Разберемся в отличиях главных групповых преобразователей в Pandas. Так как ранее я неоднократно останавливался на описании работы с группами в Pandas, сосредоточим внимание только на принципиальном отличии методов transform и apply.
Рассмотрим данный вопрос на примере обработки записей DataFrame следующего вида:
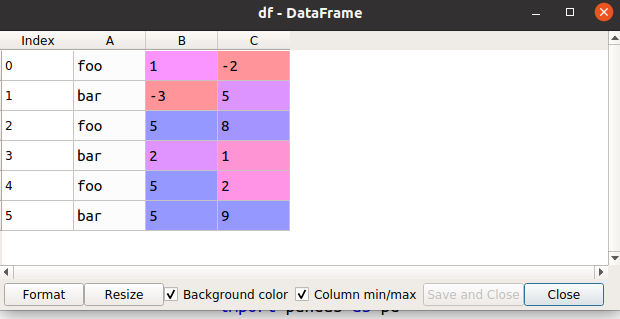
Для получения таблицы использовался сценарий:

Как можно заметить, в сценарии также задана функция f, которая будет применена к данным с помощью transform и apply.
Метод transform в вызываемой функции преобразует отдельные столбцы (Series) и для каждого должен возвращать Series с тем же индексом и заполненный трансформированными значениями. В противном случае поведение метода может стать непредсказуемым.
apply принципиально отличается тем, что работает на уровне всей таблицы (DataFrame). То есть при каждой итерации функция f будет получать на входе часть DataFrame, соответствующую группе (включая столбец группировки). Результаты при группировке по столбцу A похожи на приведенные выше:
Однако для более явной демонстрации разницы работы преобразователей видоизменим функцию f:
Сравните с неочевидностью порядка работы transform:
Как можно заметить, среди аргументов не только Series, но и целиком DataFrame объекты (3 и 6 шаг). Поэтому в вызываемой функции при обработке значений лучше за рамками стандартных способов использования transform не выходить.