Мы с вами продолжаем практический курс по анализу данных, и это уже 4 занятие. Предыдущие занятия можно посмотреть здесь, здесь и здесь. На последнем занятии мы подготовили данные, которые сохранили в csv-файл, а также определили, что вместо 4 цен можно использовать цену закрытия. И по сложившейся традиции мы создаем новый блокнот, подключаем гугл-диск. Весь код можно увидеть здесь.
Мы начинаем с импорта библиотек:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
С тремя первыми библиотеками мы уже знакомы, а вот четвертая появилась впервые. Как вы уже догадались, библиотеки можно импортировать в любом месте блокнота, но считается признаком хорошего тона импортировать их вначале. Теперь загрузим наш файл:
df = pd.read_csv('/content/drive/MyDrive/usdrub.csv', index_col='date', parse_dates=['date'])
Напомню, что строку csv-файла вы пишите свою. В прошлом занятии мы говорили об сохранении индекса, вот теперь мы указываем при загрузке: какая колонка будет являться индексом. Так уж совпало, что эту же колонку надо распознать как дату. Нет ничего страшного в том, что первое время вы каждое свое действие будете проверять. Например, успешную загрузку файла можно проверить отобразив первые 5 строчек или вывести информацию о датафрейме. В любом случае мы видим, что в датафрейме 4 цены, хотя нужно только close. Для текущего датафрейма это не критично, но если вы будете работать с большими данными, то придется удалять лишние колонки, при этом это никак не повлияет на csv-файл. Сейчас мы будем использовать другой способ, а именно в новую переменную запишем ссылку на одну колонку:
data = df.close
Такой подход нам позволит вернутся к первоначальному датафрейму, если возникнет такая необходимость. Еще раз проверим размерность данных и дат (они должны совпадать):
print('Количество строк:', data.shape[0])
print('Количество дней:', data.index.nunique())
Последней проверкой будет вывод графика:
gr = data.plot(figsize=(24, 6))
Надеюсь, что у вас появился такой же график, как представлен ниже:
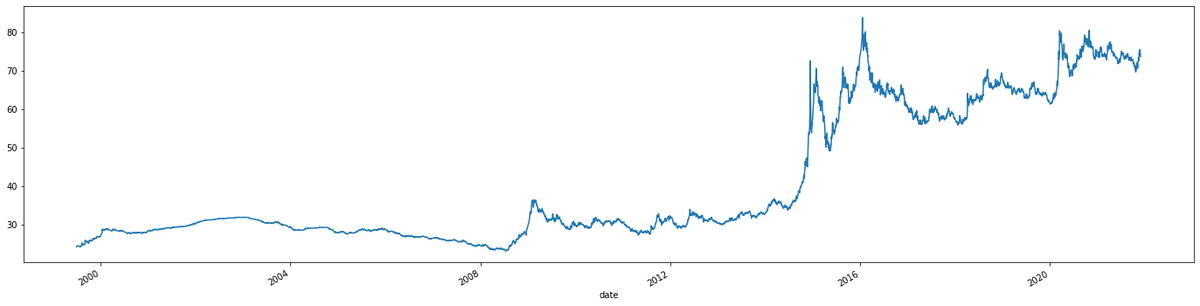
Итак, у нас есть только временной ряд цены закрытия дня, а нам нужно сделать прогноз правой (несуществующей) части графика по данным с левой части графика (имеющимся данным). Такой прогноз называется авторегрессией, которая возможна только в случае, когда существует автокорреляция, то есть временной ряд похож сам на себя с определенным смещением. Звучит непонятно, но попробуем это проиллюстрировать, для этого воспользуемся библиотекой statsmodels:
gr = sm.graphics.tsa.plot_acf(data, lags=500)
gr.set_figwidth(24)
В разделе graphics существует подраздел tsa (timeseries analysis - анализ временных рядов), в котором имеется функция plot_acf (график автокорреляционной функции). Эта функция в качестве обязательного параметра принимает временной ряд, и еще мы укажем необязательный параметр максимальное количество смещений. Второй строчкой мы задаем ширину фигуры (графика), которую в прошлый раз задавали в параметре figsize. Эту ширину вы можете изменять по своему усмотрению.

На этом графике наглядно видна корреляция вплоть до 400 дней, это означает, что первый и четырехсотый день имеют высокую похожесть. Следовательно мы можем воспользоваться авторегрессией. Если найдется хоть один специалист, знакомый с анализом временных рядов, то в меня должны уже лететь гнилые помидоры. Раз уж мы начали косячить, то построим модель с помощью функции ARIMA:
model = sm.tsa.ARIMA(data, order=(4, 2, 1)).fit()
По логике предыдущих действий вам должно быть понятно все кроме одного. Что означает параметр order=(4, 2, 1)? Быстро и понятно ответить не получится. Кроме этого, мы сейчас намеренно идем неправильным путем, с одной, единственной целью получить прогноз. Эти значения я подобрал опытным путем, минимизируя одно значение модели. Давайте, наконец получим график прогнозных значений и сравним их с фактическими с начала 2021 года:
gr = model.plot_predict('2021-01-11')
gr.set_figwidth(24)
Результат будет выглядеть так:
А что не так уж и плохо. Ну и напоследок прогноз на сегодня, потому что последние данные за пятницу 3 декабря 2021 года:
pred = model.forecast()
pred
Прогнозная цена закрытия - 73,66 с разбегом от 72,75 до 74,57. На момент написания цена инструмента составила 73,87. Тех, кто решит воспользоваться этой моделью с целью заработать денег на бирже, я должен предупредить, что модель с ошибкой. Чего еще ждать от дилетанта? Напоминаю, что данный материал не является инвестиционной рекомендацией, а если вы им воспользуетесь в этих целях, то только на свой страх и риск.