Снова на моем канале Old Programmer . Тематическое оглавление его найдете здесь . А здесь все мои материалы о языке программирования Python.
Несколько полезных ссылок с моего канала
- Библиотеки языка программирования Python. Путеводитель по ресурсам канала Old Programmer
Сегодня интересный материал о том, как в принципе, можно анализировать ту информацию, который вы получаете в запросах к сайту с помощью известной уже нам библиотеки requests .
- Библиотека requests в Python. Обработка ошибок, подготовка к парсингу
- Использование библиотеки requests в Python для доступа к ресурсам Интернет
- Библиотека запросов requests для языка Python. Начало
Для анализа html страниц прямо напрашивается использовать регулярные выражения, которым я уже посвятил несколько статей.
- Python. Регулярные выражения (библиотека re). Статья 2
- Python. Регулярные выражения (библиотека re). Статья 3
Определения заголовка html-страницы
Рассмотрим не слишком сложную задачу: скачать страницу по указанному адресу и определить ее заголовок. Программа rgp4000.py спрашивает на входе url (url = input().strip()) и выводит заголовок страницы. При при этом страница сохраняется на диске под именем test.html, и может таким образом подвергаться дальнейшему анализу.
Для поиска используется функция из библиотеки re - findall(). Обращаю также внимание на параметр flags=re.I, означающий не чувствительность при поиске к регистрам букв. Замечу также, что заголовок страницы в общем случае может иметь вид
<title что-то еще>Заголовок</title>
поэтому для выделения самого заголовка мы и ищем первое вхождение '>'.
Парсинг web-страницы
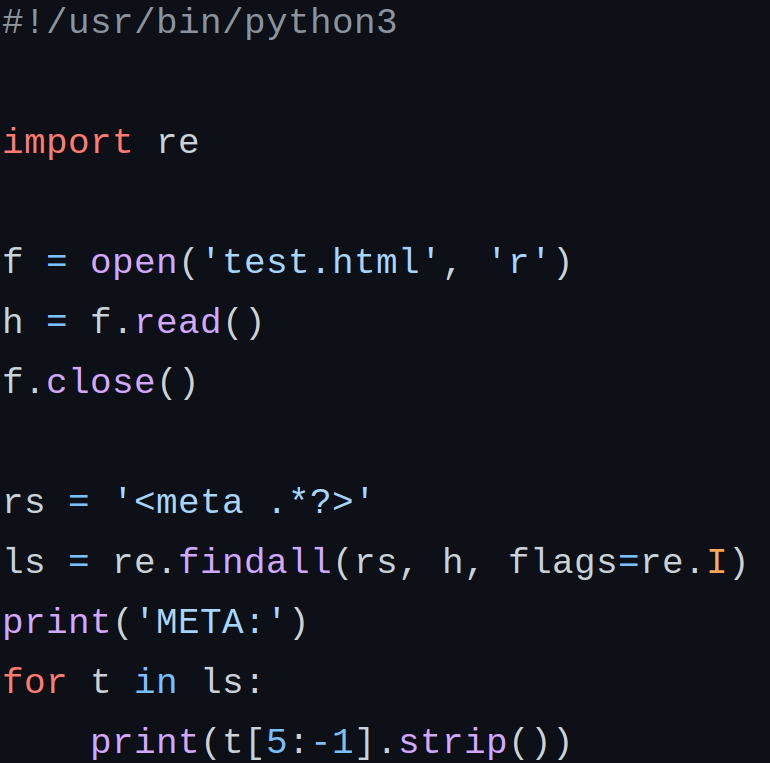
Вторая программа (rgp4001.py) анализирует уже сохраненную html-страницу test.html. Она выделяет из нее все meta-теги и выводит на консоль. Шаблон для поиска имеет вид <meta .*?>. Символ '?' нужен, чтобы осуществлять так называемый "ленивый" поиск. В противном случае два идущие друг за другом meta-тега могу оказаться в одном результате поиска ("жадный" поиск).
Ставим "ЛАЙКИ" и подписываемся на мой канал Old Programmer. До скорых встреч.