Данная статья является продолжением серии статей, которая началась здесь, развилась здесь и здесь, а здесь мы получили хороший прогноз. Но тут же было предупреждение, что здесь закралась ошибка. Сейчас пришло время разобраться, что мы делали неправильно. И делать это мы будем в предыдущем блокноте, немного модифицируя его. Если запутаетесь, то можно подглядеть здесь.
И начнем мы с оценки "правильности" модели, и делать это мы с помощью функции среднеквадратичной ошибки, а именно возьмем прогноз и сравним с фактическими данными, а результат возведем в квадрат, чтобы устранить знак ошибки. Подобные расчеты можно легко произвести вычисления средствами python, но чтобы не зависеть от качества алгоритма лучше взять эту функцию из библиотеки, например, такая функция есть в библиотеке sklearn:
from sklearn.metrics import mean_squared_error
Это еще одна форма импорта только определенной функции из определенной библиотеки. Теперь получим массив прогнозных данных:
pred = model.predict(typ='levels')
len(pred)
Вторая инструкция выводит нам количество элементов массива. Прошлый раз для того же самого мы использовали свойство shape, сейчас мы пошли другим путем, но результат один и тот же. Количество элементов нам нужно, чтобы сравнить с размером (количеством элементов) массива фактических цен. Количество прогнозов на 2 элемента меньше, чем количество цен. Так происходит потому, что для получения прогноза нам нужно два предыдущих значения. Таким образом первому прогнозному значению соответствует третья цена в нашем временном ряде, тогда среднеквадратичная ошибка вычисляется так:
mse = mean_squared_error(data[2:], pred, squared=True)
mse
Вывод последней инструкции: 0.21566641033775874. Много это или мало? Это значение ничего не означает до тех пор, пока вы не построите другие модели по этому же временному ряду, а вот тогда у вас будет что сравнивать. Тем более, что кроме ARIMA есть ARMA и AR. Все эти функции входят в семейство ARIMA. Если вам интересно узнать детали и различия этих моделей, то в интернетах вы легко найдете интересующую вас информацию.
model = sm.tsa.AR(data).fit()
pred = model.predict()
shft = len(data) - len(pred)
shft
Как видите функция AR проще. В третьей строчке вычисляем разницу размеров массива прогнозов с фактическими данными. Эту переменную мы и будем использовать как смещение.
mse = mean_squared_error(data[shft:], pred, squared=True)
mse
Эта функция оказалась не только проще, но и более точная, так как среднеквадратичная ошибка меньше - 0.20910848552464267. Проделаем те же действия с функцией ARMA:
model = sm.tsa.ARMA(data, order=(2, 1)).fit()
pred = model.predict()
shft = len(data) - len(pred)
mse = mean_squared_error(data[shft:], pred)
mse
Результат хуже всех - 0.3020488715042466. Таким образом, победителем нашего соревнования является AR. Кстати, вот вам домашнее задание: используя среднеквадратичную ошибку, подберите оптимальные параметры order в функции ARIMA. Это домашнее задание понадобится вам несколько позже, причем не его результаты, а сам принцип.
Ну ладно, нашли более лучшую модель, но в чем же ошибка? Это системная ошибка всех прогнозов, основывающихся на прошлых данных. Она заключается в том, что мы строим модель по данным, которые уже произошли. Но модели могут изменяться и даже умирать, а мы будем продолжать прогнозировать по старой модели. Поэтому прогнозы, сделанные по прошлым данным, должны подтверждаться тестами по данным, не входящим в модель.
Выглядит это следующим образом - выделяем блок данных для построения модели (такой блок называется тренировочная выборка), и выделяем блок для тестовых данных (тестовая выборка), построив модель на тренировочной выборке, проверяем его "правильность" на тестовой выборке и сравниваем его с результатом "правильности" на тренировочной выборке.
Как это будет выглядеть в нашем случае? Ну, например, так: до 2020 года у нас будет тренировочная выборка, а с 2020 года тестовая:
train = data[data.index < '2020-01-01']
test = data[data.index > '2020-01-01']
print('Всего выборка:', len(data))
print('Тренировочная выборка:', len(train))
print('Тестовая выборка:', len(test))
Я надеюсь, что вышеприведенный код будет понятен без объяснений. Вывод ячейки будет таков:
Всего выборка: 5323
Тренировочная выборка: 4867
Тестовая выборка: 456
Только вот использовать тренировочную модель на тестовых данных мы не сможем, так как модели временных рядов под это не заточены. Вывернуться можно, но нужно ли. То что мы хотим называется Machine Learning или ML.
Давайте подытожим. С помощью библиотеки statsmodels мы можем прогнозировать временные ряды, но не можем проверить модель на участке данных, которые не входят в модель, чтобы вовремя увидеть ошибки модели. Поэтому эту библиотеку следует использовать только на временных рядах с неизменной моделью, в анализе временных рядов есть понятие стационарности временного ряда. Здесь мы не будем давать определение этого понятия, описывать как его доказать или опровергнуть. Еще на этапе анализа графика мы видели, различие разных частей этого графика.
Для подтверждения разности значений мы можем построить гистограмму распределения значений. Если вы используете новый блокнот, то не забудьте подключить библиотеку matplotlib.pyplot.
data.hist(figsize=(24, 6), bins=100)
С параметром figsize мы уже сталкивались, а параметр bins задает количество градаций распределения. Давайте же посмотрим на вывод этой инструкции.
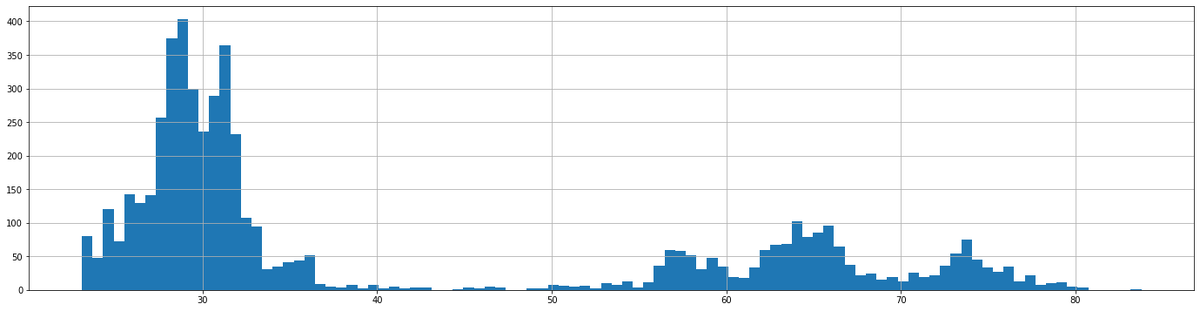
Мы видим большое скопление в районе 30 рублей и три поменьше. Сейчас цена находится в зоне крайнего правого скопления. Правильней было бы ограничить временной ряд участком, в котором цена находилась в последнем скоплении. Другой способ: изменить данные так, чтобы они потеряли текущую размерность, например, взять разность цены закрытия и открытия и поделить на максимум дня, и прогнозировать производную трех цен. Но мы с вами займемся машинным обучением, чтобы получить модель, работающую за пределами известных данных. Но это будет в другой статье.