В своих статьях мы уже неоднократно говорили о важности качестве используемых данных в машинном обучении. Неточности и погрешности могут привести к ошибкам, которые, как правило, вскрываются слишком поздно.
Учитывая сложность моделей глубокого обучения и увеличения их размеров, функций и наборов используемых данных, такие просчеты могут привести к снижению производительности, долгому процессу внесения правок и дополнительным финансовым издержкам.
Чтобы вы могли избежать такого сценария, LabelMe рассказывает про очень интересный масштабируемый метод оценки влияния отдельных объектов в данных на предсказания — TracIn.

Если не TracIn, то что?
Существует несколько методов количественной оценки влияния отдельных объектов в данных.
Некоторые п олагаются на изменение точности при повторном обучении с одной или несколькими отброшенными точками данных. Другие используют установленные статистические методы: функции влияния, которые оценивают воздействие входных точек, или методы репрезентатора, которые разделяют прогноз на взвешенную по важности комбинацию обучающих примеров.
Другие подходы строятся на использовании дополнительных оценщиков, таких как оценка данных с использованием обучения с подкреплением . Хотя эти подходы теоретически обоснованы, их использование в продуктах ограничено ресурсами, необходимыми для масштабного внедрения.
В статье « Оценка влияния обучающих данных путем отслеживания градиентного спуска », подготовленной сотрудниками Google, рассматривается предположение, что TracIn — самый оптимальный масштабируемый подход для решения этой проблемы.
Как устроен алгоритм TracIn
Его идея достаточно проста — отслеживать процесс обучения и фиксировать изменения в предсказаниях при переходе от одного объекта данных к другому. Таким образом, TracIn находит ошибки в разметке данных и выбросы. Кроме того, метод позволяет объяснять предсказания на примере объектов из обучающей выборки.
Алгоритмы глубокого обучения, как правило, базируется на использовании стохастического градиентного спуск а (SGD) и его аналогов. Они анализируют данные и вносят изменения в параметры модели, которые локально уменьшают несоответствия, противоречащие финальной цели модели.
В качестве примера возьмем задачу по классификации изображений. Задача модели — различать “кабачки”. По мере обучения алгоритм подвергается воздействию различных обучающих примеров. Они влияют на потери на тестовом изображении, где потери одновременно являются и функцией оценки прогноза, и фактического ярлыка. Чем выше оценка прогноза для цуккини, тем меньше потери.
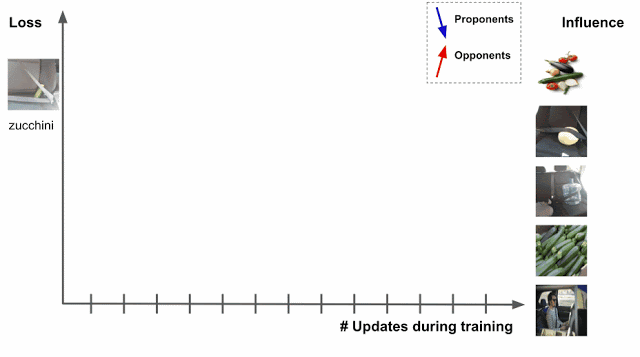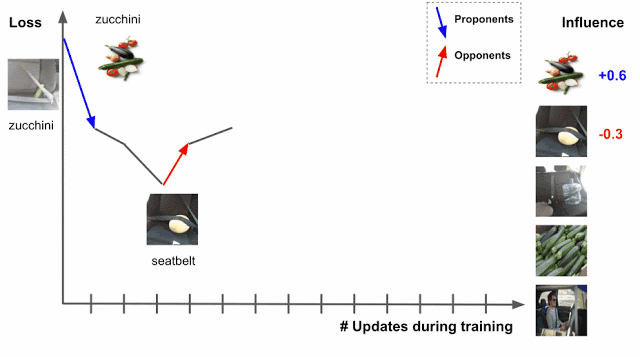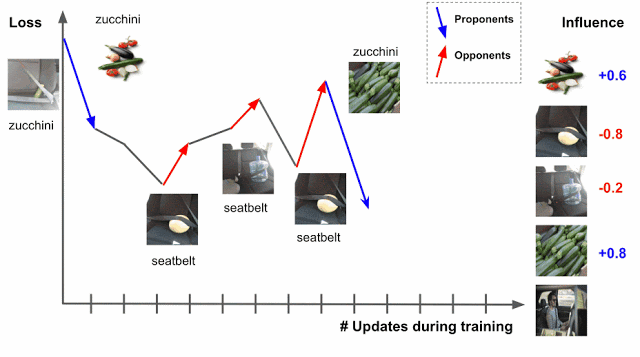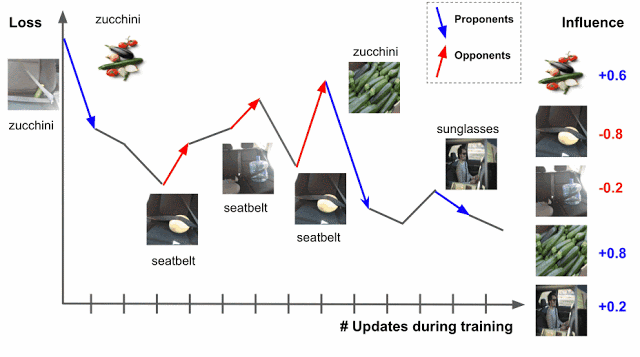
Если пример обучения известен в самом начале, то изменятся все параметры модели, что снизит количество ошибок. Алгоритм делит все данные на сторонников (proponents), которые уменьшают потери, и противников (opponents), которые увеличивают потери. В нашем примере явным противником являются ремни безопасности и заднике сиденья авто.
На практике первоначальный пример чаще всего неизвестен. Это ограничение можно преодолеть, используя контрольные точки, вводимые алгоритмом обучения в качестве набросков общего процесса. Второй нюанс — алгоритм обучения обычно обращается к нескольким точкам одновременно, а не по отдельности. Чтобы разобраться во вкладе каждого обучающего примера, можно ввести точечные градиенты ошибок.
TracIn решает оба этих нюанса, сводя все к форме скалярного произведения градиентов потерь тестовых и обучающих примеров.
Как происходит вычисление примеров
Сперва вычисляется вектор градиента потерь для некоторых обучающих данных и тестового примера по конкретной классификации. На примере ниже это хамелеон. Далее используется стандартная библиотека k-ближайших соседей для получения верхних значений: противников и сторонников.
Лучшие “противники” указывают на способность хамелеона сливаться. Поэтому мы также добавляем k- ближайших соседей с вложениями из предпоследнего слоя.
“Сторонники” — это изображения, которые не только похожи, но и принадлежат к одному классу, а противники — похожие изображения, но из другого класса. Обратите внимание, что нет явного принуждения к тому, принадлежат ли сторонники или противники к одному классу.
Как происходит кластеризация
Упрощенный способ разделения тестовых примеров для последующего обучения, предполагает, что предсказания любой нейронной модели, основанной на градиентом спуске, можно выразить как сумму сходств в пространстве градиентов. К тому же одно из недавних исследований доказало, что эта функциональная форма аналогична форме ядра . Следовательно, этот алгоритм может выполнять функции кластеризации.
Сперва необходимо ограничить метрику подобия, чтобы ее можно было преобразовать в меру расстояния (1 — подобие). Далее мы нормализуем векторы градиента, чтобы они имели единичную норму. Ниже мы пример кластеризации через TracIn к изображениям цуккини для получения более мелких кластеров.
Выявление выбросов с самовоздействием
Это необходимо для того, чтобы исключить примеры, оказывающие сильное влияние на процесс собственного обучения и прогнозов. Это происходит либо в случае неправильной маркировки примера, либо, если обобщение модели на примерах затруднено. Ниже приведем несколько примеров с высоким уровнем самовоздействия.
Заключение
TracIn — это простой, легко реализуемый и масштабируемый способ вычисления влияния примеров, обучающих данных по индивидуальным прогнозам или поиску редких и неправильно обозначенных обучающих примеров. Метод не требует использования стохастического градиентного спуска в модели. TraceIn адаптируем для любого набора данных и архитектуры нейросети.
Это делает его одним из самых юзабильных инструментов для специалистов в сфере Machine Learning. Чтобы узнать больше о способах применения и настройки TraceIn, советуем ознакомиться с полной версией статьи от специалистов Google.