Выявление и измерение причинно-следственных связей помогают бизнесу находить слабые стороны и увеличивать эффективность продаж, производства и рекламы. Однако большая часть отечественных компаний игнорируют этот вид тестирования, из-за чего происходят серьезные ошибки и, как следствие, рост издержек.
Статистика содержит множество прототипов анализа, но слишком часто эти структуры разрознены в рамках определенных дисциплин. Поэтому обнаружить нужный метод и применить его кажется чем-то невыполнимым. На самом же деле нужно освоить несколько ключевых методов проектирования для измерения причинно-следственных связей.
Для этого LabelMe создал несколько междисциплинарных шаблонов, подкрепленных иллюстрациями, кратким обзором метода и его применением в гипотетических моделях различных бизнес-задач. Это станет своего рода памяткой, которая поможет вам в нужный момент. Но начнем с небольшого разъяснения о целесообразности применения непрерывной интеграции (Continuous Integration, Cl) в коммерческих организациях.
Continuous Integration в бизнесе
Любая компания хочет знать, какое причинное влияние оказывает их стратегия на поведение клиентов. Взять ту же рекламу: какой она должна быть, чтобы привлечь или, наоборот, не оттолкнуть потенциального покупателя. Естественно, нельзя мести всех под одну гребенку. Нужно знать переменные и паттерны, сегментировать аудиторию и добиваться точечного воздействия для каждой отдельной группы.
Это очень тонкий канат, по которому сложно балансировать. Допустим у вас есть товар, в котором заинтересован клиент. Стреляя наугад, вы можете дать ему скидку или промокод, который с одной стороны подогреет интерес, а с другой - уменьшит вашу прибыль. Соответственно, чем крупнее компания, тем больше денег она потеряет.
Также стоит помнить о некоторых нюансах:
- Некоторые ситуации вы не можете протестировать из-за этических, логистических или репутационных рисков.
- Тестирование может быть дорогостоящим.
- Непредсказуемость экспериментов (даже проваленные тесты нужно использовать для анализа переменных).
- Сбор данных может занять немало времени.
Взамен вы или ваш довольный руководитель, получите понимание того, как воздействовать на определенные группы клиентов. Мы в свою очередь покажет, как этого добиться с помощью самых разных моделей анализа данных.
Чтобы хоть как-то измерить причинно-следственный эффект, мы воспользуемся потенциальным результатом. Это позволит сравнить две модели: где меры предприняты с учетом причинно-следственной связи и без нее.
1. Стратификация
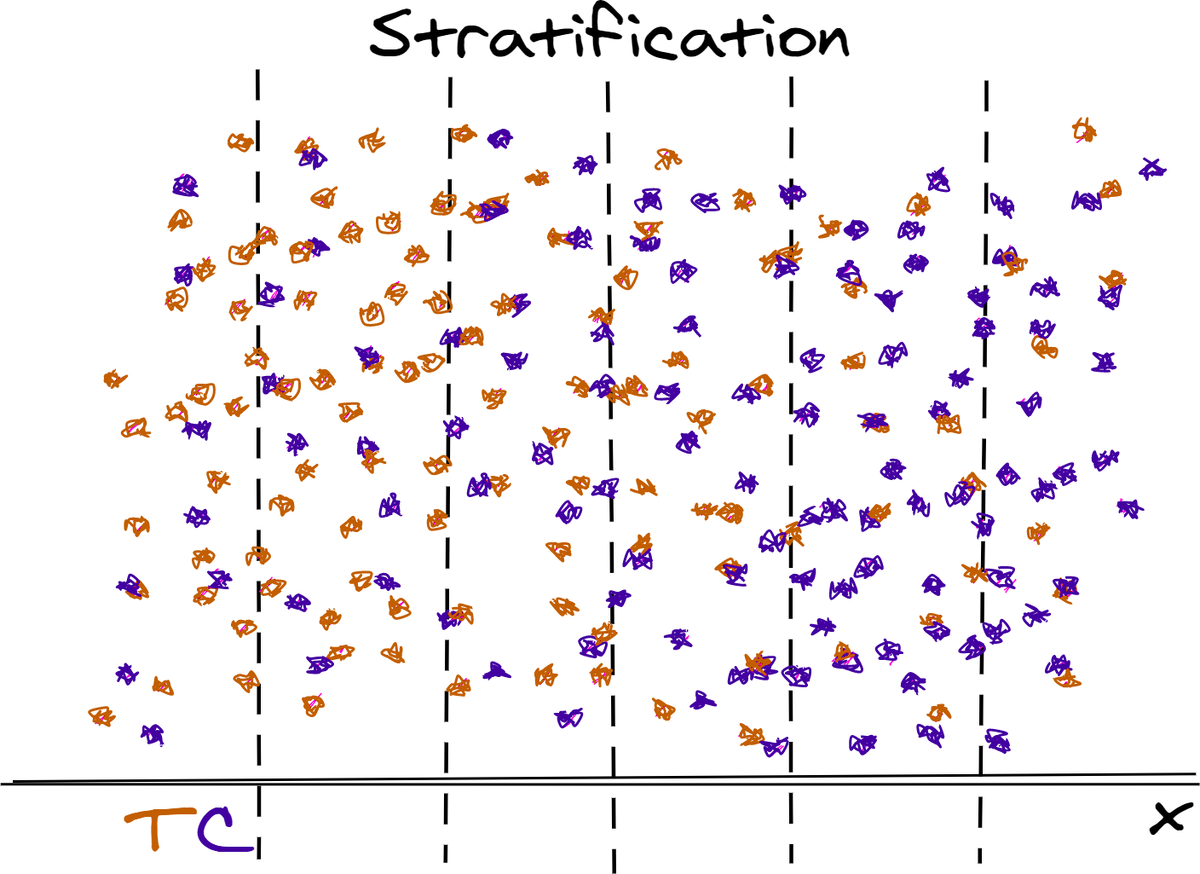
Стратификация помогает нам исправить несбалансированное взвешивание исследуемых и контрольных популяций, которые возникают из-за механизма неслучайного распределения.
Если у вас есть схожие обработанных и необработанных группы клиентов с различным распределением по небольшому числу соответствующих измерений, то использование стратификации поможет сделать их средние эффекты более сопоставимыми.
Пример
Предположим, мы попытались провести A / B-тестирование «мгновенной оплаты в один клик» на нашем сайте в период «Черной пятницы» и хотим измерить влияние на общую сумму покупки.
Из-за сбоя в коде вероятность того, что пользователи попадут в исследуемую группу (то есть увидеть кнопку), составляет 50%, а у мобильных пользователей - только 30%.
Получается, что веб-пользователей значительно больше. Следовательно простое сравнение результатов невозможно, так как приведет к смещению наших показателей. Нам будет казаться, что эффект действия кнопки в браузере значительно выше, что на самом деле не так.
Действия
- Разделите пользователей по соответствующим подгруппам на основе значений характеристик каждого наблюдения.
- Рассчитайте средний эффект кампании (использования кнопки быстрой покупки) в каждой подгруппе.
- Возьмите средние значения эффектов подгруппы, взвешенное для исследуемой группы (например, распределение мер, распределение контроля, распределение групп).
Ключевые предположения
Все общие показатели и результаты можно зафиксировать с помощью ковариат.
Все наблюдения имели положительный эффект. С эвристической точки зрения это означает, что нет никаких крупных областей, где есть только синие контрольные наблюдения и нет красных наблюдений.
Лишь небольшое количество переменных требует корректировки (потому что они влияют как на вероятность принятие мер, так и на результат). В противном случае нас преследует проклятие размерности.
Пример приложения
Мы могли бы провести еще одно A/B-тестирование, но у нас был только один набор данных с "Черной пятницы". Нам нужно решить, включать ли эту кнопку в следующем году, исходя из имеющихся результатов, Мы можем рассчитать отдельно эффективность обработки в веб версии и в приложении, а затем усреднить эти результаты на основе общего распределения каналов по всем заказам.
Технически, с современным веб-дизайном мы могли бы принимать отдельные решения для мобильных и веб-пользователей. Поэтому мы могли бы не заботиться об общем эффекте кампании.
Смежные методы
Измерение оценки склонности (рассматривается далее) можно использовать как более продвинутую форму стратификации. Оба метода имеют общую цель - сделать распределение групп принятия мер и контроля более похожим.
Инструменты
Этот метод прост в вычислительном отношении, поэтому он может быть реализован с помощью SQL или любого базового пакета обработки данных. Например, dplyr или pandas при условии, что библиотека может выполнять агрегирование по группам.
2. Псевдорандомизация (Propensity Score Weighting)
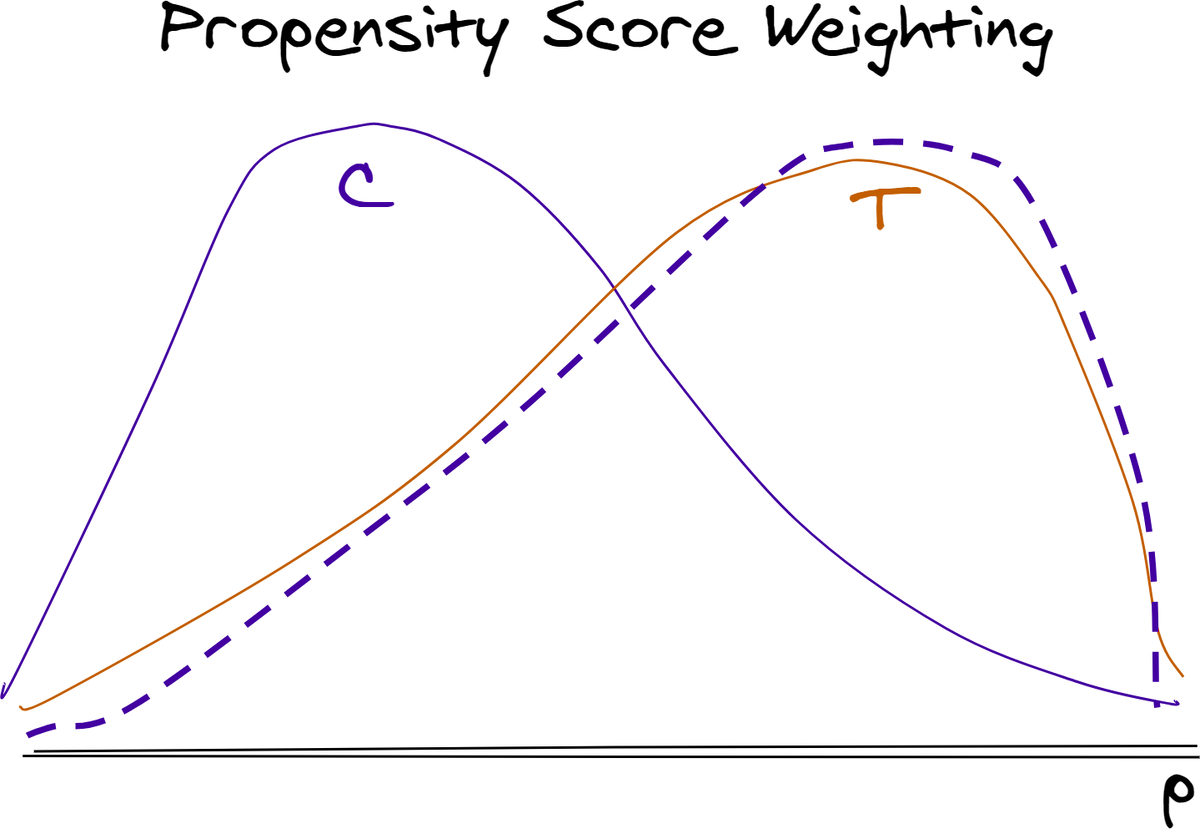
Так же как и стратификация, псевдорандомизация помогает нам скорректировать системные различия между исследуемой и контрольной популяциями, которые проистекают из механизмов неслучайного распределения.
Этот подход позволяет нам контролировать многие наблюдаемые характеристики, влияющие на назначение, сводя всю соответствующую информацию к единому баллу. Именно его мы должны учитывать при анализе и оценке.
Пример
Мы сделали рассылку всем нашим клиентам, чьи номера есть в базе и хотим узнать причинно-следственное влияние на вероятность совершения покупки в следующем месяце.
Мы ненамеренно оставили контрольную группу необработанной. Зато можем наблюдать необработанную реакцию клиентов, которые не получали рассылки.
Номер телефона может быть необязательным полем в пользовательском интерфейсе при совершении покупки. Из-за этого возможна хаотичность при анализе популяций. Но нам известно, что те , кто не оставляют номера, в среднем покупают реже. При этом полный спектр низкочастотных и высокочастотных покупателей существует в обеих группах.
Таким образом, если мы просто сравним обработанные и необработанные группы, то продвижение будет выглядеть более эффективным, чем оно было на самом деле. Дело в том, что оно направляется обычно более активным клиентам.
Действия
- Смоделировать вероятность получения обработки (баллы склонности) на основе наблюдаемых характеристик, имеющих отношение обработке и результатам.
- В данных наблюдений распределение баллов предрасположенности в экспериментальной группе обычно смещается вправо (тенденция повышению показана сплошным красным цветом), а в контрольной группе-влево (тенденция к снижению показана сплошным синим цветом).
- Использовать прогнозируемые вероятности (баллы склонности) для взвешивания необработанных наблюдений, чтобы они соответствовали тому же распределению вероятности, что и контрольная группа (показаны пунктирным синим цветом).
- Весовые коэффициенты могут быть построены различными способами в зависимости от уровня интереса (средний эффект обработанных данных, средний эффект популяции, средний эффект контрольной популяции и так далее).
- Применить весовые коэффициенты при расчете среднего результата в каждой из обработанных и контрольных групп и вычесть, чтобы найти эффект изменений.
Ключевые предположения
Все общие причины обработки и результат могут быть зафиксированы с помощью ковариат (более математически, результат и лечение зависят от ковариат независимо друг от друга).
Все наблюдения имели некоторую положительную вероятность обработки. С эвристической точки зрения на изображении выше нет областей на линии, где кривые обработки или контрольной частоты полностью спускаются к нулю.
Пример приложение
Смоделируйте склонность к обработке (например, при условии наличия номера) на основе демографических данных или истории покупательского поведения.
Выведите весовые коэффициенты для расчета среднего эффекта обработки. Обработанные наблюдения остаются невзвешенными. Для необработанных наблюдений вес представляет собой отношение балла склонности к единице минус балл склонности.
Смежные методы
Стратификация концептуально аналогична взвешиванию по шкале склонности, поскольку она неявно вычисляет эффект обработки для повторно взвешенной выборки. Здесь изменение веса происходит после вычисления локализованных эффектов, а не до.
При сопоставлении иногда также используются оценки склонности, но есть аргументы против этого подхода.
Инструменты
Метод можно реализовать с помощью простой функции stats :: glm () или с пакетом WeightIt на R.
3. Разрыв регрессии (Regression Discontinuity)
Бизнес часто используют стратегии, предусматривающие резкие ограничения. Например, сегментация клиентов по возрасту или доходу. При этом люди, находящиеся по обе стороны от этого ограничения, получают разные "сообщения". В таких случаях у нас нет соответствующих данных для повторного изучения. Однако мы можем применить метод разрыва регрессии, чтобы понять местный эффект воздействия в точке прерывания.
Если у компании есть непересекающиеся обработанные и необработанные клиенты, разделенные резким отсечением, используйте произвольное изменение назначения обработки для тех, кто находится прямо над или под отсечением, чтобы измерить локальный причинный эффект.
Пример
Клиенты, которые не совершили покупки в течение 90 дней, получают купон «Скидка 10 % на следующую покупку».
Мы можем использовать резкое отсечение «дней с момента последней покупки», чтобы измерить влияние купона на расходы в следующем году.
С другой стороны, нельзя приравнивать клиентов, которые не покупали в течение 10 дней, и тех, кто не совершал покупки в течение 150 дней.
Действия
Группа людей получает или не получает определенных предложений на основании произвольного исключения.
Моделируем взаимосвязь между «текущей» переменной (переменной, используемой в отсечения) и результатом по обе стороны от отсечения. Затем эффект мер в точке отсечения может быть определен разницей в моделируемом исходе при этом значении текущей переменной.
Обратите внимание, что мы можем измерить только эффект мер на пороге отсечения, а не глобальный средний эффект, как мы это делали со стратификацией и взвешиванием по шкале склонности.
Ключевые предположения
Принцип назначения неизвестно наблюдаемым лицам, поэтому с ним нельзя играть.
Интересующий результат можно смоделировать как непрерывную функцию по отношению к переменной решения.
Мы можем подогнать достаточно хорошо заданную и простую модель между результатом интереса и переменной принятия решения. Поскольку RDD обязательно требует, чтобы мы использовали оценки из самых «хвостов» нашей модели, чрезмерно сложные модели (например, многочлены высокой степени) могут привести к странным выводам.
Пример приложение
Мы можем смоделировать связь между “днями с момента последней траты” и “тратами в следующем году” и оценить разницу в смоделированных значениях при значении 90 для “дней с момента последней траты”.
Контрпример - реклама с тезисом «Бесплатная доставка и частичный возврат средств» и попытка измерить влияние предложения бесплатной доставки на лояльность будущих клиентов. Почему? Просто смоделированное условие известно людям с самого начала и его можно легко использовать.
Например, возможно, менее лояльное и более скептическое отношение к товарам компании. Клиент может специально совершить покупку, чтобы воспользоваться особыми условиями.
Смежные методы
Разрыв нечеткой регрессии позволяет точкам отсечения быть вероятными, а не абсолютными.
Методы инструментальных переменных и двухэтапный метод наименьших квадратов можно рассматривать как более широкую группу методов, в которой разрыв регрессии является простым примером. В широком смысле эти методы решают проблему смешения между принятием мер и результатом с помощью моделирования взаимосвязи.
Инструменты
В данном случае применимы пакет AER (для метода инструментальных переменных) или rdd (разрыв регрессии) на R.
4. Разность разностей (Difference in Differences)
До этого момента мы рассматривали методы, которые помогают сгруппировать схожих клиентов по группам до принятие каких-либо мер со стороны компании. Один из способов оценить эти методы - проверить совпадают ли значения переменной интереса до воздействия на клиента. Однако данные, которыми мы располагаем, делают это очень ограничено.
Вместо того, чтобы искать сходство на абсолютном уровне, метод разности разностей помогает нам более гибко согласовывать схожесть траекторий во времени. Вместо сравнения мер и контрольных групп в пределах одной и той же популяции, мы можем сравнить относительные изменения между воздействием и контролем популяций в динамике.
Пример
Представим, что нам нужно оценить влияние перестановки в магазине на посещаемость.
Эти изменения затрагивают всех потенциальных клиентов, поэтому последующее воздействие не применено на индивидуальном уровне. Теоретически мы бы могли прибегнуть к рандомизации для отдельных магазинов, но у нас нет средств и мотивации к случайному ремоделированию, пока не будет доказательств положительного влияния на рост продаж.
Действия
Нам нужно, чтобы одна группа получила обработку и последующие меры, а другой нет. Мы отталкиваемся от предположения, что без дополнительных действий обе популяции имели бы схожие тенденции в результатах.
Мы можем оценить эффект воздействия, взяв разницу между популяциями до и после воздействия.
По факту это экстраполяция контрфактов для стимулированной популяции после обработки, если она его не получала (пунктирная линия на изображении выше).
Технически это реализовано как регрессионная модель с фиксированными эффектами.
Ключевые предположения
Решение об обработки группы не зависит от исхода.
Если бы не вмешательство, то две сравниваемые группы имели бы параллельные тенденции в результатах. Обратите внимание, что группам разрешено иметь разные уровни, но со временем они должны иметь схожие тенденции.
Нет какого-либо побочного эффекта, который бы оказал влияние на контрольную группу.
Пример приложение
Мы можем оценить влияние обновления магазина по уровню посещаемости, сравнив трафик магазина до и после реконструкции.
С другой стороны мы можем измерить, как повлияла перестановка на продажи товаров определенного бренда. В этом случае возникает риск: перестановка может повлиять на уровень продаж контрольной группы.
Смежные методы
Синтетические методы контроля можно рассматривать как расширение метода разности разностей, где контроль представляет собой среднее значение ряда различных возможных средств контроля.
Байесовские структурные методы временных рядов ослабляют предположение о «параллельных тенденциях» в методе разности разностей, моделируя взаимосвязь между временными рядами (включая трендовые и сезонные факторы).
Инструменты
Здесь нам придется прибегнуть к: пакету для разности разностей на R, Synth (для синтетических элементов управления) и CausalImpact (для байесовских структурных временных рядов).
Заключение
Все эти методы требуют обширных данных с измерениями исходных характеристик каждого изучаемого человека и твердого понимания полученного результата воздействия. Допустить ошибку, которая испортит всё, - здесь проще простого.
Например, у нас может быть база данных, в которой каждая учетная запись клиента сопоставляется с системным идентификатором campaign_id, обозначающим какую-то маркетинговую кампанию. Но, если информация о какой-то из кампаний отсутствует, то все предположения и гипотезы будут неточными. Поэтому перед началом работы с причинным проектированием убедитесь, что у вас точно есть всех необходимые данные.
Надеемся, что статья была для вас полезной. Если так, то не забудьте поставить лайк. Это помогает в развитии канала и выборе будущих тем.
Другие наши статьи:
__________________________________________________________________________________________