Вспомним формулу Шеннона, которая описывает классическую информационную энтропию:
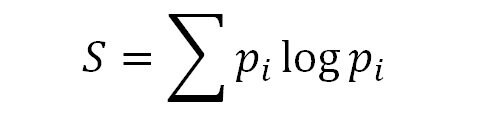
Возьмем систему, которая может с некоторой вероятностью быть в одном из двух состояний, то есть номер состояния которой пробегает значения i от 1 до 2. Тогда можно описать ее состояния в виде двух ортогональных векторов:
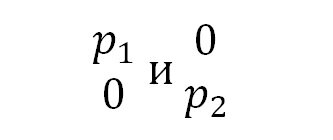
При этом р2=1-р1.
Каждый вектор можно умножить на самого себя декартовым произведением и получить при этом матрицу его плотности:
Сумма этих матриц будет:
Теперь формулу Шеннона можно записать вот так:
Tr – это след матрицы, т.е. сумма ее диагональных элементов.
Спрашивается, а зачем мы нагородили такую сложную запись, когда предыдущая запись была довольно простой и понятной?
Ответ – а затем, чтобы перейти к работе с квантовой информацией, поскольку квантовые состояния хорошо описываются матрицами плотности вероятности. Диагональная матрица плотности, которую мы видим - это матрица абсолютно смешанного состояния, т.е. состояния системы, в которой нет никакой когерентности (т.е. возможности интерференции волн вероятности). Таким образом, математически классическая статистическая смесь состояний и абсолютно смешанное квантовое состояние – это одно и то же. И энтропия абсолютно смешанного квантового состояния точно равна классической энтропии Шеннона.
Как это можно реализовать физически? Да очень просто – генерировать квантовые состояния прибором, который дает классическую вероятность приготовить систему в состоянии 1 или 2. Например, в хрестоматийном двухщелевом эксперименте это будет случайное закрытие щелей 1 и 2. Ну хорошо, а если мы щели не закрыли? Тогда у нас возникнет когерентное, чистое состояние I 1 › + I 2 › . И его матрица плотности будет вычисляться уже так:
Физически – в этом случае появится интерференция вероятностей, которая и даст не классическое распределение по двум щелям, а восхитительную интерференционную картину, которая будет даже в том случае, если излучать фотоны (или другие частицы) по одному, т.е. будет интерференция каждого фотона с самим собой.
Матрица плотности при этом будет не диагональной. Например, при вероятности пройти через одну щель (или получить спин вверх или вниз на приборе Штерна-Герлаха) ½ матрица плотности будет выглядеть так:
Чем интересна такая матрица чистого состояния? Тем, что ее логарифм равен нулевой матрице! Вычисление логарифма от матрицы – это довольно сложный процесс, основанный на изменении базиса для приведения к жордановой форме и последующем разложении в ряд Тейлора, а потом – возвращении к исходному базису, его я приводить здесь не буду. Но результат вычисления энтропии системы в чистом состоянии будет ошеломляющим:
Энтропия системы в чистом состоянии равна 0, то есть – информация, содержащаяся в системе, максимальна! Описывая систему в чистом состоянии, мы знаем о ней абсолютно все! Причем если мы знаем, что система эволюционирует унитарно, то мы знаем не только ее настоящее, но и прошлое, и будущее! Неравенство Шеннона для такой системы превращается в равенство, второй закон термодинамики для нее не писан.
А как же тогда мы все время наблюдаем проявления второго закона термодинамики, все время боремся с неравенством Шеннона? Откуда это берется? Ответ на это непрост, и для этого нам необходимо знать, как ведет себя энтропия при явлении квантовой запутанности. Об этом чуть позже.