Есть в самом начале курса теории вероятностей некое интересное утверждение, под названием "теорема Байеса" или "формула Байеса". В своё время она меня несколько озадачила, но тогда времени не было особо вникать, потому что требовалось управлять мегаполисом, развивать цивилизацию, уничтожать демонов на Марсе, отражать нашествие инопланетян, да мало ли какие ещё неотложные дела имеются у студента второго курса... Поэтому я воспринял формулу как неизбежное зло, списал задачки у одногруппников, сдал и забыл. А теперь вот время нашлось.
Формула Байеса даёт выражение для условных вероятностей одного из событий Eₖ полной группы E₁ , ... , Eₙ при условии, что произошло событие A:
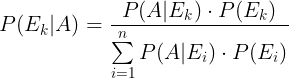
Эта формула называется также формулой для вероятности гипотезы после испытания. Предположим, что событие A может происходить при гипотезе Hᵢ, заключающейся в том, что произошло событие Eᵢ, с вероятностью P(A | Eᵢ), а P(Eᵢ) - вероятность гипотезы Hᵢ. Формула Байеса позволяет вычислить условную вероятность гипотезы Hₖ при условии, что произошло событие A, через вероятности гипотез и вероятности события A при различных гипотезах.
(Справочник по теории вероятностей и математической статистике, М., Наука, 1985 )
Ну, всё понятно, правда? Тем, кому всё понятно, можно дальше не читать. Для меня же это - хитрая шифровка. И типичные задачи, которые требуется решить с помощью этой шифровки, ей под стать:
На заводе работают три конвейера, выпускающие однотипную продукцию. Первый конвейер обеспечивает 25% выпуска, второй - 30% выпуска, третий - 45% выпуска. Среди продукции, выпускаемой первым конвейером, обнаруживается 5% брака, второй конвейер допускает брак в 7% случаев, продукция, выпускаемая третьим конвейером, содержит 11% брака. Наудачу взятый образец продукции оказался бракованным. Найти вероятность, что он выпущен первым конвейером.
Или вот, например:
Детектор лжи устанавливает виновность подсудимого в 90% случаях, если обвиняемый виновен, и в 1% случаях, если обвиняемый невиновен. Подозреваемый был выбран из группы, в которой 10 % участников когда-либо совершали преступление. Детектор лжи подтвердил его виновность. Какова вероятность того, что подозреваемый невиновен?
Кошмар какой-то. Что ж, придётся разбираться.
Вспомним, как вообще вводится понятие вероятности. По канону в рассматриваемом эксперименте выделяется так называемая полная группа элементарных событий, то есть, совокупность всех возможных взаимоисключающих исходов. Например, полной группой элементарных событий при броске игрального кубика будет такой набор:
{ ⚀, ⚁, ⚂, ⚃, ⚄, ⚅ }
Остальные события, которые могут нас заинтересовать, получаются из этой полной группы вытаскиванием подходящих элементов. Скажем, событие "на кубике выпало не больше двух" - это объединение элементарных событий ⚀ и ⚁. Если, как в случае с кубиком, все элементарные события равноправны, то классическое определение задаёт вероятность события как отношение числа благоприятных исходов к общему числу возможных исходов:
P("выпало не больше двух") = |{⚀, ⚁}| / |{⚀, ⚁, ⚂, ⚃, ⚄, ⚅}| = 2 / 6 = 1/3
Если же элементарные события неравноправны, то начинаются пляски с бубном. А именно, к понятию "вероятность" авторы учебников начинают подкрадываться со стороны "частоты". Дескать, проведём большое число (N) экспериментов, каждый раз эксперимент приведёт к тому или иному исходу - элементарному событию из полной группы. Если посчитать для каждого элементарного события, сколько раз такое чудо случилось (n), то это отношение n/N и будет давать представление о вероятности этого элементарного события.
То есть, если, например, мы рассматриваем всё тот же многострадальный кубик, у которого на сторонах нанесены теперь уже не числа, а скажем, два разных цвета: ░ и ▓, то полная группа элементарных событий при броске такого кубика окажется следующей:
{ ░, ▓ }
Но вот о равноправии придётся забыть. Очевидно, что тёмная грань будет выпадать куда реже, чем светлые. Тем не менее, даже в этом случае можно ожидать, что будет выполняться такая штука, как устойчивость частот. Имеется в виду следующее. Если много-много раз кидать раскрашенный кубик, то частота ν выпадения тёмной грани будет болтаться около 1/6, а светлой грани - в районе 5/6.
ν(▓) = n₁/N ≈ 1/6
ν(░) = n₂/N ≈ 5/6,
но при этом ν(▓) + ν(░) = n₁/N + n₂/N = N/N ≡ 1
Вот эти числа, около которых "крутятся" частоты, и условились считать вероятностями:
P(▓) = 1/6
P(░) = 5/6
Понятно, что наука не стоит на месте, современное понятие вероятности оторвалось - в хорошем смысле - от реальности и уже давно использует теорию меры, но по классике всё было именно так: вероятность - это отношение. И вот тут мы возвращаемся к формуле Байеса.
Для формулы Байеса я бы слово "отношение" заменил словом "доля" или "вклад". Так, в задаче про конвейеры доля первого конвейера - 25% от общего выпуска. То есть, если завод сделал 10000 единиц продукции, то примерно 2500 из них сошли с первого конвейера. Эта же доля, 25/100 от общего выпуска, является вероятностью того, что взятая наугад деталь окажется выпущенной первым конвейером. Эта доля, в свою очередь, делится на две доли: бракованные и качественные детали, и в брак уходит примерно 5% от 2500, или 5% от (25% от 10000). Можно начертить следующую диаграмму:
Здесь белые квадратики фактически задают элементарные события и соответствующие им вероятности. На общей диаграмме их шесть:
P("деталь с 1-го конвейера, и она брак") = 25/100 ⋅ 5/100
P("деталь с 1-го конвейера, и она норм") = 25/100 ⋅ 95/100
P("деталь с 2-го конвейера, и она брак") = 30/100 ⋅ 7/100
P("деталь с 2-го конвейера, и она норм") = 30/100 ⋅ 93/100
P("деталь с 3-го конвейера, и она брак") = 45/100 ⋅ 11/100
P("деталь с 3-го конвейера, и она норм") = 45/100 ⋅ 89/100
И в терминах долей эта задачу можно переформулировать так: какова доля первого конвейера в общем браке?
С этого момента вся остальная часть диаграммы, не относящаяся непосредственно к браку, перестаёт нас волновать. Всё, что нам осталось проанализировать, это вот такая картинка:
А уже вычислить, какова доля цветного квадратика среди всех трёх квадратиков, легко. Достаточно поделить 25/100 ⋅ 5/100 на всю сумму и получить ответ:
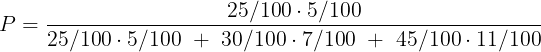
В этом и заключается суть формулы Байеса: если уж мы опустились на самое дно, то можно пренебречь полной картиной и рассматривать только те стрелочки, которые непосредственно втыкаются в то событие, в котором мы очутились. Возвращаясь к академическому языку, мы оказались в событии A = {"деталь брак"}, являющемся объединением трёх элементарных событий:
A = {"деталь брак"} =
{
"деталь с 1-го конвейера, и она брак",
"деталь с 2-го конвейера, и она брак",
"деталь с 3-го конвейера, и она брак"
}
и нам нужно было посчитать, какова в этом доля гипотезы H₁ = {"деталь с 1-го конвейера"}, которая также является объединением элементарных событий:
H₁ = {"деталь с 1-го конвейера"} =
{
"деталь с 1-го конвейера, и она брак",
"деталь с 1-го конвейера, и она норм"
}
То есть, найти долю A∩H₁ = {"деталь с 1-го конвейера, и она брак"} среди всех составляющих A событий.
Та же самая ситуация и с полиграфом. Кто-то наверху выдёргивает из толпы человека, который с вероятностью 10% может оказаться бандитом, суёт его в полиграф, а мы сидим внизу, в одном из исходов ("полиграф промолчал" или "полиграф сработал") и считаем вклады стрелочек, по которым к нам падают грешные души:
Ситуация в точности та же самая. Квадратики задают полную группу элементарных событий и их вероятности:
P("человек виновен, полиграф говорит виновен") = 10/100 ⋅ 90/100
P("человек виновен, полиграф говорит невиновен") = 10/100 ⋅ 10/100
P("человек невиновен, полиграф говорит виновен") = 90/100 ⋅ 1/100
P("человек невиновен, полиграф говорит невиновен") = 90/100 ⋅ 99/100
Но нас интересуют только события, втыкающиеся в исход, при котором полиграф говорит "виновен". Опять высчитываем долю цветного квадратика и получаем ответ:
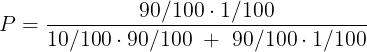
Здесь событием A = {"полиграф сказал виновен"} является объединение двух элементарных событий:
A = {"полиграф сказал виновен"} =
{
"человек виновен, полиграф говорит виновен",
"человек невиновен, полиграф говорит виновен"
},
гипотеза H₁ = {"человек невиновен"} - объединение тоже двух элементарных событий:
H₁ = {"человек невиновен"} =
{
"человек невиновен, полиграф говорит виновен",
"человек невиновен, полиграф говорит невиновен"
}
и мы опять занимаемся нахождением доли события A∩H₁ = {"человек невиновен, полиграф говорит виновен"} среди всех событий, из которых составлено А.
Вот, собственно, и всё. Формула Байеса оказалась не такой страшной, как виделась вначале.