👋🏻 Привет! С вами снова Merion Academy - платформа доступного IT образования. Сегодня мы поговорим немного про протоколы RIP и EIGRP. Гоу.
Протокол RIP (Routing Information Protocol)
Протокол Routing Information Protocol (RIP) был первоначально указан в RFC1058. Протокол Routing Information Protocol опубликован в 1998 году. Протокол был обновлен в серии более поздних RFC, включая RFC2435, RIP версии 2,3 и RFC2080, RIP Next Generation для IPv6.
Рисунок 1 используется для объяснения работы RIP.
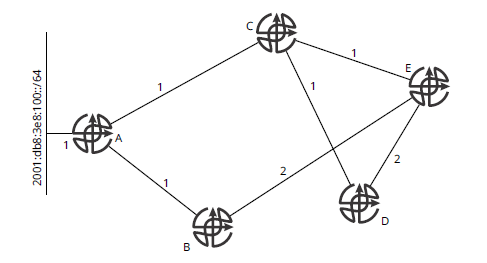
Работа RIP обманчиво проста. На рисунке 1:
- A обнаруживает 2001:db8:3e8:100::/64, поскольку он настроен на непосредственно подключенный интерфейс.
- A добавляет этот пункт назначения в свою локальную таблицу маршрутизации со стоимостью 1.
- Поскольку 100 :: / 64 установлен в локальной таблице маршрутизации, A будет анонсировать этот достижимый пункт назначения (маршрут) для B и C.
- Когда B получает этот маршрут, он добавляет стоимость входящего интерфейса, чтобы путь через A имел стоимость 2, и проверяет свою локальную таблицу на предмет любых других более дешевых маршрутов к этому месту назначения. Поскольку у B нет другого пути к 100::/64, он установит маршрут в своей таблице маршрутизации и объявит маршрут к E.
- Когда C получает этот маршрут, он добавит стоимость входящего интерфейса, чтобы путь через A имел стоимость 2, и проверит свою локальную таблицу на предмет любых более дешевых маршрутов к этому пункту назначения. Поскольку у C нет другого пути к 100 :: / 64, он установит маршрут в своей таблице маршрутизации и объявит маршрут D и E.
- Когда D получает этот маршрут, он добавляет стоимость входящего интерфейса от C, чтобы путь через C имел стоимость 3, и проверяет свою локальную таблицу на предмет любых более дешевых маршрутов к этому месту назначения. Поскольку у D нет другого пути к 100 :: / 64, он установит маршрут в свою таблицу маршрутизации и объявит маршрут к E.
- E теперь получит три копии одного и того же маршрута; один через C со стоимостью 3, один через B со стоимостью 4 и один через D со стоимостью 5. E выберет путь через C со стоимостью 2, установив этот путь на 100 :: / 64 в свою локальную таблицу маршрутизации.
- E не будет объявлять какой-либо путь к 100 :: / 64 к C, потому что он использует C как лучший путь для достижения этого конкретного пункта назначения. Таким образом, E выполнит split horizon своего объявления 100 :: / 64 в сторону C.
- В то время как E будет объявлять свой лучший путь через C как D, так и B, ни один из них не выберет путь через E, поскольку у них уже есть лучшие пути к 100 :: / 64. RIP объявляет набор пунктов назначения и определяет стоимость в один прыжок за раз через сеть. Следовательно, он считается протоколом вектора расстояния. Процесс, который RIP использует для поиска набора безцикловых путей через сеть, считается распределенной формой алгоритма Беллмана-Форда, но не совсем ясно, как процесс, который использует RIP, связан с Беллманом-Фордом.
Связь Bellman-Ford с RIP
Чтобы увидеть соединение, лучше всего представить каждый переход в сети как одну строку в таблице топологии. Это отображено на рисунке 2.
Раздел «Пути одноадресной передачи без петель», описывает работу Bellman-Ford с таблицей топологии, организованной как набор столбцов и строк. Используя номера строк, показанные на рисунке 2, вы можете построить аналогичную таблицу топологии для этой сети, как показано в таблице 1.
Предположим, что каждая строка таблицы проходит через алгоритм Беллмана-Форда другим узлом. Например, A вычисляет Беллмана-Форда по первой строке и передает результат B. Аналогичным образом, B вычисляет Bellman-Ford по соответствующим строкам и передает результат C. Беллман-Форд по-прежнему будет алгоритмом, используемым для вычисления набор без петель в сети. Он просто будет распределен по узлам в сети. Фактически, так работает RIP. Учтите следующее:
- A вычисляет первую строку в таблице, устанавливая предшественника для 100::/64 в A и стоимость в 1. A передает этот результат B для второго раунда обработки.
- B обрабатывает вторую строку в таблице, устанавливая для предшественника 100 :: / 64 значение B, а стоимость - 2. B передает этот результат C для третьего раунда обработки.
- C обрабатывает вторую строку в таблице, устанавливая для предшественника 100 :: / 64 значение C, а стоимость - 2. C передает этот результат в D. Распределенную обработку Беллмана-Форда труднее увидеть в более сложных топологиях, потому что по сети передается более одной «таблицы результатов». Однако эти «таблицы результатов» в конечном итоге объединятся на исходном узле. Рисунок 3 иллюстрирует это.
На рисунке 3 A вычислит предварительную таблицу результатов в качестве первого «раунда» алгоритма Беллмана-Форда, передав результат как B, так и E. B вычислит предварительный результат на основе локальной информации, передав его в C, а затем из C в D. Таким же образом E вычислит предварительную таблицу результатов на основе локальной информации, передав ее в F, а затем F в D. В D два предварительных результата объединяются в окончательную таблицу с точки зрения D. Конечно, предварительная таблица считается окончательной для устройства на каждом шаге. С точки зрения E, таблица, которую он вычисляет на основе локально доступной информации и объявления от A, является финальной таблицей путей без петель для достижения 100::/64.
Весь распределенный процесс имеет тот же эффект, что и хождение по каждой строке в таблице топологии столько же раз, сколько записей в самой таблице топологии, медленно сортируя поля предшественника и стоимости для каждой записи на основе вновь установленных предшественников в предыдущем раунде вычислений.
Реакция на изменения топологии
Как RIP удаляет информацию о доступности из сети в случае отказа узла или канала? Рисунок 4 используется для объяснение этого случая.
В зависимости от версии и конфигурации RIP, работающего в этой сети, существует две возможные реакции на потерю канала [A, B]. Первая возможная реакция - просто дать тайм-аут информации о 100::/ 64. Предполагая, что недействительный таймер (форма таймера удержания) для любого заданного маршрута составляет 180 секунд (обычная настройка в реализациях RIP):
- B немедленно заметит сбой связи, поскольку он подключен напрямую, и удалит 100 :: / 64 из своей локальной таблицы маршрутизации.
- B прекратит объявлять достижимость 100 :: / 64 в направлении C.
- C удалит доступность к этому месту назначения из своей локальной таблицы маршрутизации и прекратит объявлять достижимость от 100 :: / 64 до D через 180 секунд после того, как B перестанет объявлять достижимость до 100 :: / 64.
- D удалит доступность к этому месту назначения из своей локальной таблицы маршрутизации через 180 секунд после того, как C прекратит объявлять достижимость до 100 :: / 64.
На этом этапе сеть сконцентрировалась на новой информации о топологии. Очевидно, что это довольно медленный процесс, так как каждый переход должен ждать, пока каждый маршрутизатор, ближайший к месту назначения, отсчитает время, прежде чем обнаружит потерю соединения.
Чтобы ускорить этот процесс, большинство реализаций RIP также включают инициированные обновления. Если инициированные обновления реализованы и развернуты в этой сети, когда канал [A, B] выйдет из строя (или будет удален из службы), B удалит доступность 100 :: / 64 из своей локальной таблицы и отправит инициированное обновление в C, информацию C о неудавшейся достижимости к месту назначения. Это инициируемое обновление обычно принимает форму объявления с бесконечной метрикой, или, скорее, того, что известно как ядовитый реверс. Инициируемые обновления часто выполняются с заданной скоростью, поэтому колеблющееся соединение не приведет к тому, что сами инициированные обновления не будут перегружать канал или соседний маршрутизатор.
Два других таймера указаны в RIP для использования во время схождения: flush timer и hold-down timer. По истечении времени ожидания маршрута (как описано выше) он не удаляется сразу из локальной таблицы маршрутизации. Вместо этого устанавливается другой таймер, который определяет, когда маршрут будет удален из локальной таблицы. Это flush timer. Кроме того, существует отдельный период времени, в течение которого любой маршрут с метрикой хуже, чем ранее известная, не будет приниматься. Это hold-down timer. Подведение итогов- RIP
RIP несет информацию о локально достижимых пунктах назначения соседям, а также стоимость для каждого пункта назначения. Следовательно, это протокол вектора расстояния. Достижимые пункты назначения изучаются через локальную информацию на каждом устройстве и передаются по сети протоколом независимо от потока трафика; следовательно, RIP-это проактивная плоскость управления.
RIP не формирует смежности для надежной передачи данных по сети. Скорее, RIP полагается на периодически передаваемые обновления, чтобы гарантировать, что информация не устарела или не была случайно сброшена. Количество времени, в течение которого хранится любая часть информации, основано на таймере удержания (hold-down timer), а частота передач основана на таймере обновления (lush timer). Таймер удержания обычно устанавливается в три раза больше значения таймера обновления.
Поскольку RIP не имеет истинного процесса смежности, он не определяет, существует ли двусторонняя связь- следовательно, нет двусторонней проверки подключения (Two-Way Connectivity Check-TWCC). В RIP также не встроен метод проверки MTU между двумя соседями.
Enhanced Interior Gateway Routing Protocol
Enhanced Interior Gateway Routing Protocol (EIGRP) был выпущен в 1993 году для замены протокола Interior Gateway Routing Protocol (IGRP) компании Cisco. Основной причиной замены IGRP была его неспособность передавать информацию о классовой маршрутизации. В частности, IGRP не может переносить маски подсети. Вместо того, чтобы перестраивать протокол для поддержки длины префикса, инженеры Cisco (в частности, Дино Фариначчи и Боб Олбритсон) решили создать новый протокол, основанный на алгоритме диффузного обновления Гарсиа-Луны (Diffusing Update Algorithm-DUAL). Дэйв Кац перестроил транспорт, чтобы решить некоторые часто встречающиеся проблемы в середине 1990-х годов. Основываясь на этой первоначальной реализации, команда под руководством Донни Сэвиджа в 2000-х годах сильно изменила работу протокола, добавив ряд функций масштабирования и переписав ключевые части реакции EIGRP на изменения топологии. Протокол EIGRP был выпущен вместе с практически всеми этими улучшениями в RFC7868 в 2013 году.
В то время как EIGRP не часто рассматривается для активного развертывания в большинстве сетей поставщиков услуг (большинство операторов предпочитают протокол состояния канала), DUAL вводит некоторые важные концепции в обсуждение о безцикловых путях. DUAL также используется в других протоколах, таких как BABEL (указанный в RFC 6126 и используемый в простых домашних сетях).
Метрики EIGRP
Первоначально протокол EIGRP был разработан для считывания полосы пропускания, задержки, частоты ошибок и других факторов с каналов в режиме, близком к реальному времени, и передачи их в качестве метрик. Это позволит EIGRP реагировать на изменение сетевых условий в реальном времени и, следовательно, позволит сетям, на которых запущен EIGRP, более эффективно использовать доступные сетевые ресурсы. Однако в при первоначальном развертывании EIGRP, не существовало «защитных ограждений» для предотвращения петель обратной связи между, например, реакцией протокола на изменения доступной полосы пропускания и сдвигами в трафике в зависимости от доступной полосы пропускания. Если пара каналов с доступной полосой пропускания, близкой к реальному времени, была размещена параллельно друг другу, трафик переключится на канал с наиболее доступной полосой пропускания, в результате чего протокол будет реагировать, показывая большую доступную полосу пропускания на другом канале, улучшая его метрики и следовательно, трафик переместится на другую линию связи. Этот процесс переключения трафика между линиями может быть решен различными способами, но он вызывал достаточно проблем в ранних развертываниях EIGRP для того, чтобы эту возможность почти реального времени можно было удалить из кода. Вместо этого EIGRP считывает характеристики интерфейса в определенное время и объявляет эти показатели для интерфейса независимо от сетевых условий.
EIGRP несет пять различных атрибутов маршрута, включая полосу пропускания, задержку, нагрузку, надежность и MTU. Четыре показателя объединяются по формуле, показанной на рисунке 5.
Значения K по умолчанию в этой формуле приводят к сокращению всей формулы до (107/throughput) * delay. Замена пропускной способности (throughput) минимальной полосой пропускания (bandwidth) дает версию, с которой знакомо большинство инженеров: (107 / bandwidth) * delay.
Однако значения пропускной способности (bandwidth) и задержки (delay) масштабируются в более поздних версиях EIGRP для учета каналов с пропускной способностью более 107 кбит/с.
Примечание.В ходе этого обсуждения EIGRP предполагается, что полоса пропускания каждого канала установлена на 1000, а значения K установлены на значения по умолчанию, оставляя задержку в качестве единственного компонента, влияющего на метрику. Учитывая это, только значение задержки используется в качестве метрики в этих примерах для упрощения расчетов. Рисунок 6 используется для описания работы EIGRP.
Работа EIGRP в этой сети на первый взгляд очень проста:
- A обнаруживает 2001: db8: 3e8: 100 :: / 64, потому что он напрямую подключен (например, через настройки интерфейса).
- A добавляет к маршруту стоимость входящего интерфейса, которая здесь показана как задержка (delay) 100, и устанавливает ее в свою локальную таблицу маршрутизации.
- A объявляет 100 :: / 64 B и C через два других подключенных интерфейса.
- B получает этот маршрут, добавляет стоимость входящего интерфейса (общая задержка 200) и проверяет свою локальную таблицу на предмет любых других (или лучших) маршрутов к этому месту назначения. У B нет маршрута к 100 ::/64, поэтому он устанавливает маршрут в своей локальной таблице маршрутизации.
- B объявляет 100 :: / 64 для D.
- C получает этот маршрут, добавляет стоимость входящего интерфейса (общая задержка 200) и проверяет свою локальную таблицу на предмет любых других (или лучших) маршрутов к этому месту назначения. У C нет маршрута к 100 :: / 64, поэтому он устанавливает маршрут в своей локальной таблице маршрутизации.
- C объявляет 100 :: / 64 для D.
- D получает маршрут к 100 ::/64 от B, добавляет стоимость входящего интерфейса (общая задержка 300) и проверяет свою локальную таблицу на предмет любых других (или лучших) маршрутов к этому месту назначения. D не имеет маршрута к этому месту назначения, поэтому он устанавливает маршрут в своей локальной таблице маршрутизации.
- D получает маршрут к 100 :: / 64 от C, добавляет стоимость входящего интерфейса (общая задержка 400) и проверяет свою таблицу на предмет любых других (или лучших) маршрутов к этому месту назначения. D действительно имеет лучший маршрут к 100 :: / 64 через B, поэтому он вставляет новый маршрут в свою локальную таблицу топологии.
- D объявляет маршрут от 100 :: / 64 до E.
- E получает маршрут к 100 :: / 64 от D, добавляет стоимость входящего интерфейса (общая задержка 400) и проверяет свою локальную таблицу на предмет любых других (или лучших) маршрутов к этому месту назначения. E не имеет маршрута к этому месту назначения, поэтому он устанавливает маршрут в своей локальной таблице маршрутизации.
Все это очень похоже на работу RIP. Шаг 9, однако, требует более подробного рассмотрения. После шага 8 у D есть путь к 100 :: / 64 с общей стоимостью 300. Это допустимое расстояние до пункта назначения, а B - преемник, так как это путь с наименьшей стоимостью. На шаге 9 D получает второй путь к тому же месту назначения. В RIP или других реализациях Bellman-Ford этот второй путь либо игнорируется, либо отбрасывается. EIGRP, основанный на DUAL, однако, проверит этот второй путь, чтобы определить, свободен ли он от петель или нет. Можно ли использовать этот путь, если основной путь не работает?
Чтобы определить, является ли этот альтернативный путь свободным от петель, D должен сравнить допустимое расстояние с расстоянием, которое C сообщила как стоимость достижения 100 :: / 64 - заявленное расстояние. Эта информация доступна в объявлении, которое D получает от C (помните, что C объявляет маршрут с его стоимостью до пункта назначения. D добавляет к нему стоимость канала [B, D], чтобы найти общую стоимость через C для достижения 100: : / 64). Сообщаемое расстояние через C составляет 200, что меньше локального допустимого расстояния, равного 300. Следовательно, маршрут через C не имеет петель и помечен как возможный преемник.
Реакция на изменение топологии.
Как используются эти возможные преемники? Предположим, что канал [B, D] не работает, как показано на рисунке 7.
Когда этот канал выходит из строя, D проверяет свою таблицу локальной топологии, чтобы определить, есть ли у нее другой путь без петель к месту назначения. Поскольку путь через C отмечен как возможный преемник, у D есть альтернативный путь. В этом случае D может просто переключиться на использование пути через C для достижения 100 :: / 64. D не будет пересчитывать допустимое расстояние в этом случае, так как он не получил никакой новой информации о топологии сети.
Что, если вместо этого произойдет сбой соединения между C и A, как показано на рисунке 8?
В этом случае до сбоя у C есть два пути к 100 :: / 64: один через A с общей задержкой 200 и второй через D с общей задержкой 500. Возможное расстояние в C будет установлено на 200 , поскольку это стоимость наилучшего пути, доступного после завершения сходимости. Сообщаемое расстояние в D, 300, больше, чем возможное расстояние в C, поэтому C не будет отмечать путь через D как возможный преемник. После сбоя канала [A, C], поскольку C не имеет альтернативного пути, он пометит маршрут как активный и отправит запрос каждому из своих соседей, запрашивая обновленную информацию о любом доступном пути к 100 :: / 64.
Когда D получает этот запрос, он проверяет свою таблицу локальной топологии и обнаруживает, что его лучший путь к 100 :: / 64 все еще доступен. Поскольку этот путь все еще существует, процесс EIGRP на D может предположить, что на текущий лучший путь через B не повлиял отказ канала [A, C]. D отвечает на этот запрос своей текущей метрикой, которая указывает, что этот путь все еще доступен и не имеет петель с точки зрения D.
Получив этот ответ, C заметит, что он не ждет ответа от других соседей (поскольку у него только один сосед, D). Поскольку C получил все ответы, которых он ожидает, он пересчитает доступные пути без петель, выбрав D в качестве преемника, а стоимость через D в качестве допустимого расстояния.
Что произойдет, если D никогда не ответит на запрос C? В более старых реализациях EIGRP C устанавливал таймер, называемый Stuck in Active Timer. Если D не отвечает на запрос C в течение этого времени, C объявит маршрут как Stuck in Active (SIA), и сбросит соседнюю смежность с помощью D. В новых реализациях EIGRP C установит таймер, называемый таймером запроса SIA (Query timer). Когда этот таймер истечет, он повторно отправит запрос к D. Пока D отвечает, что он все еще работает над ответом на запрос, C будет продолжать ждать ответа.
Где заканчиваются эти запросы? Как далеко будет распространяться запрос EIGRP в сети? Запросы EIGRP завершаются в одной из двух точек:
- Когда у маршрутизатора нет других соседей для отправки запросов;
- Когда маршрутизатор, получающий запрос, не имеет никакой информации о пункте назначения, на который ссылается запрос.
Это означает, что, либо на «конце сети EIGRP» (называемой автономной системой), либо на одном маршрутизаторе, за пределами какой-либо политики или конфигурации, скрывающей информацию о конкретных местах назначения. Например, один переход после точки, в которой маршрут агрегируется.
Диапазон запросов EIGRP и дизайн сети.
EIGRP всегда был известен как «протокол, который будет работать в любой сети» из-за его больших свойств масштабирования и очевидной способности работать в «любой» топологии без особой настройки. Однако основным фактором, определяющим масштабирование EIGRP, является диапазон запросов. Основная задача проектирования сети в сети EIGRP - ограничение объема запросов через сеть. Во-первых, диапазон запросов влияет на скорость схождения EIGRP: каждый дополнительный переход диапазона запроса добавляет небольшое количество времени к общему времени конвергенции сети (в большинстве случаев около 200 мс). Во-вторых, диапазон запросов влияет на стабильность сети. Чем дальше по сети должны проходить запросы, тем больше вероятность того, что какой-то маршрутизатор не сможет сразу ответить на запрос. Следовательно, наиболее важным моментом при проектировании сети на основе EIGRP в качестве протокола является ограничение запросов посредством агрегации или фильтрации определенного типа.
Обнаружение соседей и надежная передача.
EIGRP проверяет двустороннюю связь между соседями, канал MTU, и обеспечивает надежную передачу информации плоскости управления через сеть путем формирования отношений соседей. Рисунок 9 демонстрирует процесс формирования соседей EIGRP.
Шаги, показанные на рисунке 9, следующие:
- A отправляет многоадресное приветствие (multicast hello) по каналу, совместно используемому между A и B.
- B переводит A в состояние ожидания. Пока A находится в состоянии ожидания, B не будет отправлять стандартные обновления или запросы к A и не будет принимать ничего, кроме специально отформатированных обновлений от A.
- B передает пустое обновление с битом инициализации, установленным в A. Этот пакет отправляется на адрес одноадресного интерфейса A.
- При получении этого обновления A отвечает пустым обновлением с установленным битом инициализации и подтверждением. Этот пакет отправляется на адрес одноадресного интерфейса B.
- Получив это одноадресное обновление, B переводит A в состояние подключения и начинает отправлять обновления, содержащие отдельные записи таблицы топологии, в сторону A. В каждый пакет добавляется подтверждение для предыдущего пакета, полученного от соседа.
Поскольку EIGRP не формирует смежности с наборами соседей, а только с отдельными соседями, этот процесс обеспечивает доступность как одноадресной, так и многоадресной рассылки между двумя маршрутизаторами, образующими смежность. Чтобы гарантировать, что MTU не совпадает ни на одном конце канала, EIGRP заполняет определенный набор пакетов во время формирования соседа. Если эти пакеты не принимаются другим маршрутизатором, MTU не совпадает, и отношения соседства не должны формироваться.
Примечание. EIGRP отправляет многоадресные приветствия (multicast hellos) для обнаружения соседей по умолчанию, но будет использовать одноадресные приветствия, если соседи настроены вручную.
Подведение итогов – EIGRP.
EIGRP представляет ряд интересных решений проблем, с которыми сталкиваются протоколы маршрутизации при отправке информации по сети, вычислении путей без петель и реагировании на изменения топологии. EIGRP классифицируется как протокол вектора расстояния, использующий DUAL для вычисления путей без петель и альтернативных путей без петель через сеть. EIGRP объявляет маршруты без привязки к потокам трафика через сеть, поэтому это проактивный протокол.
Протоколы вектора расстояния и таблица маршрутизации.
В большинстве дискуссий о протоколах вектора расстояния- эти протоколы объясняются таким образом, что подразумевает, что они работают полностью отдельно от таблицы маршрутизации и любых других процессов маршрутизации, запущенных на устройстве. Однако это не так. Протоколы векторов расстояний взаимодействуют с таблицей маршрутизации не так, как протоколы состояния каналов. В частности, протокол вектора расстояния не объявляет маршрут к пункту назначения, который он не установил в локальной таблице маршрутизации.
Например, предположим, что EIGRP и RIP работают на одном маршрутизаторе. EIGRP узнает о некотором пункте назначения и устанавливает маршрут к этому пункту назначения в локальной таблице маршрутизации. RIP узнает о б этом же месте назначения и пытается установить маршрут, который он узнал, в локальную таблицу маршрутизации, но ему это не удается - маршрут EIGRP перезаписывает (или переопределяет) маршрут, полученный RIP. В этом случае RIP не будет анонсировать этот конкретный маршрут ни одному из своих соседей.
Для такого поведения есть две причины. Во-первых, маршрут, полученный через EIGRP, может указывать на совершенно другой следующий переход, чем маршрут, полученный через RIP. Если метрики установлены неправильно, два протокола могут образовать постоянную петлю пересылки в сети. Во-вторых, RIP не может узнать, насколько действителен маршрут EIGRP. Возможно, RIP объявляет маршрут, заставляя другие маршрутизаторы отправлять трафик локального устройства, предназначенный для объявленного пункта назначения, а затем локальное устройство фактически отбрасывает пакет, а не пересылает его. Это один из примеров black hole.
Чтобы предотвратить возникновение любой из этих ситуаций, протоколы вектора расстояния не будут объявлять маршруты, которых сам протокол не имеет в локальной таблице маршрутизации. Если маршрут протокола вектора расстояния будет перезаписан по какой-либо причине, он остановит объявление о доступности пункта назначения.
--
До встречи на нашей образовательной платформе.
Merion Academy - платформа доступного IT образования.