
Проблемы со сбором ссылок на нужном сайте?
Наличие пробелов в ссылке? Относительные ссылки ? Ссылки выводятся скриптом ? Скроллинг? Подгружаемый контент ? -не надо на это тратить свое время
Самый простой и оптимальный способ собрать ссылки.
Большинство готовых парсеров умеют работать с ссылками из текстового файла, а написать свой парсер под эти условия достаточно просто.
1. Как и где взять ссылки
Большинство сайтов имеют карту сайта - файл sitemap.xml
Найти его можно напрямую по ссылке site.ru/sitemap.xml, но лучше открыть файл по ссылке site.ru/robots.txt
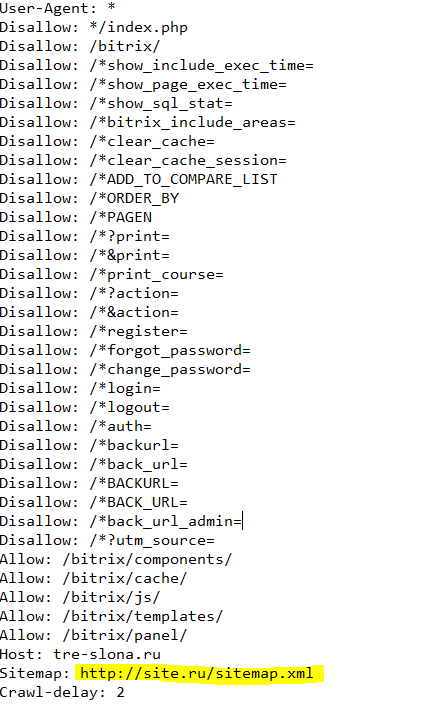
2. Переходим по ссылке
Откроется примерно такая страница
У больших сайтов в этом файле будут ссылки на другие sitemap.xml, потому что ограничение стандарта 50 000 ссылок и они просто не умещаются в одном файле.
Чтобы сохранить файл просто на странице открываем мышкой активируем меню и выбираем Сохранить как. Файл сохранится на компьютере.
3. Получаем ссылки на страницы.
Мы конечно не хотим писать маленький код на PYTHON, NET и других. Хотя это было бы полезным.
Нам нужны ссылки которые в файле выглядят так:
<loc>https://www.site.ru/tverskoi/generalynaya-prokuratura-rf-2.html</loc>
Для их получения можно использовать Excel, но если не умете , то нам нужен онлайн конвертер.
Скачиваем результат себе на компьютер
4. Создание файла links.txt
Открываем файл после конвертации в Excel
В Excel удаляем лишние столбцы и первую строку. Удаляем повторы ссылок . Затем фильтруем по алфавиту и удаляем ссылки которые не являются целевыми , например ведут на страницы с контактами , к разделам.
Если не знаете как из Excel сохранить в txt , то просто скопируйте столбец и вставьте в блокнот.
Заключение
На первый взгляд это может показаться сложно, но это быстрее чем искать и пробовать способы использую разные варианты кода и WebDriver. Также мы сразу избавляемся от возможных дублей ссылок и не придется думать об этом в коде и настройках. WebDriver так же замедляет скорость работы программы, чтобы его еще использовать и для сбора ссылок.