Эти действия помогут локализовать ошибку и понять, как ее исправить. Рекомендации достаточно просты и могут показаться очевидными для тех, кто одним грозным взглядом на код способен заставить неполадки добровольно исправляться).
Пусть в нашем распоряжении две таблицы (data и df), которые должны быть практически идентичными (только значения перемешаны), однако в коде ведут себя, будто это не так:
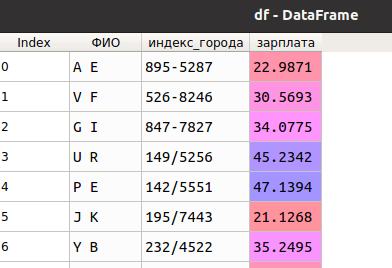
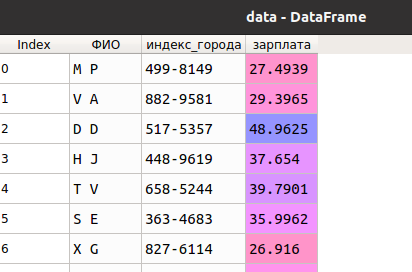
Как обычно, будем использовать Python и библиотеку Pandas .
Получение несоответствующих значений
Для этого потребуется воспользоваться методом isin объекта Series, а именно вывести столбец (в данном случае - индекс_города), значения которого присутствуют в одной таблице и отсутствуют в другой:
Также можно вывести уникальные значения среди не совпадающих, вызвав value_counts:
Кстати, если вы хотите сравнивать построчно два датафрейма вышеуказанный способ использовать напрямую не получится, так как он предназначен для сопоставления одиночных полей. В этом случае поможет трюк, превращающий значения полей строки в кортежи:
Не забываем, что аналогичные действия можно предпринимать симметрично для другой таблицы.
Попарно вывести несовпадения
Допустим, несовпадающие значения связаны по некоторому общему полю. Тогда можно получить все значения этого поля в каждой из таблиц и по ним связать проблемные записи для их попарного сравнения:
В текущем примере проблема связана с особенностями считывания файлов функцией read_excel библиотеки Pandas и в данном случае решение заключается в дополнительном преобразовании типов (об этом рассказывал ранее).