В этой статье я поделюсь простым приемом формирования исторических признаков на основании последовательных сведений.
Рассмотрим использованные в прошлой статье данные о заработках людей по месяцам:
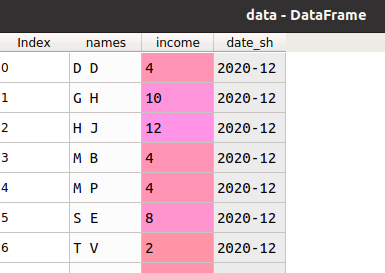
Предположим, вы хотите предсказать доход человека в последующий месяц на основании предыдущих. Тогда данные следует перегруппировать таким образом, чтобы в строках находились сведения как о текущем, так и предыдущих месяцах.
Одним из простых путем добиться этого является объединение таблицы по месяцу и имени человека с ее же копией, сдвинутой на заданное количество месяцев вперед (в частности, для предыдущего - на один).
Это можно реализовать при помощи указанной ниже функции get_shift_data , принимающей в качестве параметра датафрейм, состоящий из колонки данных (заработок) и столбцов, по которым происходит объединение (ФИО человека и дата в нашем случае), наименований столбцов даты и данных, а также числа периодов, на которые целевой признак отстоит от текущего:

Рассмотрим ее применение на наших данных:
Функцию get_shift_data можно использовать для написания более продвинутой версии - get_shift_data_tilln , возвращающей все признаки раньше заданного (она принимает те же параметры):
Рассмотрим ее работу на примере:
Или для другой длины окна, чтобы сохранить больше данных:
Напоминаю, что я использую канал в teletype.in, откуда вы можете скопировать код статьи. Подписывайтесь!