
Источник: Nuances of Programming
Честно вам признаюсь — бенчмаркинг (тестирование производительности) не входит в число моих самых сильных сторон, к тому же и провожу я его не так часто, как хотелось бы. Но с момента программирования на Go в качестве основного моего языка случаи его применения намного участились. А все потому, что Go предоставляет отличную встроенную поддержку для бенчмаркинга.
Go позволяет разработчикам тестировать производительность с помощью пакета testing , содержащего для этого все необходимое.
В статье мы подробно рассмотрим процесс бенчмаркинга, начав с самых азов. Надеюсь, что после знакомства с материалом вы начнете лучше разбираться в бенчмарках.
Итак, в программировании под бенчмаркингом понимают тестирование производительности написанного кода.
“Бенчмарк — это выполнение компьютерной программы (набора программ) или других операций для оценки относительной производительности объекта”.
Бенчмаркинг позволяет рассмотреть разные решения, протестировать их производительность и сравнить полученные показатели скорости. Разработчику, как никому другому, нужны эти полезные данные, особенно при необходимости ускорить и оптимизировать работу приложения.
Важно помнить золотое правило разработки: никакой преждевременной оптимизации. Умение проводить бенчмаркинг не означает, что нужно выполнять и тестировать каждый участок кода. Этот инструмент нужен в тех случаях, когда вы сталкиваетесь с проблемами производительности или не можете устоять перед напором внутреннего любопытства.
“Преждевременная оптимизация — это корень всех зол”. — Дональд Кнут, “ Искусство программирования”.
Довольно часто в сообщениях на интернет-форумах начинающие разработчики спрашивают, какое из тех или иных решений кода является наилучшим. Но я бы не стал оценивать код в категориях “лучший ”.
Предпочитаю придерживаться формулировки “наиболее эффективный ”. Ведь иногда более медленный код проще обслуживать и читать, и в таком случае я сочту его лучшим вариантом, если, конечно, речь не идет о производительности.
Теперь научимся проводить бенчмарк в Go. Нам предстоит ответить на следующие вопросы:
- Что быстрее: срезы (slice) или карты (map)?
- Влияет ли размер на скорость срезов и карт?
- Имеет ли значение тип ключа в картах?
Пишем самый простой бенчмарк
Прежде чем ответить на эти вопросы, создадим простой бенчмарк и покажем, как его осуществить в Golang. После этого будем его дорабатывать, чтобы получить ответы на поставленные вопросы.
Сначала запускаем новый проект, чтобы вы тоже могли включиться в работу. Далее создаем директорию и выполняем:
go mod init benching
Потребуется также создать файл, оканчивающийся на _test.go . В нашем случае им будет benching_test.go .
Подобно обычным модульным тестам, бенчмарки в Go выполняются с помощью пакета testing и запускаются теми же инструментами тестирования.
Инструмент Go определяет, какие методы являются бенчмарками по их именам. Любой метод, начинающийся с Benchmark и принимающий указатель на testing.B , будет выполняться как бенчмарк. Данный фрагмент иллюстрирует пример такого минимального метода:
Испытаем его, выполнив команду go test с флагом -bench=.
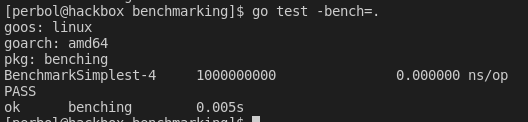
Остановимся на этом моменте подробнее и проанализируем вывод. По завершении каждый бенчмарк выводит 3 значения: имя, количество выполнений и ns/op .
Первое значение говорит само за себя — это имя, которое мы задаем в тестовом файле.
Интерес представляет второе значение, а именно количество выполнений. Каждый бенчмарк выполняется по многу раз, при этом измеряется время каждого из них. На основе общего количества подсчитывается среднее время выполнения. И это правильно, поскольку статистические данные, основанные на одном выполнении бенчмарка, будут ошибочными.
ns/op означает число наносекунд, затраченных на операцию. Это время, которое потребовалось на вызов метода.
Если из большого числа бенчмарков вы хотите выполнить только один или несколько, можно заменить точку на строку в соответствии с такими именами, как -bench=BenchmarkSimplest . Напоминаю, что -bench=Benchmark по-прежнему будет запускать бенчмарк, поскольку строка соответствует началу метода.
Теперь мы можем измерить скорость и не только. К счастью, заглянув в пакет testing , мы обнаружим, что добавление флага -benchmem позволит получить дополнительную информацию о том, сколько было выделено байт за операцию (B/op), а также сколько раз за операцию выделялась память (allocs/op).
Мы уже почти готовы тестировать реальные процессы, но уделим внимание еще ряду моментов. Что происходит с входным параметром *testing.B в нашем бенчмарке? Чтобы понять, с чем мы имеем дело, ознакомимся с его определением, предложенным в стандартной библиотеке (golang/src/testing/benchmark.go).
Testing.B содержит любые данные, относящиеся к выполняемому бенчмарку, а также структуру BenchmarkResult для форматирования вывода. Если какая-то часть вывода вам непонятна, то настоятельно рекомендую открыть benchmark.go и прочитать код.
Особое внимание заслуживает переменная N . Как вы помните, бенчмарки выполняются по многу раз. Так вот, переменная N в testing.B как раз и указывает на количество выполнений.
Согласно документации в бенчмарках это необходимо иметь в виду, поэтому обновляем BenchmarkSimplest с учетом N .
// BenchmarkSimplestNTimes выполняет бенчмарк N раз.
func BenchmarkSimplestNTimes (b *testing.B) {
for i := 0 ; i < b.N; i++ {
// Здесь выполняем функцию для тестирования
}
}
Мы обновили функцию, создав цикл for , который перебирает N раз. При проведении тестирования я устанавливаю конкретные значения N , обеспечивая адекватность бенчмарков. В противном случае один из них выполнится 100 000 раз, а другой — дважды.
Для этого можно добавить флаг -benchtime= . Входными данными являются либо секунды, либо X раз, поэтому для стократного выполнения бенчмарка устанавливаем его на -benchtime=100x .
На старт, внимание, бенчмарк!
Приступаем к тестированию и ответам на ранее заданные вопросы о производительности.
- Что быстрее: срезы или карты?
- Влияет ли размер на скорость срезов и карт?
- Имеет ли значение тип ключа в картах?
Начнем реализацию одного бенчмарка для оценки записи данных в карты и срезы, а другого — для оценки их обратного считывания. У разработчика Дейва Чини я позаимствовал один прием — создание метода, принимающего входные параметры, которые мы хотим протестировать. С его помощью можно запросто проверять много различных значений.
// insertXIntMap применяется для добавления Х элементов в Map[int]int
func insertXIntMap (x int , b *testing.B) {
// Инициализируем Map и вставляем X элементов
testmap := make(map [int ]int , 0 )
// Сбрасываем таймер после инициализации Map b.ResetTimer()
for i := 0 ; i < x; i++ {
// Вставляем значение I в ключ I.
testmap[i] = i
}
}
Этот метод принимает целочисленное значение, указывающее на количество целых чисел, которое нужно записать в карту. С его помощью мы протестируем, влияет ли размер карты на эффективность внедрения элементов. Метод будет выполняться нашими бенчмарками. Еще я создал несколько тестирующих функций, каждая из которых вставляет разное целое число.
Ниже представлены методы бенчмарков, которые выполняются N раз и записывают X элементов в карту.
Заметили, как я повторно задействовал один и тот же метод в каждом бенчмарке, лишь меняя число вставляемых элементов? Весьма ловкий прием, позволяющий легко тестировать большие и маленькие размеры.
Количество затраченного времени растет, что закономерно в связи с увеличением количества вставок. Пока эти результаты особо ни о чем не говорят, поскольку их не с чем сравнивать. Однако можно выделить время для ответа на один из вопросов: “Имеет ли значение тип ключа в картах?”.
Скопируем все методы и заменим используемый тип ключа интерфейсом. В этот раз у нас будет всего 2 файла: benching_map_interface_test.go и benching_map_int_test.go . Методы бенчмарков будут соответствовать имени для поддержания легко управляемой структуры при добавлении дополнительных бенчмарков.
Ниже следует пример тестирования записи в карту с интерфейсом в качестве ключа:
Ответ на один из вопросов получен. Судя по результатам, тип ключа немаловажен. В этом тесте Int в качестве ключа вместо Interface в 2.23 раза быстрее, учитывая показатели бенчмарка 1000000 . Хотя я не припомню, чтобы интерфейс когда-либо применялся в качестве ключа.
- Что быстрее: срезы или карты?
- Влияет ли размер на скорость срезов и карт?
- Имеет ли значение тип ключа в картах? Да, имеет .
Перед тем, как двигаться дальше, добавим ради интереса новый бенчмарк. В предыдущих тестах размер карт не был предустановлен заранее. Теперь мы это изменим и проверим, в чем же отличие.
Но прежде нам предстоит изменить метод insertXIntMap , а также инициализацию карты на использование длины X. Был создан новый файл benching_map_prealloc_int_test.go , в котором я изменил метод insertXIntMap для предварительной инициализации размера. ‘make(map[int]int, 0)’ был заменен на ‘make(map[int]int,x)’.
// insertXPreallocIntMap - для добавления X элементов в Map[int]int
func insertXPreallocIntMap (x int , b *testing.B) {
// Инициализируем Map, вставляем X элементов и заранее предустанавливаем размер X
testmap := make(map [int ]int , x)
// Сбрасываем таймер после инициализации Map b.ResetTimer()
for i := 0 ; i < x; i++ {
// Вставляем значение I в ключ I.
testmap[i] = i
}
}
Напоминаю, что мы можем управлять выполнением тех или иных бенчмарков с помощью флага -bench= . Теперь самое время вспомнить этот прием, учитывая их немалое количество. Но задача именно этого бенчмарка — сравнить производительность карт с предустановленным размером и без него.
Новые бенчмарки я назвал BenchmarkInsertIntMapPrealloc , чтобы их имена совпадали с BenchmarkInsertIntMap , что можно будет использовать в качестве триггера. Этот новый файл является точной копией другого бенчмарка IntMap — изменились лишь имена и метод, подлежащий выполнению.
Выполняем бенчмарк и меняем флаг -bench= .
go test -bench=BenchmarkInsertIntMap -benchmem -benchtime=100x
Согласно результатам бенчмарка, предустановка размера карты играет значимую роль — достаточно лишь увидеть, что производительность теста 1000000 в 1.92 раза больше, а показатели B/op еще лучше.
Далее перейдем к реализации бенчмарка записи в срезы. Ее принцип аналогичен реализации карты с той лишь разницей, что срез используется с append .
Опять-таки ради интереса напишем бенчмарки для предустановленных и непредустановленных размеров срезов. Заново создаем метод insertX , все копируем и затем заменяем Map на Slice . Итак, записываем в срез X элементов для тестирования вставки.
Бенчмарк добавления срезов:
Для среза, под который выделена память, инструкция append не применяется, поскольку она добавляет ему индекс, в связи с чем срез вынужден изменяться для использования нового верного индекса.
// insertXPreallocIntSlice - для добавления X элементов в []int
func insertXPreallocIntSlice (x int , b *testing.B) {
// Инициализация Slice и вставка X элементов
testSlice := make([]int , x)
// Сброс таймера
b.ResetTimer()
for i := 0 ; i < x; i++ {
testSlice[i] = i
}
}
Полный вариант кода для тестирования среза в предварительно выделенной памяти:
Бенчмарки срезов готовы, пора их выполнить и посмотреть результаты:
Разница между предустановленными и динамическими срезами просто огромная. Показатели бенчмарка 1000000 составляют соответственно 7246 ns/op против 75388 ns/op , т. е. скорость выполнения операции в первом случае в 10.4 раз больше, чем во втором. Однако в некоторых ситуациях работать со срезами фиксированного размера бывает проблематично. Что касается моих приложений, то обычно я не знаю размер срезов, поскольку они, как правило, динамические.
Похоже, что срезы превосходят карты, когда дело касается вставки данных как маленького, так и большого размера. На следующем этапе протестируем, как происходит выборка данных.
Для этого инициализируем срез и карту по аналогии с предыдущими вариантами, добавим X элементов и сбросим таймер. Затем протестируем, как быстро мы сможем найти X элементов. Я перебираю срез и карту со значением индекса i . Ниже представлен код обоих бенчмарков, поскольку они почти идентичны.
Бенчмарк выборки из карты:
Бенчмарк выборки из среза:
Как вы заметили, код для selectXIntSlice и selectXIntMap один и тот же, единственное отличие — команда make . Про разницу в производительности и говорить нечего — все очевидно.
Сравним результаты бенчмарка
Итак, теперь у нас есть результаты тестирования. Для более простого сравнительного анализа оформим в таблицу показатели всех бенчмарков с 1000000 элементов.
Benchmark,Type,ns/op,B/op,allocs/op,Fixed-size
Insert ,Map [interface ]int ,3730206 ,1318557 ,10380 ,no Insert ,Map [int ]int ,1632196 ,879007 ,381 ,no Insert ,Map [int ]int ,857588 ,1569 ,0 ,yes
Insert ,[]int ,75388 ,451883 ,0 ,no Insert ,[]int ,7246 ,0 ,0 ,yes
Select ,Map [int ]int ,507843 ,0 ,0 ,yes
Select ,[]int ,2866 ,0 ,0 ,yes
Насколько сильно отличаются результаты срезов и карт?
Срезы быстрее в 21.65 раз (1321196/75388), если сравнивать производительность записи в их динамическую форму.
Срезы быстрее в 118.35 раз (857588/7246 ) при сравнении производительности записи в их форму с предустановленным размером.
Срезы быстрее в 117.19 раз (507843/2866) при сравнении производительности считывания.
Что быстрее: срезы или карты?
Судя по результатам этих бенчмарков, срезы намного превосходят карты. Разница настолько большая, что закрадывается мысль, а не совершил ли я где ошибку.
Но зато карты проще в использовании. В данных бенчмарках предполагалось, что индексы в срезах известны. Однако есть много случаев, когда мы их не знаем, так что приходится перебирать весь срез, например map[userID]User вместо цикла for для []User .
Влияет ли размер на скорость срезов и карт?
Размер в этих случаях не имеет значения.
Имеет ли значение тип ключа в картах?
Имеет. Применение целого числа по сравнению с интерфейсом оказалось в 2.23 раза быстрее.
Рассмотрим более реалистичный случай
Похоже, что срезы отличаются намного более высокой производительностью, но буду с вами честен — верный индекс для них мне практически никогда неизвестен. Чаще всего приходится перебирать весь срез для поиска нужного элемента. Именно по этой главной причине я, как правило, предпочитаю карты.
Создадим бенчмарк как раз для такого случая. У нас есть map[userID]User и []User . Тест нацелен на сравнение скоростных показателей нахождения конкретного пользователя в картах и срезах.
Я создал новый файл, содержащий код для генерации случайных пользователей, количество которых в срезе и карте составило 10 000, 100 000 и 1 миллион. Допустим, что у нас есть API, и нам был отправлен ID пользователя, которого нужно найти. Далее следует сценарий, подлежащий тестированию. Я также перемешиваю срез для имитации реальной ситуацией, когда данные добавляются динамически.
Этот бенчмарк я назвал “Спасти рядового Райана”. Вот его мы и будем искать по ID пользователя 7777 . Ниже представлен бенчмарк более реалистичного случая использования срезов и карт:
Как видите, срез больше не превосходит карту по производительности. Результаты показывают, что карта поддерживает одинаковую скорость независимо от количества элементов в ней, тогда как срез тратит больше времени на каждый добавленный элемент.
Type,Users,ns/op
Slice,10000 ,1763 Slice,100000 ,72760 Slice,100000 ,140917 Map ,10000 ,21.8 Map ,100000 ,19.5 Map ,100000 ,21.1
На этот раз производительность карты превосходит срез в 6 678.53 раза.
Заключение
Что быстрее: срезы или карты?
В плане производительности срезы намного превосходят карты, но при этом работать с ними сложнее, судя по результатам теста “Спасти рядового Райана”. Так что высокая производительность не всегда оказывается решающим фактором.
Я предпочитаю карты, поскольку они обеспечивают простой доступ к сохраненным значениям. Как это часто бывает в программировании — все зависит от конкретного случая.
Влияет ли размер на скорость срезов и карт?
Судя по результатам теста — влияет. Если нужный номер индекса известен, то, конечно, размер не важен. Но если вы не знаете, под каким индексом хранится значение, то размер играет важную роль.
Имеет ли значение тип ключа в картах?
Да. Работа с целым числом в 2.23 раза быстрее, чем с интерфейсом.
Ответы на все вопросы получены, и я надеюсь, что вы узнали что-то для себя полезное о бенчмарках. С полным вариантом кода можно ознакомиться здесь .
Не забудьте выйти в мир и протестировать его производительность.
Читайте также:
Перевод статьи Percy Bolmér : We Measure the Power of Cars, Computers, and Cellphones. But What About Code?