
Анализ главных компонент – это метод понижения размерности Датасета (Dataset), который преобразует больший набор переменных в меньший с минимальными потерями информативности.
Уменьшение количества переменных в наборе данных происходит в ущерб точности, но хитрость здесь заключается в том, чтобы потерять немного в точности, но обрести простоту. Поскольку меньшие наборы данных легче исследовать и визуализировать, анализ данных становится намного проще и быстрее для Алгоритмов (Algorithm) Машинного обучения (ML) .
Идея PCA проста: уменьшить количество переменных в наборе данных, сохранив при этом как можно больше информации.
Шаг первый. Стандартизация
Мы осуществляем Стандартизацию (Standartization) исходных переменных, чтобы каждая из них вносила равный вклад в анализ. Почему так важно выполнить стандартизацию до PCA? Метод очень чувствителен к Дисперсиям (Variance) исходных Признаков (Feature). Если есть больши́е различия между диапазонами исходных переменных, те переменные с бо́льшими диапазонами будут преобладать над остальными (например, переменная, которая находится в диапазоне от 0 до 100, будет преобладать над переменной, которая находится в диапазоне от 0 до 1), что приведет к необъективным результатам. Преобразование данных в сопоставимые масштабы может предотвратить эту ситуацию.
Математически это можно сделать путем вычитания Среднего значения (Mean) из каждого значения и деления полученной разности на Стандартное отклонение (Standard Deviation). После стандартизации все переменные будут преобразованы в исходные значения.
Шаг второй. Матрица ковариации
Цель этого шага – понять, как переменные отличаются от среднего по отношению друг к другу, или, другими словами, увидеть, есть ли между ними какая-либо связь. Порой переменные сильно коррелированы и содержат избыточную информацию, и чтобы идентифицировать эти взаимосвязи, мы вычисляем Ковариационную матрицу (Covariance Matrix).
Ковариационная матрица представляет собой симметричную матрицу размера p × p (где p – количество измерений), где в качестве ячеек пребывают коэффициенты ковариации, связанные со всеми возможными парами исходных переменных. Например, для трехмерного набора данных с 3 переменными x, y и z ковариационная матрица представляет собой следующее:

Поскольку ковариация переменной с самой собой – это ее дисперсия, на главной диагонали (от верхней левой ячейки к нижней правой), у нас фактически есть дисперсии каждой исходной переменной. А поскольку ковариация коммутативна (в ячейке XY значение равно YX), элементы матрицы симметричны относительно главной диагонали.
Что коэффициенты ковариации говорят нам о корреляциях между переменными? На самом деле, имеет значение знак ковариации. Если коэффициент – это:
- положительное число, то две переменные прямо пропорциональны, то есть второй увеличивается или уменьшается вместе с первым.
- отрицательное число, то переменные обратно пропорциональны, то есть второй увеличивается, когда первый уменьшается, и наоборот.
Теперь, когда мы знаем, что ковариационная матрица – это не более чем таблица, которая отображает корреляции между всеми возможными парами переменных, давайте перейдем к следующему шагу.
Шаг третий. Вычисление собственных векторов
Собственные векторы (Eigenvector) и Собственные значения (Eigenvalues) – это понятия из области Линейной алгебры (Linear Algebra), которые нам нужно экстраполировать из ковариационной матрицы, чтобы определить так называемые главные компоненты данных. Давайте сначала поймем, что мы подразумеваем под этим термином.
Главная компонента – это новая переменная, смесь исходных. Эти комбинации выполняются таким образом, что новые переменные (то есть главные компоненты) не коррелированы, и большая часть информации в исходных переменных помещается в первых компонентах. Итак, идея состоит в том, что 10-мерный датасет дает нам 10 главных компонент, но PCA пытается поместить максимум возможной информации в первый, затем максимум оставшейся информации во второй и так далее, пока не появится что-то вроде того, что показано на графике ниже:
Такая организация информации в главных компонентах позволит нам уменьшить размерность без потери большого количества информации за счет отбрасывания компонент с низкой информативностью.
Здесь важно понимать, что главные компоненты менее интерпретируемы и не имеют никакого реального значения, поскольку они построены как линейные комбинации исходных переменных.
С геометрической точки зрения, главные компоненты представляют собой Векторы (Vector) данных, которые объясняют максимальное количество отклонений. Главные компоненты – новые оси, которые обеспечивают лучший угол для оценки данных, чтобы различия между наблюдениями были лучше видны.
Поскольку существует столько главных компонент, сколько переменных в наборе, главные компоненты строятся таким образом, что первый из них учитывает наибольшую возможную дисперсию в наборе данных. Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так:
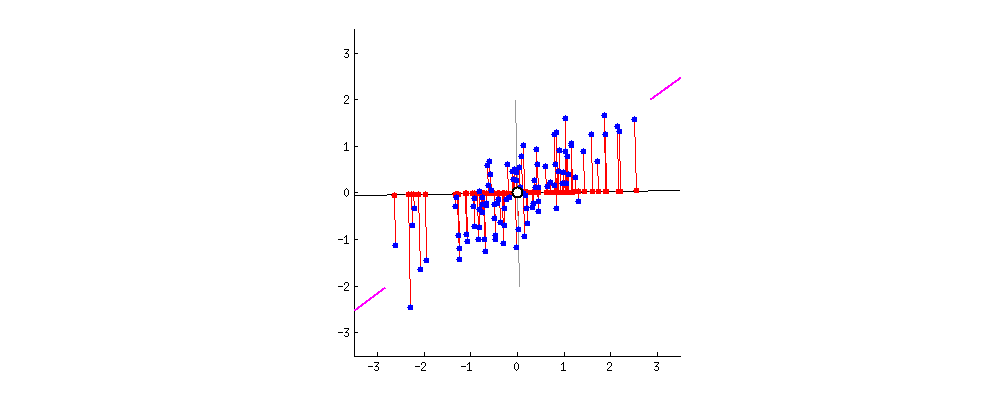
Можем ли мы проецировать первый главный компонент? Да, это линия, которая соответствует фиолетовым отметкам, потому что она проходит через начало координат, и проекции точек на компонент наиболее короткие. Говоря математически, это линия, которая максимизирует дисперсию (среднее квадратов расстояний от проецируемых красных точек до начала координат).
Второй главный компонент рассчитывается таким же образом, при условии, что он не коррелирован (т.е. перпендикулярен) первому главному компоненту и учитывает следующую по величине дисперсию. Это продолжается до тех пор, пока не будет вычислено p главных компонент, равное исходному количеству переменных.
Теперь, когда мы поняли, что подразумевается под главными компонентами, давайте вернемся к собственным векторам и собственным значениям. Прежде всего, нам нужно знать, что они всегда "ходят парами", то есть каждый собственный вектор имеет собственное значение. И их количество равно количеству измерений данных. Например, для 3-мерного набора данных есть 3 переменных, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.
За всей магией, описанной выше, стоят собственные векторы и собственные значения, потому что собственные векторы матрицы ковариации на самом деле являются направлениями осей, где наблюдается наибольшая дисперсия (большая часть информации) и которые мы называем главными компонентами. А собственные значения – это просто коэффициенты, прикрепленные к собственным векторам, которые дают величину дисперсии, переносимую в каждом основном компоненте.
Ранжируя собственные векторы в порядке от наибольшего к наименьшему, мы получаем главные компоненты в порядке значимости.
Шаг четвертый. Вектор признака
Как мы видели на предыдущем шаге, вычисляя собственные векторы и упорядочивая их по собственным значениям в в порядке убывания, мы можем ранжировать основные компоненты в порядке значимости. На этом этапе мы выбираем, оставить ли все эти компоненты или отбросить те, которые имеют меньшее значение, и сформировать с оставшимися матрицу векторов, которую мы называем Вектором признака (Feature Vector) .
Итак, вектор признаков – это просто матрица, в столбцах которой есть собственные векторы компонент, которые мы решили оставить. Это первый шаг к уменьшению размерности, потому что, если мы решим оставить только p собственных векторов (компонент) из n, окончательный набор данных будет иметь только p измерений.
Шаг пятый. Трансформирование данных по осям главных компонент
На предыдущих шагах, помимо стандартизации, мы не вносили никаких изменений в данные, а просто выбирали основные компоненты и формировали вектор признаков, но исходной набор данных всегда остается.
На этом последнем этапе цель состоит в переориентации данных с исходных осей на оси, представленные главными компонентами (отсюда и название «Анализ главных компонент»). Это можно сделать, перемножив транспонированный исходный набор данных на транспонированный вектор признаков.
PCA и Scikit-learn
PCA можно реализовать с помощью SkLearn. Для начала импортируем необходимые библиотеки:
Мы будем использовать датасет банка, автоматизирующего выдачу кредитных продуктов своим клиентам:
Создадим список признаков, подлежащих уменьшению. Это макроэкономические показатели с невысоким уровнем важности, которые почти не попали в список выше. Выберем сокращаемые и Целевую переменные (Target Variable):
Выберем cамые важные признаки с помощью функции SelectKBest, которая использует критерий Хи-квадрат (Chi Square):
Создадим объект dfscores, куда отправим, соответственно, очки важности всех признаков датасета:
Создадим для коэффициентов отдельный объект, соединив названия столбцов и очки, и отобразим пять признаков, набравших наибольшее количество очков:
Неожиданно, но самыми важными признаками оказались количество сотрудников в компании и порядковый номер рекламной кампании, в которой участвует клиент:
Создадим список признаков, подлежащих понижению. Это макроэкономические показатели с невысоким уровнем важности, которые почти не попали в список выше:
Выполним стандартизацию объекта X. StandardScaler() на месте заменяет данные на их стандартизированную версию, и мы получаем признаки, где все значения как бы центрированы относительно нуля. Такое преобразование необходимо, чтобы правильно объединить признаки между собой.
Результат выглядит следующим образом:
Мы хотим получить один главный компонент. Передадим функции обучающие данные:
Мы получили вот такой главный компонент:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь .
Автор оригинальной статьи: Zakaria Jaadi
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте наши курсы по Машинному обучению на Udemy.