
Метод K-ближайших соседей – это алгоритм Машинного обучения (ML) , который используют для решения задач классификации и регрессии.
Алгоритм Контролируемого обучения (Supervised Learning), в отличие от Неконтролируемого (Unsupervised Learning), полагается на размеченные входные данные для получения соответствующего результата с новыми данными без ярлыков.
Представьте, что компьютер – это ребенок, а мы – это учителя. Обучая ребенка узнавать лошадь, мы покажем ему несколько разных картинок, причем на некоторых из них действительно изображены эти животные, а остальные могут быть изображениями чего угодно (кошек, собак и проч.). Когда мы видим лошадь, мы говорим «лошадь!», а когда видим другого зверя – «Нет, не лошадь!» Спустя какое-то количество изображений ребенок (компьютер) будет правильно в большинстве случаев узнавать парнокопытное на картинках. Это контролируемое Машинное обучение с целью классификации изображений по видам животных.
Задача классификации имеет дискретное значение на выходе. Например, «любит пиццу с ананасами» и «не любит пиццу с ананасами» дискретны. Здесь нет никакого промежуточного варианта:
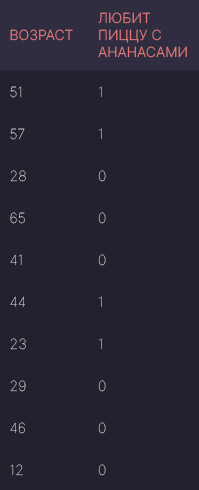
На изображении выше – базовый пример данных классификации. У нас есть Переменная-предиктор (Predictor Variable) "Возраст", или набор таковых, и репрезентативные метки 1 и 0. Мы попытаемся предсказать, любит ли человек пиццу с ананасами, используя его возраст.
Алгоритм kNN предполагает, что похожие Наблюдения (Observation), в данном случае потребители пиццы, существуют в непосредственной близости:
В большинстве случаев похожие наблюдения расположены близко друг к другу. kNN улавливает идею сходства (иногда называемого расстоянием, или близостью), благодаря, как правило, вычислению Евклидова расстояния (Euclidean Distance) между точками на графике.
Стандартная последовательность
- Загрузите данные
- Выберите число k, характеризующее количество соседей в кластере
- Вычислите Евклидово расстояние между всеми точками попарно. Отсортируйте получившийся набор расстояний от наименьшего к наибольшему. Затем выберите первые k записей из отсортированной коллекции.
- Для задач классификации определите Моду (Mode) – наиболее распространенную метку кластера.
Метод k-ближайших соседей и Scikit-learn
Для демонстрации работы метода используем специальный игрушечный датасет, который генерируется с помощью встроенного метода make_moons(). Для начала импортируем необходимые библиотеки:
Загрузим игрушечный датасет. make_moons() сгенерирует два перекрещивающихся полукруга на двумерном графике для демонстрации возможностей классификатора:
Конечно, луны – это метафора, выглядят эти пересекающиеся наборы точек примерно так:
Создадим и параметризируем двумерную сетку. Для этого определим минимальное и максимальное значение по осям x и y и добавим margin по краям, чтобы в зоне видимости оказались все наблюдения:
Отобразим график – "карту уверенности" с исходными точками "лун":
Мы получим контур, характеризующий степени уверенности алгоритма в принадлежности той или иной точки к сгенерированным группам (точки каждой группы как бы расположились в форме т.н. полулуний). Обратите внимание на тестовые маркеры с точками в центре: модель не всегда классифицирует их верно; попадаются те, что со 100%-й уверенностью алгоритм отнес к неверной группе, поскольку располагаются они далеко, на самой темно-зеленой части графика:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь .