У «Яндекс.Дзен» только простой редактор с минимальным функционалом, но даже он может многое. Например, поддерживает Юникод, позволяющий отобразить знаки практически всех письменных языков мира, математические, химические и другие спецсимволы, ударения и диакритические знаки.
Благодаря Юникоду (Unicode) возможно корректное отображение букв и знаков пунктуации из различных языков на одной странице. Он очень удобен: пользователи смогут читать вашем статьи в блоге на Дзене по всему миру, и на каждом компьютере и смартфоне с поддержкой Юникода тексты будет показываться точно так, как вы задумали, на любом языке с диакритическими знаками или иероглифическим письмом.
История Юникода

В 1950-х годах компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя или государства и занимали целые специально построенные здания. Каждая фирма и конструкторское бюро разрабатывало свою собственную модель, которая создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации. В этот период начинают формироваться первые компьютерные сети, соединяющие в себе несколько компьютеров. Тогда и встал вопрос об унификации сигналов и информационных символов, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
Первую крупномасштабную компьютерную сеть SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады, создали в 1958 году, а в 1962 году компания IBM сформирует два главных принципа для развития собственной линейки компьютеров:
- Компьютеры должны стать универсальными. Переход от производства узкоспециализированных компьютеров к машинам, которые могут решать разные задачи.
- Компьютеры должны стать совместимыми друг с другом, то есть должна быть возможность объединять несколько компьютеров в сеть и использовать данные с одного компьютера на другом.
И в 1964 году появились линейка моделей IBM System/360. Впервые была создана линейка компьютеров, от малых к бо́льшим, от низкой к высокой производительности, все модели которой использовали один и тот же набор команд. Компьютеры состояли из совместимых модулей, которые различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Эта особенность позволяла приобрести недорогую модель, после чего с ростом компании обновиться до более крупной системы, без необходимости переписывать программное обеспечение.
Такое решение привело к появлению огромной новой отрасли по производству IBM-совместимых компьютеров и комплектующих. Архитектура IBM/360 была настолько удачной, что стала де-факто промышленным стандартом вплоть до сегодняшнего дня, многие другие фирмы стали выпускать совместимые с компьютеры. IBM System/360 поставлялись и в СССР, где стали выпускать аналогичные компьютеры — машины серии ЕС ЭВМ.
Позже, с развитием элементной базы микроэлектроники в 70-х годах (кстати, первая ламповая микросборка появилась ещё в 30-х), компьютер стал умещаться на столе и в начале 80-х годов появилась модель XT линейки IBM PC, унаследовавшая концепцию архитектуры IBM System/360. Всё это привело к больше́му распространению компьютеров в мире. Эти строки я пишу спустя 40 лет на дальнем потомке линейки IBM PC, персональном компьютере, собранном в современной России из китайских комплектующих.
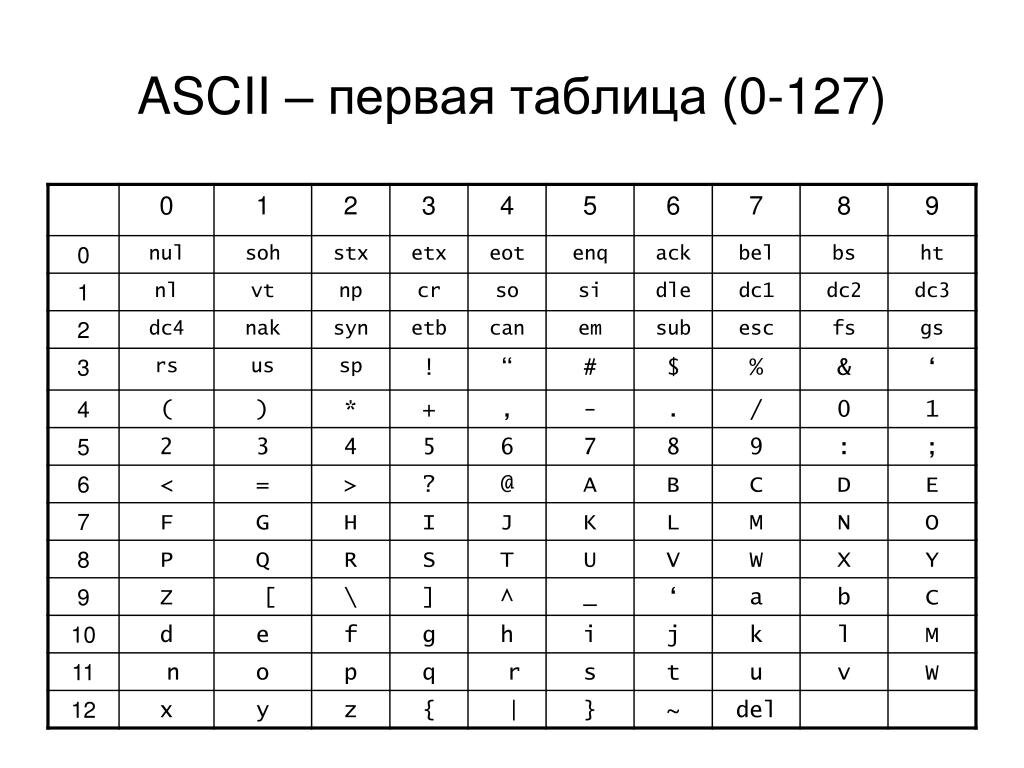
Компьютеризация и развитие средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American Standard Code for Information Interchange (Американский стандарт кодов для обмена информацией).
Были разработаны языки программирования, позволившие перенос программ в исходных кодах на компьютеры с совершенно другой архитектурой. В 90-х годах я программировал задания на компьютере Robotron и приносил распечатки в МТУСИ, где набивал их на XT. Позже нас перевели в компьютерный класс с 486SX2 с 4 мегами оперативки, где крутилась Windows 95 и новейший интерпретатор Delphi 2.0.
Шрифты и кодовые таблицы
Символы на экране вашего компьютера и смартфона формируются на основе наборов векторных форм (глифов) всевозможных знаков разных начертаний, которые находятся в файлах со шрифтами, которые установлены на вашем компьютере и кода, который позволяет найти в файле шрифта именно тот символ, который нужно будет вставить в текст. За векторные формы отвечают шрифты, а за кодирование символов — операционная система и используемые в ней программы.
Программа, отображающая этот текст на экране (ОС, текстовый редактор, браузер), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Для того, чтобы закодировать любой нужный нам символ, должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт.
ASCII базовая компьютерная кодировка текста для латиницы. Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания. Еще в ASCII попадали некоторые служебные символы — скобки, решетки, звездочки и т.п. С помощью одного байта информации можно закодировать не 128, а 256 различных значений (2⁸ = 256), поэтому вслед за базовой версией появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки, это и были кодовые страницы.
К концу 1980-х годов стандартом для компьютеров стали 8-битные кодировки, которых было множество, и постоянно появлялись новые. Это объяснялось расширением круга поддерживаемых языков и стремлением создавать кодировки, частично совместимые между собой. Например, в нашей стране применялись несколько альтернативных кодировок для русского языка, обусловленных эксплуатацией западных программ, созданных для кодировки IBM CP437. Был ещё и транслит — запись текста с помощью латинского алфавита, также могли применяться цифры и иные доступные на клавиатуре компьютера знаки (СМСки и сейчас так отправляют).
Первой появилась расширенная версия ASCII — кодировка CP866 (DOS), в которой была возможность использовать символы русского алфавита, её начало полностью совпадает с базовой версией (128 символов латиницы), а последующие 128 знаков позволяли закодировать символы кириллицы и псевдографику. Ей на смену пришла CP1251 из Windows 95. В кодировке IBM CP866 много псевдографики, тут дело в том, что эта кодировка разрабатывалась для консольных текстовых операционных систем, в те годы, когда ещё не было графических операционок. Псевдографика позволяла разнообразить оформление текстов и рисовать таблицы.
Кодировка КОИ8 появилась в 1974, её название означает «Код обмена информацией, 8 бит», а модификацию KOI8-R для интернет-браузеров была разработана в 1993 году. Кодировку создали из фонетической версии латиницы, в результате русские кириллические буквы расположены в псевдолатинском порядке, а не в обычном кириллическом алфавитном, у них и другой регистр. Русские буквы расположены в тех же ячейках кодовой таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (2⁷ = 128).
Из-за обилия кодировок появилось несколько проблем: неправильная раскодировка текстов, ограниченность набора символов, преобразование одной кодировки в другую и дублирования шрифтов. Например, из-за неправильной раскодировки в документе появлялись буквы иностранных языков или псевдографические символы, прозванных русскоязычными пользователями «кракозябрами». При попытке копирования текстов в другую систему все нестандартные символы превращались в «кракозябры». Проблема существует до сих пор. Решить её можно либо последовательным внедрением стандарта указания кодировки, либо внедрением общей для всех языков кодировки, которой и стал Юникод.
Для каждой кодировки приходилось создавался свой шрифт, даже если наборы символов в кодировках совпадали частично или полностью, и получалось дублирование символов в шрифтах. Проблему обходили путём создания больших шрифтов с множеством кодовых страниц, из которых впоследствии выбирались бы нужные для данной кодировки символы. Именно поэтому шрифты Юникода такие объёмные.
Юникод был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium). В документах, закодированных Юникодом, могут соседствовать математические символы, буквы греческого алфавита, кириллицы и латиницы, символы музыкальной нотной нотации, японские иероглифы. И это — без ненужного переключение кодовых страниц как в ранних версиях операционных систем компьютеров и программах с 8-битными кодировками, такими как ASCII. В Windows Юникод появился в 2000 году.
В настоящее время универсальная кодировка UTF (16-битный Юникод) является преобладающей в Интернете и продолжает развиваться, уже сейчас в ней более 100 тысяч символов. Кроме букв и цифр, в Юникоде есть и множество других символов и иконок. В последних версиях кодировки в их число вошли смайлики и эмодзи, которые вы можете видеть в месседжерах.
Стандарт Юникода состоит из двух основных частей: универсального набора символов и семейства кодировок. Каждому символу кодировки ставится в соответствие код, уникальный для данного символа (кодовая точка). Это значение является частью таблицы отображения символов Юникода, содержимое которой находится под контролем «Консорциум Юникода». Кодовые точки состоят из префикса U+ (или обратной косой черты \), за которым следует шестнадцатеричный код символа.
Семейство кодировок определяет способы преобразования кодов символов для передачи в потоке или в файле. Комбинированные символы (например, Ä) могут разбиваться на компоненты (A с умляутом), а затем снова соединяться в своё исходное состояние. Т.е. символ Ä состоит из кодовых точек U+0041 (A) и U+0308 (умляут).
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Шрифты Юникод прямо совместимы со старыми (первые 128 символов). Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400.
Тексты на китайском, корейском и японском языках имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Переключение горизонтального и вертикального написания для этих языков в Юникоде не предусмотрено. Наличие или отсутствие в Юникоде разных начертаний одного и того же символа в зависимости от языка. Нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку. Китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханча), но в Юникоде они обозначаются одним и тем же символом (CJK-унификация), хотя упрощённые и полные иероглифы имеют разные коды.
Для ввода на компьютере текста на других языках используйте виртуальные клавиатуры с разными раскладками символов (как на телефонах, смартфонах и других умных устройствах на операционной системе Android (Linux)). В самом Линуксе есть утилита «Таблица символов», позволяющая отображать символы определённой системы письма или через консоль введите символ Юникода по его десятичному коду цифрами расширенного блока клавиатуры при зажатой клавише Alt.
В восточных языках с иероглифическим письмом используют десятки тысяч иероглифов. Поэтому, в текстах на китайском, корейском и японском языках иероглифы вводиться на виртуальной клавиатуре через ромадзи (транскрипцию на латинице). Например, печатаете японское слово на хирагане (одна из двух слоговых азбук), после нажимаете «пробел» и программа выдаёт варианты написания кандзи (иероглифами).
Для смартфона есть способ проще. Открываете виртуальную клавиатуру, при нажатии на кнопку с тремя точками появляется кнопка «Перевод». Нажимаем на эту кнопку и всё! Перевод осуществляется Google в автоматическом режиме, пишите любом языке. Но автоматическом перевод часто вызывает смех из-за многозначности слов.
Вставка в текст ударе́ния, диакритических, математических, химических и других спецсимволов
В операционной системе Windows нажмите «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов» (или, например, «Панель математического ввода»). В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Скопируйте их, и через буфер обмена вставьте нужный символ в текст.
Вставка символов Юникода в Word возможна тремя разными способами, они актуальны для любой версии программы. Поддержка Юникода впервые появилась в Office 2000.
Внимание! Проверка орфографии в Word не пропускает слова с ударением и подчеркивает их красной волнистой линией, считая написанными с ошибками. Для того, чтобы не выдавалась ошибка при вставке диакритических знаков и слов на других языках, измените язык документа на язык вводимого слова. Символы Юникода вставляются нормально, без ошибок, на них проверка не ругается.
Способ 1: Комбинация на клавиатуре
Самый простой вариант для вставки, например для написания буквы с ударением – комбинация клавиш Alt+X. Поставьте курсор после буквы, на которой будет делаться ударение, слитно с ней напишите цифры «301» (код символа прямого ударения в Юникоде) и нажмите комбинацию кнопок Alt+X. После нажатия число «301» пропадёт и на нужной букве появится знак ударения. Всё получилось! В редакторах Alt+X выполняет и обратное преобразование.
Если вам нужно обра̀тное ударение используйте числовой код «300» (ударение с наклоном влево). Для вставки диакритических знаков, например умляутов, используйте латинскую букву и код 308. Можно также вставить буквы из расширенной латиницы.
Способ 2: Через клавишу Alt и цифровую клавиатуру
Нажмите клавишу Num Lock и включите дополнительную клавиатуру (внимание, она есть только у персонального компьютера, на ноутбуке таких клавиш нет) расположенную справа. Загорится зеленый световой индикатор в углу клавиатуры (см. рисунок выше). Вводите слово и прервитесь после написания нужной буквы (курсор мигает около ударной буквы).
Далее зажимаем клавишу Alt и не отпуская её вводим число «769» (десятичное значение кода символа в Юникоде) с помощью дополнительной цифровой клавиатуры (это действует во многих программах Windows). Верхний ряд цифр на клавиатуре, который находится над буквами, не сработает. После того как ввели число «769», отпускаем Alt и видим слово с правильным ударением. Выключаем дополнительную клавиатуру, индикатор в углу клавиатуры гаснет.
Способ 3: Через меню «Символы»
Это несколько более сложный способ. Поставьте курсор после буквы, на которую будет падать ударение. Перейдите в меню Word на вкладку «Вставка», подменю «Символы» нажмите кнопку «Символ» и выберите пункт «Другие символы».
В Word 2000, XP и 2003 нажмите «Вставка» и в выпадающем меню выберите «Символ». Далее полностью повторяйте действия для более новых версий Word. В открывшемся окне выберите набор символов «Объединённые диакритические знаки», после чего необходимо нажать на необходимый знак ударения или другой спецсимвол и завершите вставку кнопкой «Вставить». Если вы уже использовали знак ранее, он появится в быстром доступе на панели «Другие символы».
Подробнее об оформлении текстов читайте в следующей статье.
О статьях на этом канале
Данная статья уже 8 в серии «Что нужно знать про Дзен». Предыдущие статьи:
- Что нужно знать про Дзен. История Юникода. Как поставить ударение над буквой и вставить символы в блог и Word
Читайте также статью «Об этом канале», и серию о лотереях — «Улыбка удачи и история игр. Бывает ли большой выигрыш в лотереях? Личный опыт игры в «Столото»» и «Улыбка удачи или оскал фортуны? Психологические аспекты зависимости от игр», которую я скоро продолжу.
Следите за публикациями. Если вам понравился материал, пожалуйста, поддержите лайком и подпишитесь на канал :-)