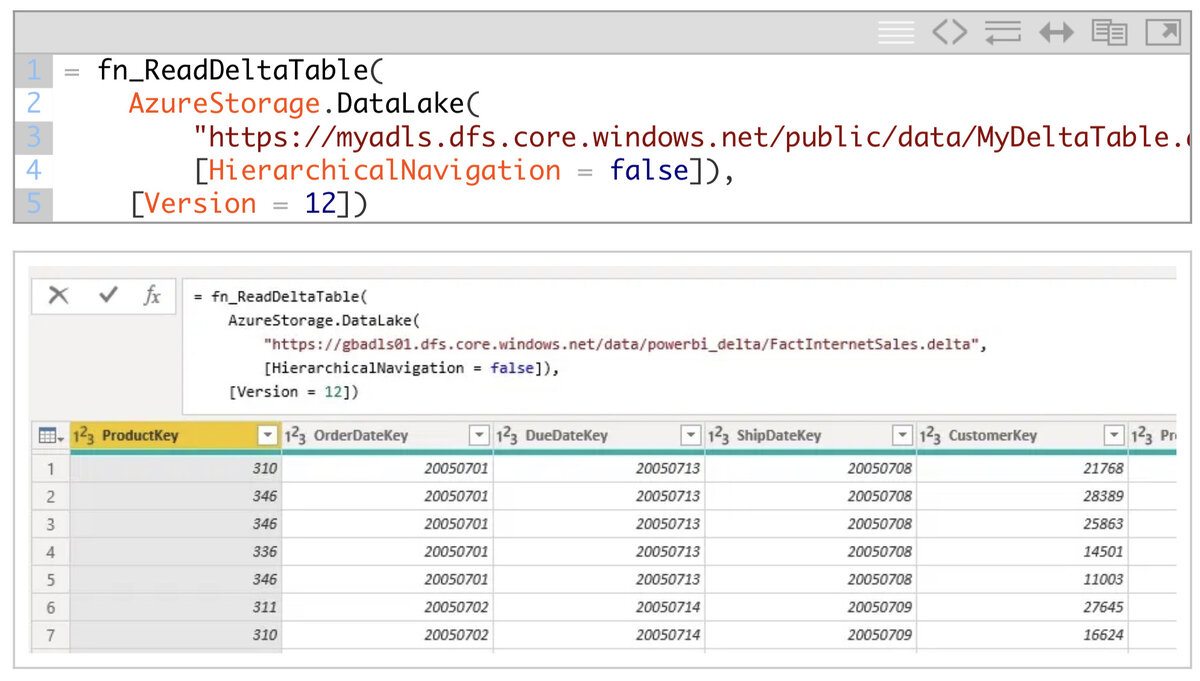
Кроме того, рекомендуется вложить ваши запросы и разделить доступ к хранилищу (например, Azure Data Lake Store) и чтение таблицы (выполнение функции). Если вы используете для ADLS, обязательно также укажите [HierarchicalNavigation = false]!
Если вы читаете данные из хранилища BLOB-объектов, стандартный список папок немного отличается и его необходимо изменить:
let
Source = AzureStorage.Blobs("https://myadls.blob.core.windows.net/public"),
#"Filtered Rows" = Table.SelectRows(Source, each Text.StartsWith([Name], "data/MyDeltaTable.delta")),
#"Added FullPath" = Table.AddColumn(#"Filtered Rows", "FullPath", each [Folder Path] & "/" & [Name], Text.Type),
#"Removed Columns" = Table.RemoveColumns(#"Added FullPath",{"Name", "Folder Path"}),
#"Split Column by Delimiter" = Table.SplitColumn(#"Removed Columns", "FullPath", Splitter.SplitTextByEachDelimiter({"/"}, QuoteStyle.Csv, true), {"Folder Path", "Name"}),
#"Append Delimiter" = Table.TransformColumns(#"Split Column by Delimiter",{{"Folder Path", (_) => _ & "/", type text}})
in
#"Append Delimiter"
В настоящий момент разъем / функция все еще экспериментальны, и производительность еще не оптимальна. Это исправится в ближайшем будущем, чтобы иметь собственный способ чтения и, наконец, визуализации таблиц Delta Lake в PowerBI.
Актуальные ограничения:
Разделенные таблицы
- в настоящее время столбцы, используемые для разделения, всегда будут иметь значение NULL
- значения для разделения столбцов не сохраняются как часть файла, но должны быть получены из пути к папке
Представление
- в настоящее время не очень хорошо, но это в основном связано с разъемом Parquet, как кажется
Путешествие во времени
- в настоящее время поддерживает только “VERSION AS OF”
- нужно добавить “TIMESTAMP AS OF”
Predicate Pushdown / Удаление разделов
- в настоящее время не поддерживается - всегда читает всю таблицу
Наши курсы по Power BI:
Курс Финансовый анализ в Power BI
Наши каналы: