Содержание
Функции
Все в той или иной мере понимают смысл функции. В широком смысле это просто определенное действие над чем-либо с неким результатом. Функция утюга - разглаживание складок на ткани. Функция рубанка - сделать примерно то же самое только с куском дерева. Кто не полностью забивал на уроки алгебры в школе представляют себе так же, что функция это некая математическая абстракция позволяющая сопоставить одну величину с какой-то другой. Тут важно понимать, что функция это не действие по отдельности. То есть разглаживание и разравнивание как действие не является функцией в строгом смысле. У функции есть еще и предмет действия и итоговый результат - строго определенный и однозначный. Даже если это некая вероятность, то она имеет свое строгое описание - ожидаемое значение и погрешность.
Алгоритм - это, строго говоря, тоже некая функция, будь то компьютерный, или в общем понимании этого слова. Можно рассматривать алгоритм как некое последовательное применение множества функций над входными данными. Отличие алгоритма от математической функции состоит в том, что алгоритм позволяет одновременно применять несколько функций и хранить отдельные результаты для последующего использования. Причем иногда последовательность может иметь строгий порядок, а иногда выполняться независимо друг от друга - параллельно. Если хотите это такой автомобильный конвейер где двигатель, кузов и шасси собираются отдельно и параллельно, но каждый из этих процессов имеет свою строгую последовательность. А в итоге все три части собираются во едино - в автомобиль. Так же алгоритмы могут получать несколько результатов одновременно. Например, результатом строгания доски как алгоритма, является не только гладкая доска, но и стружка.
В программировании понятие функции часто используется в понимании алгоритма - более широком чем функция математическая или оператор. Поэтому, говоря функция, программисты подразумевают обычно некую конструкцию на алгоритмическом языке, нежели чем y = f(x). Так и далее по тексту, что бы ни кого это не смущало, будем считать и то и другое понятия тождественными и использовать их в расширенном понимании - программа на алгоритмическом языке. Когда нужно будет ввести именно математическое определение об этом будет оговорено специально.
Среднее арифметическое и медиана
Применительно к задаче вычисления среднего арифметического и к эксельке мы имеем три разных по сути действия: вычисление суммы, подсчет количества слагаемых, и деление первого на второе. Давайте рассчитаем, набившую оскомину, среднюю зарплату россиянина. Пусть в ячейках с A1 по A12 будут средние зарплаты по разным профессиям: 26000; 27000; 23500; 17800; 32300; 24000; 27500; 20900; 25000; 24600; 24100; 248100. В ячейке C1 введем формулу '=СРЗНАЧ(A1:A12)'.
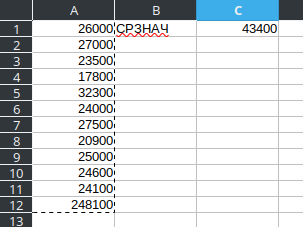
Кажется все элементарно, но что же сделала экселька на самом деле. Программа внутри себя имеет вшитый алгоритм для вычисления функции 'СРЗНАЧ'. Не вдаваясь в тонкости это буквально три подфункции:
- СУММ(A1:A12)
- СЧЁТ(A1:A12)
- СУММ(A1:A12)/СЧЁТ(A1:A12)
Первая из которых соответственно сама представляет из себя цикл. 'СЧЁТ' не является циклом и вычисляется чуть хитрее чем просто 12-1+1, но это технический нюанс, не будем его разбирать. Тот же самый результат можно получить и непосредственно перечисляя значения внутри формулы: '=СРЗНАЧ(26000; 27000; 23500; 17800; 32300; 24000; 27500; 20900; 25000; 24600; 24100; 248100)'. Тут уже 'СЧЁТ' кроме как циклом посчитать не получится.
Повторюсь в последний раз - это самая настоящая программа - компьютерный алгоритм, который пока за вас создает "на лету" и исполняет экселька. Если вы вдруг не знали, то исполнение можно даже отключить, если формул в книге очень много, и нет нужды пересчитывать их при каждом изменении входных данных. Возможно, походу дела, вам придется использовать этот нехитрый прием.
Все с формальной точки зрения выглядит окей. Однако, мы с вами понимаем, что с математикой, может быть, и все в порядке, но возникает некая социальная несправедливость. Что же это за среднее такое? Более справедливой оценкой средней зарплаты в таком случае часто применяется другая функция - 'МЕДИАНА'. Внутри медиана это еще чуть более сложное понятие. Если не лезть в строгие математические определения медиана - это вероятность того, какую зарплату вы встретите случайным образом опрашивая представителей этих 12 профессий. И, поскольку встретить случайным образом чиновника сложнее чем педагога или врача, то и получим более адекватное число.
Средняя зарплата выдаваемая Росстатом, конечно же вычисляется не так топорно, там все значительно сложнее, но что-то такое не очень корректное в ней, согласимся, есть. Впрочем, это лирическое отступление - мы здесь не для того чтобы давать оценку Росстату. Это такая попытка подвести читателя к понятию вероятности - к тому что многие, если не все, процессы и явления в окружающей реальности имеют на самом деле вероятностный характер. Конечно, мы не получаем на работе вероятную зарплату, а вполне определенную, однако, если вспомнить школьные оценки с "плюсами" и "минусами", то окажется, что оценивается наша деятельность с детства не совсем в точных количественных показателях. Зарплата и табель успеваемости это как-раз попытка заменить оценки "неуд" и "отлично" в конкретных числах.
Если кто-то забеспокоился о том, когда же настоящее программирование, то поясняю: сейчас происходит декомпозиция нашей мегазадачи на мелкие подзадачи, решая последовательность которых, мы в итоге движемся к решению изначальной. А декомпозиция это одна из основных частей программирования. В данном, конкретном, случае необходимо определиться с входными данными - с предметом, в отношении которого в дальнейшем будут применяться функции.
Вероятности и погрешности
Итак, в реальности нет ни каких определенных качеств и количеств. Запомним это. Вместе с тем, вспомним, что компьютер, а вместе с ним и экселька, умеет работать только с числами - математическими абстракциями, которых не существует в природе. Для того что бы, тем не менее, использовать компьютеры для решения реальных задач, да и не только компьютеры, но и весь математический аппарат, древние ученые придумали пренебрегать. Пренебрегают везде - в физике, химии, биологии, медицине и всем чем можно. Например, "лошадиная сила", как мы помним из курса школьной физики, равна силе, изменяющей за одну секунду скорость на один метр в секунду абсолютно черного и упругого сферического коня в вакууме массой один килограмм. Таким образом совершается магический прием, в котором объекты реального мира сводятся к каким-то идеальным абстрактным величинам, которые в свою очередь можно заменить числами. А какие-то детали, как запах коня или его настроение, не значащие или значащие не на столько, что могут исказить результат исследования - пренебрежимы - игнорируются.
Возвращаясь к оценкам заголовков статей, установим некий абстрактный диапазон значений. А именно сопоставим значения "че-то не очень", "интересненько" и "огонь" числам 1, 2, 3 соответственно. При этом пренебрежем промежуточными значениями типа "че-то не очень, но все-равно интересненько". Результатом нашего алгоритма будет одно из чисел 1, 2, 3 не важно что поступает извне.
Со входящими параметрами немного сложнее. У нас есть заголовок, и содержимое статьи. Кроме этого, поскольку мы намерены обучить компьютер ставить оценки, нам нужны исходные учебные данные с уже сопоставленным результатом. То есть имеем два набора параметров:
- Заголовок, текст, оценка по трехбалльной шкале - для обучения
- Заголовок, текст - для рабочей версии
Так же определимся с тем, что такое "заголовок" и "текст". Текстом назовем последовательность слов и знаков препинания русского языка длиной не превышающей, скажем, сто элементов. Как считать слова и обрезать статью придумаем потом. Заголовком же пусть будет такой же набор из слов и знаков, ограниченный десятью элементами. Отражает ли заголовок содержимое статьи или это два совершенно не связанных друг с другом набора вопрос интересный и значимый - им мы пренебречь не можем. Эта оценка нужна нам внутри процесса вычисления результата, потому что часть пар "заголовок - текст" необходимо будет отсеять и не включать в программу обучения. Рабочая же программа будет сразу отказываться пытаться проанализировать заголовки никак не отражающие суть статьи.
Погрешность, как явление, возникает в силу вероятностного характера оценки при помощи нашего будущего алгоритма. Для НС погрешность это отклонение результата от ожидаемого значения в обучающем наборе данных - далее будем называть его специальным лингвистическим термином - корпус или корпус текстов. Простыми словами, нейронка будет выдавать результат с определенной ошибкой, особенно на старте. Эту ошибку необходимо так же оценить количественно что бы использовать ее для корректировки процесса обучения. В науке об НС обычно используют обратное погрешности значение - точность решения. Говорят: "точность решения задачи превышает предъявляемое требование в 90%" - то есть вероятность ошибки - погрешность - не превышает 1/9.
Вопрос какое же требование предъявить к нашему алгоритму оставим открытым. Вообще обычно говорится о точности превышающей средний результат выдаваемый среднестатистическим человеком, ну или работником. Если нейронка справляется хуже чем средний школьник, то и пользы от нее по большому счету ноль. Однако, поскольку мы не можем достоверно оценить интерес к заголовку сколь-нибудь объективно, то и предъявлять какое-то строгое значение не корректно. Хотя попытку вычислить средний спрос, опять же приблизительно, сделаем.
Оценка точности
Как же правильно посчитать то, что выдает нейронка на испытательном наборе данных, что бы подкорректировать её работу? Предположим, у нас есть уже есть корпус текстов с их заголовками и проставленной средней оценкой согласно неким результатам опроса населения. Не обученная, случайным образом сгенерированная нейронка, по общим соображениям, должна нам выдавать такой же случайный результат с вероятностью равной 1/3 по каждому из возможных результатов.
Пока не будем мастерить собственно саму НС, а просто накидаем серию результатов испытаний, которую бы нам выдала такая сеть существуй она на самом деле. Поскольку из по одному результату судить будет сложно, возьмем наобум 12 разных вариантов входящих параметров и соответствующих им 12 результатов. В эксельке это делается при помощи функции 'СЛУЧМЕЖДУ'. Ею и воспользуемся: введем в A1 '=СЛУЧМЕЖДУ(1;3)' и потащим вниз заполняя ячейки до A12.
В столбце B проделаем то же самое, но на этот раз притворимся, что это настоящие оценки. Не факт, что реальные цифры будут распределены случайным образом, и более того, скорее всего не будут, но сейчас это не очень важно. Сейчас мы пробуем просто оценить нашу воображаемую нейронку на вшивость.
Если вы заметили, при каждом использовании формулы и пересчете ячеек случайное число будет случайно меняться. Что бы это не сбивало с толку, нужно скопировать набор и вставить в другой лист только значения. Это выделение, копирование, добавление или переход на новый лист, нажатие правой кнопкой мыши по первой ячейке и выбор подменю 'Вставить как'. Далее выбираете 'только значения' или 'текст' в разных эксельках по разному. Теперь работаем только с этим листом.
На таком простейшем наборе ошибка вычисляется элементарно E = y - y' (training error), где y - целевой результат, а y' - то что вывела нейронка. То есть C1=B1-A1. Тащим вниз или кликаем дважды по квадратику в углу. Ну и вычислим среднее.
Здесь, уже могло закрасться подозрение, что арифметическое среднее ошибки будет сильно прыгать от одного случая к другому. Может вполне получиться так, что вы сразу получите ноль - идеальный вариант. Но мы понимаем, что это просто совпадение. Больше того, чем больше будет вариантов, скажем 100, то можно убедиться, что это число будет стремиться именно к нулю. Поэтому, для оценки ошибки придумали более подходящий вариант E = (y - y')^2 - среднеквадратическое или стандартное отклонение. Теперь, если подставить формулу в столбец C, то увидим, что средняя ошибка всегда составляет что-то около 1.5 - что, собственно, мы и ожидаем увидеть, а именно случайное распределение.
Разминка перед тренировкой
Итого. Определены основные параметры задачи и выходные данные. Определена методика оценки результата. Мы знаем чем будем манипулировать и что хотим увидеть в результате. Осталось понять как. А вот ответ на этот вопрос если и не такой сложный, то, наверное, излишне перегруженный всякими оговорками и допущениями, а так же новыми понятиями, которые придется вводить и начинать оперировать ими на ходу. Поэтому нужно потренироваться немного самим, прежде чем начинать тренировать кого-то или что-то еще.
На данный момент мы умеем считать всякие средние значения. На их примере можно и размяться. Среднее арифметическое и медиана это вполне определенные и однозначные функции, результат которых можно получить вычисляя напрямую следуя конечному детерминированному алгоритму. Однако в жизни человек часто делает непроизвольную оценку чего-то среднего не прибегая к арифметике. Вот, к примеру, мы особо не задумываясь подозреваем, что публикуемая учеными средняя зарплата не совсем адекватно отражает действительность. Как мы это делаем? Мы не обладаем какими-то точными сведениями, не пользуемся результатами опросов, но все же подспудно имеем представление о том чем живет средний гражданин. В большей мере, наверное, относя к таковым себя лично и своих немногочисленных коллег, друзей и родных.
Почему бы не обучить нейронную сеть поступать ровно так же - примерно понимать что же это такое "среднее" и прикидывать? Дадим ей какое-то количество правильных ответов на поставленный вопрос. И посмотрим, насколько это возможно вообще научить машину пользоваться интуицией. Заодно введем и подробнее изучим основные понятия, которые нам понадобятся в дальнейшем в более сложной ситуации.
Добавим для этого сперва надежные исходные данные. Создадим новую книгу в эксельке и назовем её, скажем, "avg_temperature". Для удобства первый лист назовем 'input' для входных параметров и заполним его следующим образом. Пусть в первом и во втором столбцах по строкам будут номер и имена пациентов в больнице (я воспользовался https://planetcalc.ru/8678/), а в третьем и последующих столбцах - измерения утренней температуры тела пациентов - '=СЛУЧМЕЖДУ(36,4;40)'. Допустим, 12 пациентов за 10 дней.
Эталонные средние значения мы можем посчитать и по больнице, но все-таки адекватнее и практически осмыслена средняя температура одного пациента по дням. Хотя, в нашем примере это особенного значения не имеет, поскольку искомое значение ни как не зависит от контекста. Контекст, кстати, я взял намеренно отличным от предыдущих, что бы была возможность обобщить результаты - перед боем не обязательно разминаться с живым противником, можно поработать и с грушей.
Второй лист и третий лист будет содержать нейронную сеть непосредственно. Пока их нужно лишь поименовать 'weight' и 'sigma'. И последний лист будет нужен нам для анализа результатов - 'result'. А о том что такое веса (weight) и сигма-функция, она же сигмоида, она же функция активации (sigma), предлагаю поговорить в следующей части - нейробиологической.
Продолжение следует...